 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical sentiment analysis performance in Opinum
Paper and Code
Mar 03, 2013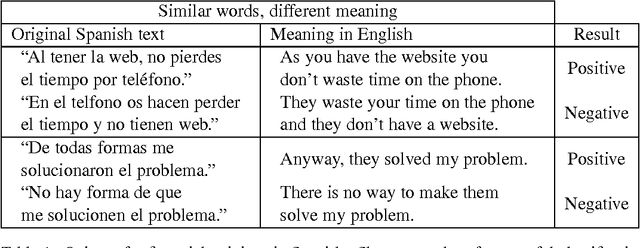
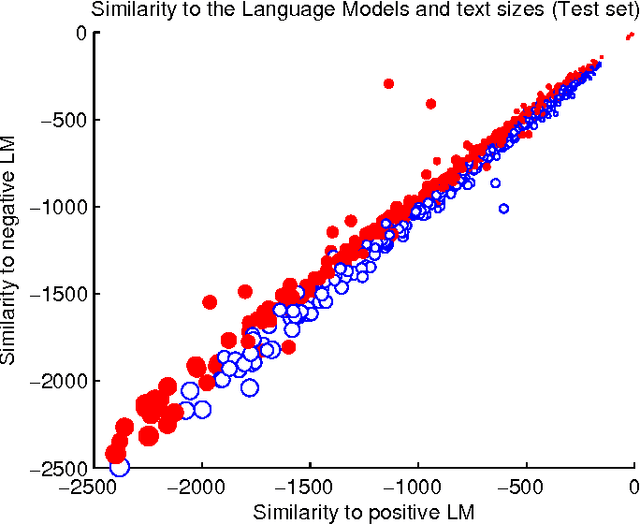

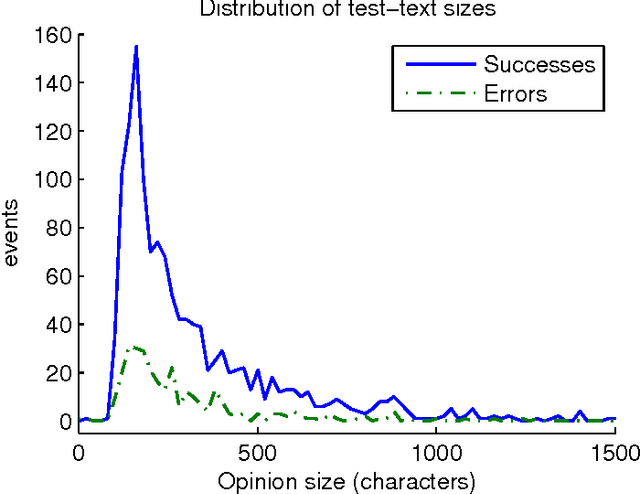
The classification of opinion texts in positive and negative is becoming a subject of great interest in sentiment analysis. The existence of many labeled opinions motivates the use of statistical and machine-learning methods. First-order statistics have proven to be very limited in this field. The Opinum approach is based on the order of the words without using any syntactic and semantic information. It consists of building one probabilistic model for the positive and another one for the negative opinions. Then the test opinions are compared to both models and a decision and confidence measure are calculated. In order to reduce the complexity of the training corpus we first lemmatize the texts and we replace most named-entities with wildcards. Opinum presents an accuracy above 81% for Spanish opinions in the financial products domain. In this work we discuss which are the most important factors that have impact on the classification performance.