 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Generative Classification of Blood Cell Morphology
Aug 16, 2024



Accurate classification of haematological cells is critical for diagnosing blood disorders, but presents significant challenges for machine automation owing to the complexity of cell morphology, heterogeneities of biological, pathological, and imaging characteristics, and the imbalance of cell type frequencies. We introduce CytoDiffusion, a diffusion-based classifier that effectively models blood cell morphology, combining accurate classification with robust anomaly detection, resistance to distributional shifts, interpretability, data efficiency, and superhuman uncertainty quantification. Our approach outperforms state-of-the-art discriminative models in anomaly detection (AUC 0.976 vs. 0.919), resistance to domain shifts (85.85% vs. 74.38% balanced accuracy), and performance in low-data regimes (95.88% vs. 94.95% balanced accuracy). Notably, our model generates synthetic blood cell images that are nearly indistinguishable from real images, as demonstrated by a Turing test in which expert haematologists achieved only 52.3% accuracy (95% CI: [50.5%, 54.2%]). Furthermore, we enhance model explainability through the generation of directly interpretable counterfactual heatmaps. Our comprehensive evaluation framework, encompassing these multiple performance dimensions, establishes a new benchmark for medical image analysis in haematology, ultimately enabling improved diagnostic accuracy in clinical settings. Our code is available at https://github.com/Deltadahl/CytoDiffusion.
Dis-AE: Multi-domain & Multi-task Generalisation on Real-World Clinical Data
Jun 15, 2023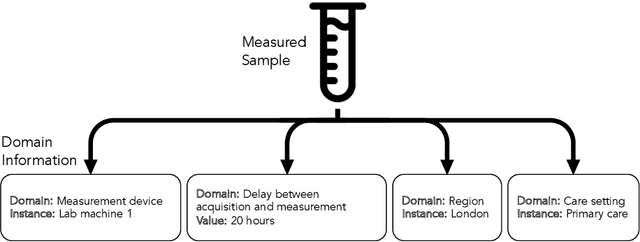
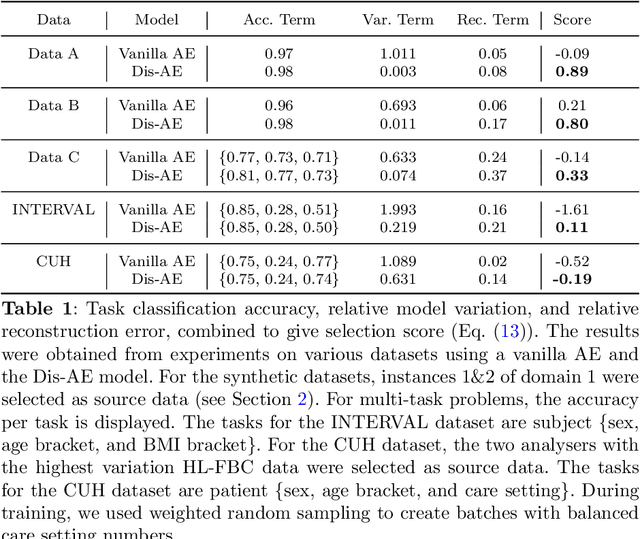
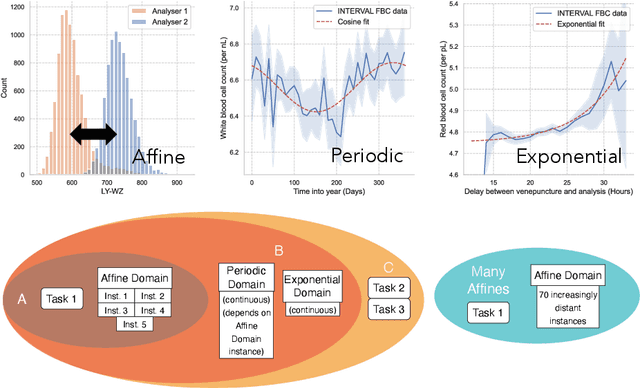
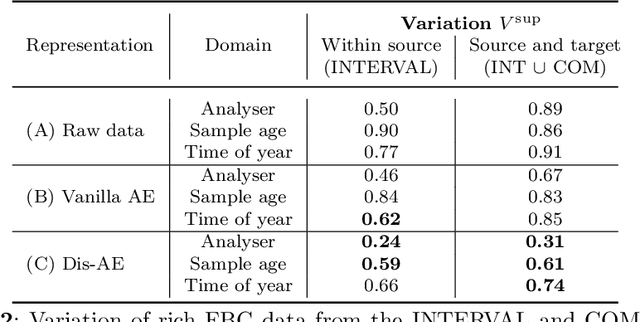
