 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Long-horizon Embodied Agents with Tool-Aligned Vision-Language-Action Models
May 13, 2026Vision-language-action (VLA) models are effective robot action executors, but they remain limited on long-horizon tasks due to the dual burden of extended closed-loop planning and diverse physical operations. We therefore propose VLAs-as-Tools, a strategy that distributes this burden across a high-level vision language model (VLM) agent for temporal reasoning and a family of specialized VLA tools for diverse local physical operations. The VLM handles scene analysis, global planning, and recovery, while each VLA tool executes a bounded subtask. To tightly couple agent planning with VLA tool execution in long-horizon tasks, we introduce a VLA tool-family interface that exposes explicit tool selection and in-execution progress feedback, enabling efficient event-triggered agent replanning without continuous agent polling. To obtain diverse specialized VLA tools that faithfully follow agent invocations, we further propose Tool-Aligned Post-Training (TAPT), which constructs invocation-aligned training units for instruction following and adopts tool-family residual adapters for efficient tool specialization. Experiments show that VLAs-as-Tools improves the success rate of $π_{0.5}$ by 4.8 points on LIBERO-Long and 23.1 points on RoboTwin, and further enhances invocation fidelity by 15.0 points as measured by Non-biased Rate. Code will be released.
Online Reasoning Video Object Segmentation
Apr 13, 2026Reasoning video object segmentation predicts pixel-level masks in videos from natural-language queries that may involve implicit and temporally grounded references. However, existing methods are developed and evaluated in an offline regime, where the entire video is available at inference time and future frames can be exploited for retrospective disambiguation, deviating from real-world deployments that require strictly causal, frame-by-frame decisions. We study Online Reasoning Video Object Segmentation (ORVOS), where models must incrementally interpret queries using only past and current frames without revisiting previous predictions, while handling referent shifts as events unfold. To support evaluation, we introduce ORVOSB, a benchmark with frame-level causal annotations and referent-shift labels, comprising 210 videos, 12,907 annotated frames, and 512 queries across five reasoning categories. We further propose a baseline with continually-updated segmentation prompts and a structured temporal token reservoir for long-horizon reasoning under bounded computation. Experiments show that existing methods struggle under strict causality and referent shifts, while our baseline establishes a strong foundation for future research.
Memory-Efficient Transfer Learning with Fading Side Networks via Masked Dual Path Distillation
Apr 10, 2026Memory-efficient transfer learning (METL) approaches have recently achieved promising performance in adapting pre-trained models to downstream tasks. They avoid applying gradient backpropagation in large backbones, thus significantly reducing the number of trainable parameters and high memory consumption during fine-tuning. However, since they typically employ a lightweight and learnable side network, these methods inevitably introduce additional memory and time overhead during inference, which contradicts the ultimate goal of efficient transfer learning. To address the above issue, we propose a novel approach dubbed Masked Dual Path Distillation (MDPD) to accelerate inference while retaining parameter and memory efficiency in fine-tuning with fading side networks. Specifically, MDPD develops a framework that enhances the performance by mutually distilling the frozen backbones and learnable side networks in fine-tuning, and discard the side network during inference without sacrificing accuracy. Moreover, we design a novel feature-based knowledge distillation method for the encoder structure with multiple layers. Extensive experiments on distinct backbones across vision/language-only and vision-and-language tasks demonstrate that our method not only accelerates inference by at least 25.2\% while keeping parameter and memory consumption comparable, but also remarkably promotes the accuracy compared to SOTA approaches. The source code is available at https://github.com/Zhang-VKk/MDPD.
FutureVLA: Joint Visuomotor Prediction for Vision-Language-Action Model
Mar 11, 2026Predictive foresight is important to intelligent embodied agents. Since the motor execution of a robot is intrinsically constrained by its visual perception of environmental geometry, effectively anticipating the future requires capturing this tightly coupled visuomotor interplay. While recent vision-language-action models attempt to incorporate future guidance, they struggle with this joint modeling. Existing explicit methods divert capacity to task-irrelevant visual details, whereas implicit methods relying on sparse frame pairs disrupt temporal continuity. By heavily relying on visual reconstruction, these methods become visually dominated, entangling static scene context with dynamic action intent. We argue that effective joint visuomotor predictive modeling requires both temporal continuity and visually-conditioned supervision decoupling. To this end, we propose FutureVLA, featuring a novel Joint Visuomotor Predictive Architecture. FutureVLA is designed to extract joint visuomotor embeddings by first decoupling visual and motor information, and then jointly encoding generalized physical priors. Specifically, in the pretraining stage, we leverage heterogeneous manipulation datasets and introduce a Joint Visuomotor Gating mechanism to structurally separate visual state preservation from temporal action modeling. It allows the motor stream to focus on continuous physical dynamics while explicitly querying visual tokens for environmental constraints, yielding highly generalizable joint visuomotor embeddings. Subsequently, in the post-training stage, we employ a latent embeddings alignment strategy, enabling diverse downstream VLA models to internalize these temporal priors without modifying their inference architectures. Extensive experiments demonstrate that FutureVLA consistently improves VLA frameworks.
