 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Methodological Advances in Federated Learning for Healthcare
Oct 04, 2023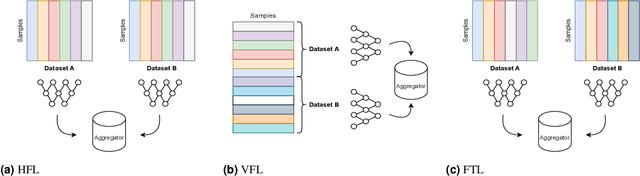
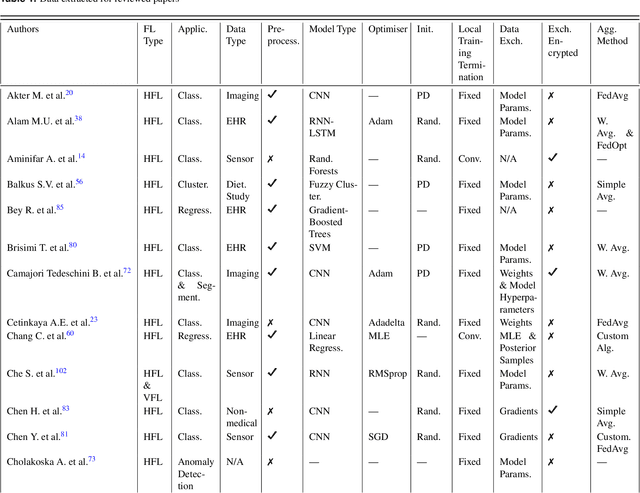
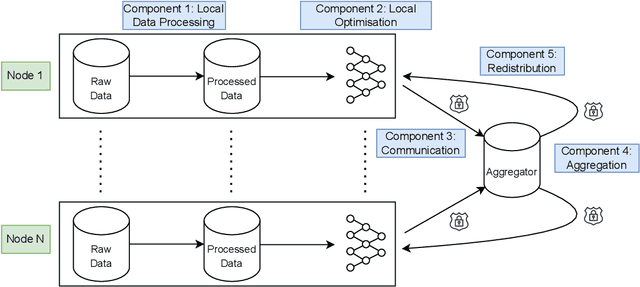
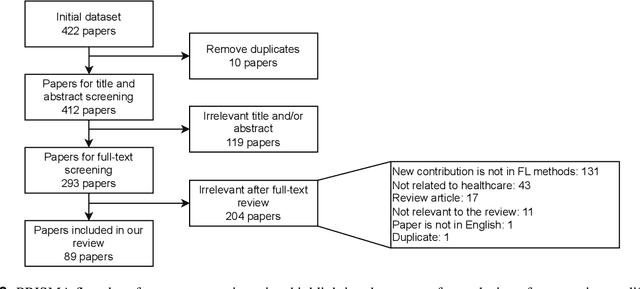
For healthcare datasets, it is often not possible to combine data samples from multiple sites due to ethical, privacy or logistical concerns. Federated learning allows for the utilisation of powerful machine learning algorithms without requiring the pooling of data. Healthcare data has many simultaneous challenges which require new methodologies to address, such as highly-siloed data, class imbalance, missing data, distribution shifts and non-standardised variables. Federated learning adds significant methodological complexity to conventional centralised machine learning, requiring distributed optimisation, communication between nodes, aggregation of models and redistribution of models. In this systematic review, we consider all papers on Scopus that were published between January 2015 and February 2023 and which describe new federated learning methodologies for addressing challenges with healthcare data. We performed a detailed review of the 89 papers which fulfilled these criteria. Significant systemic issues were identified throughout the literature which compromise the methodologies in many of the papers reviewed. We give detailed recommendations to help improve the quality of the methodology development for federated learning in healthcare.
Classification of datasets with imputed missing values: does imputation quality matter?
Jun 16, 2022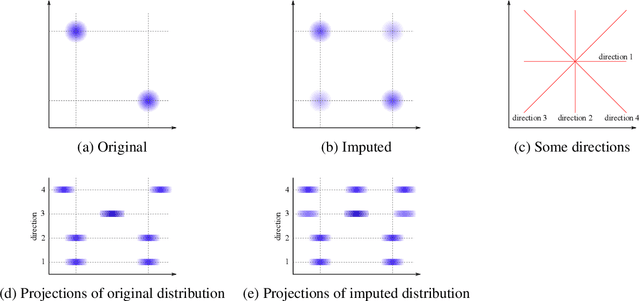


Classifying samples in incomplete datasets is a common aim for machine learning practitioners, but is non-trivial. Missing data is found in most real-world datasets and these missing values are typically imputed using established methods, followed by classification of the now complete, imputed, samples. The focus of the machine learning researcher is then to optimise the downstream classification performance. In this study, we highlight that it is imperative to consider the quality of the imputation. We demonstrate how the commonly used measures for assessing quality are flawed and propose a new class of discrepancy scores which focus on how well the method recreates the overall distribution of the data. To conclude, we highlight the compromised interpretability of classifier models trained using poorly imputed data.