Clinical data is often affected by clinically irrelevant factors such as discrepancies between measurement devices or differing processing methods between sites. In the field of machine learning (ML), these factors are known as domains and the distribution differences they cause in the data are known as domain shifts. ML models trained using data from one domain often perform poorly when applied to data from another domain, potentially leading to wrong predictions. As such, developing machine learning models that can generalise well across multiple domains is a challenging yet essential task in the successful application of ML in clinical practice. In this paper, we propose a novel disentangled autoencoder (Dis-AE) neural network architecture that can learn domain-invariant data representations for multi-label classification of medical measurements even when the data is influenced by multiple interacting domain shifts at once. The model utilises adversarial training to produce data representations from which the domain can no longer be determined. We evaluate the model's domain generalisation capabilities on synthetic datasets and full blood count (FBC) data from blood donors as well as primary and secondary care patients, showing that Dis-AE improves model generalisation on multiple domains simultaneously while preserving clinically relevant information.
Classification of datasets with imputed missing values: does imputation quality matter?
Jun 16, 2022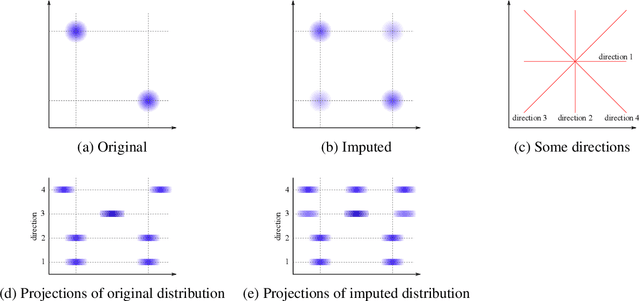


Classifying samples in incomplete datasets is a common aim for machine learning practitioners, but is non-trivial. Missing data is found in most real-world datasets and these missing values are typically imputed using established methods, followed by classification of the now complete, imputed, samples. The focus of the machine learning researcher is then to optimise the downstream classification performance. In this study, we highlight that it is imperative to consider the quality of the imputation. We demonstrate how the commonly used measures for assessing quality are flawed and propose a new class of discrepancy scores which focus on how well the method recreates the overall distribution of the data. To conclude, we highlight the compromised interpretability of classifier models trained using poorly imputed data.