Memory-Guided View Refinement for Dynamic Human-in-the-loop EQA
Mar 10, 2026Embodied Question Answering (EQA) has traditionally been evaluated in temporally stable environments where visual evidence can be accumulated reliably. However, in dynamic, human-populated scenes, human activities and occlusions introduce significant perceptual non-stationarity: task-relevant cues are transient and view-dependent, while a store-then-retrieve strategy over-accumulates redundant evidence and increases inference cost. This setting exposes two practical challenges for EQA agents: resolving ambiguity caused by viewpoint-dependent occlusions, and maintaining compact yet up-to-date evidence for efficient inference. To enable systematic study of this setting, we introduce DynHiL-EQA, a human-in-the-loop EQA dataset with two subsets: a Dynamic subset featuring human activities and temporal changes, and a Static subset with temporally stable observations. To address the above challenges, we present DIVRR (Dynamic-Informed View Refinement and Relevance-guided Adaptive Memory Selection), a training-free framework that couples relevance-guided view refinement with selective memory admission. By verifying ambiguous observations before committing them and retaining only informative evidence, DIVRR improves robustness under occlusions while preserving fast inference with compact memory. Extensive experiments on DynHiL-EQA and the established HM-EQA dataset demonstrate that DIVRR consistently improves over existing baselines in both dynamic and static settings while maintaining high inference efficiency.
MSGNav: Unleashing the Power of Multi-modal 3D Scene Graph for Zero-Shot Embodied Navigation
Nov 14, 2025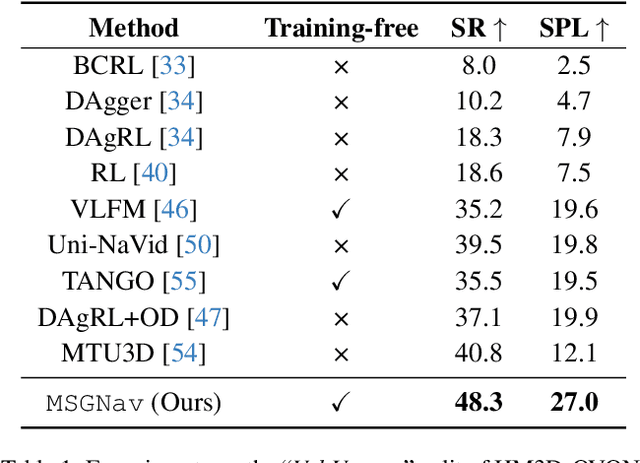
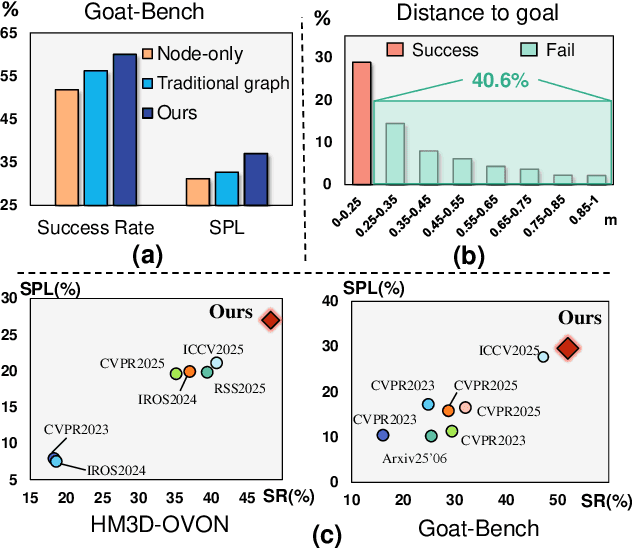
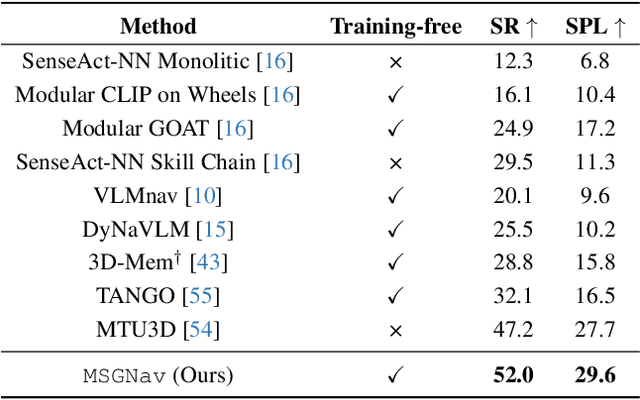
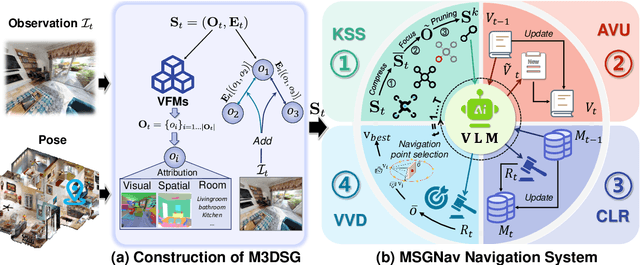
