 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deterministic End-to-end Latency for Medical AI Systems in NVIDIA Holoscan
Paper and Code
Feb 06, 2024
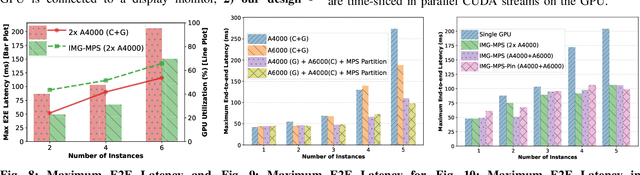


The introduction of AI and ML technologies into medical devices has revolutionized healthcare diagnostics and treatments. Medical device manufacturers are keen to maximize the advantages afforded by AI and ML by consolidating multiple applications onto a single platform. However, concurrent execution of several AI applications, each with its own visualization components, leads to unpredictable end-to-end latency, primarily due to GPU resource contentions. To mitigate this, manufacturers typically deploy separate workstations for distinct AI applications, thereby increasing financial, energy, and maintenance costs. This paper addresses these challenges within the context of NVIDIA's Holoscan platform, a real-time AI system for streaming sensor data and images. We propose a system design optimized for heterogeneous GPU workloads, encompassing both compute and graphics tasks. Our design leverages CUDA MPS for spatial partitioning of compute workloads and isolates compute and graphics processing onto separate GPUs. We demonstrate significant performance improvements across various end-to-end latency determinism metrics through empirical evaluation with real-world Holoscan medical device applications. For instance, the proposed design reduces maximum latency by 21-30% and improves latency distribution flatness by 17-25% for up to five concurrent endoscopy tool tracking AI applications, compared to a single-GPU baseline. Against a default multi-GPU setup, our optimizations decrease maximum latency by 35% for up to six concurrent applications by improving GPU utilization by 42%. This paper provides clear design insights for AI applications in the edge-computing domain including medical systems, where performance predictability of concurrent and heterogeneous GPU workloads is a critical requirement.