Machine learning for COVID-19 detection and prognostication using chest radiographs and CT scans: a systematic methodological review
Sep 01, 2020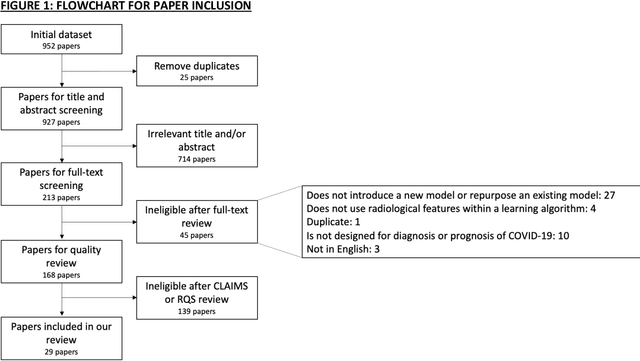
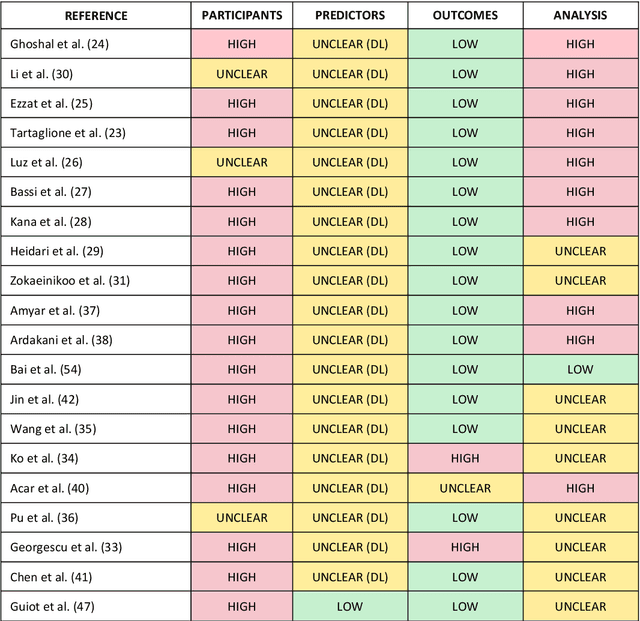
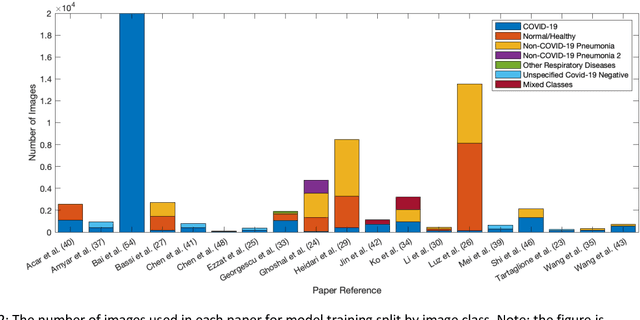
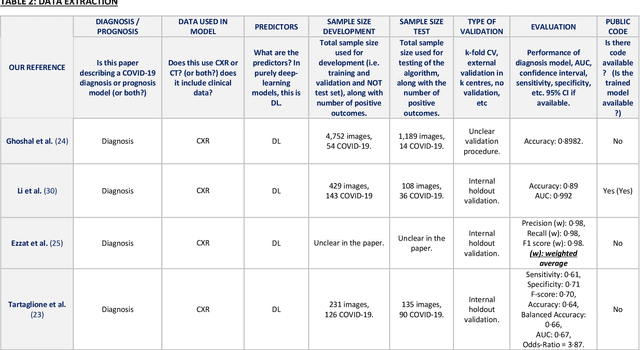
Background: Machine learning methods offer great potential for fast and accurate detection and prognostication of COVID-19 from standard-of-care chest radiographs (CXR) and computed tomography (CT) images. In this systematic review we critically evaluate the machine learning methodologies employed in the rapidly growing literature. Methods: In this systematic review we reviewed EMBASE via OVID, MEDLINE via PubMed, bioRxiv, medRxiv and arXiv for published papers and preprints uploaded from Jan 1, 2020 to June 24, 2020. Studies which consider machine learning models for the diagnosis or prognosis of COVID-19 from CXR or CT images were included. A methodology quality review of each paper was performed against established benchmarks to ensure the review focusses only on high-quality reproducible papers. This study is registered with PROSPERO [CRD42020188887]. Interpretation: Our review finds that none of the developed models discussed are of potential clinical use due to methodological flaws and underlying biases. This is a major weakness, given the urgency with which validated COVID-19 models are needed. Typically, we find that the documentation of a model's development is not sufficient to make the results reproducible and therefore of 168 candidate papers only 29 are deemed to be reproducible and subsequently considered in this review. We therefore encourage authors to use established machine learning checklists to ensure sufficient documentation is made available, and to follow the PROBAST (prediction model risk of bias assessment tool) framework to determine the underlying biases in their model development process and to mitigate these where possible. This is key to safe clinical implementation which is urgently needed.