Embodied navigation is a fundamental capability for robotic agents operating. Real-world deployment requires open vocabulary generalization and low training overhead, motivating zero-shot methods rather than task-specific RL training. However, existing zero-shot methods that build explicit 3D scene graphs often compress rich visual observations into text-only relations, leading to high construction cost, irreversible loss of visual evidence, and constrained vocabularies. To address these limitations, we introduce the Multi-modal 3D Scene Graph (M3DSG), which preserves visual cues by replacing textual relation
PolySim: Bridging the Sim-to-Real Gap for Humanoid Control via Multi-Simulator Dynamics Randomization
Oct 02, 2025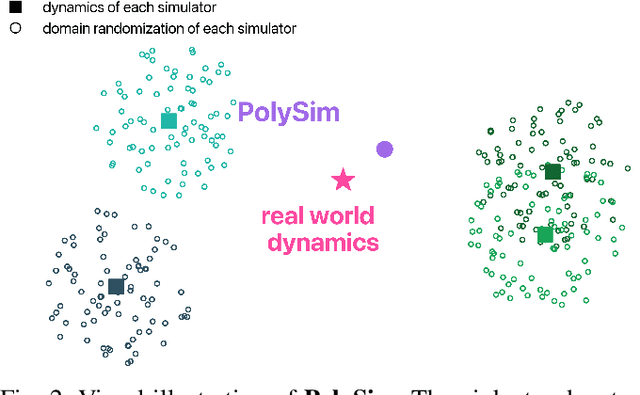
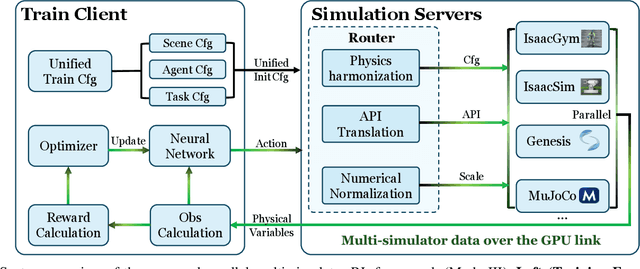
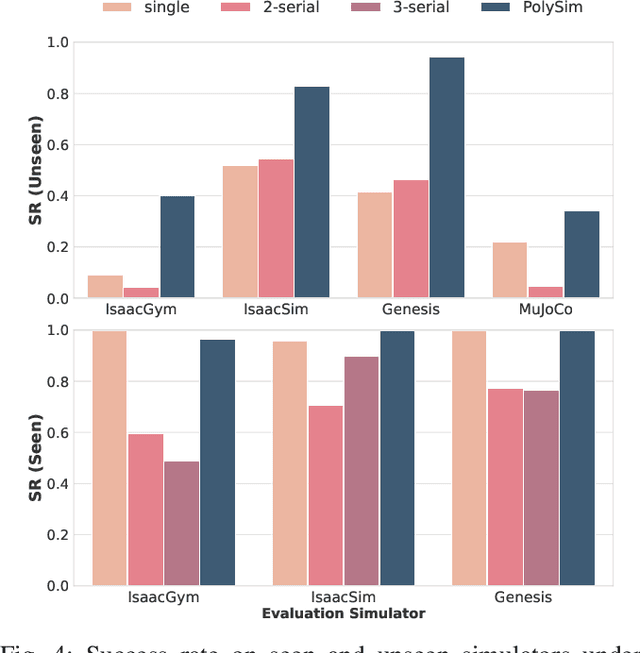

Humanoid whole-body control (WBC) policies trained in simulation often suffer from the sim-to-real gap, which fundamentally arises from simulator inductive bias, the inherent assumptions and limitations of any single simulator. These biases lead to nontrivial discrepancies both across simulators and between simulation and the real world. To mitigate the effect of simulator inductive bias, the key idea is to train policies jointly across multiple simulators, encouraging the learned controller to capture dynamics that generalize beyond any single simulator's assumptions. We thus introduce PolySim, a WBC training platform that integrates multiple heterogeneous simulators. PolySim can launch parallel environments from different engines simultaneously within a single training run, thereby realizing dynamics-level domain randomization. Theoretically, we show that PolySim yields a tighter upper bound on simulator inductive bias than single-simulator training. In experiments, PolySim substantially reduces motion-tracking error in sim-to-sim evaluations; for example, on MuJoCo, it improves execution success by 52.8 over an IsaacSim baseline. PolySim further enables zero-shot deployment on a real Unitree G1 without additional fine-tuning, showing effective transfer from simulation to the real world. We will release the PolySim code upon acceptance of this work.
Multi-Grained Compositional Visual Clue Learning for Image Intent Recognition
Apr 25, 2025



In an era where social media platforms abound, individuals frequently share images that offer insights into their intents and interests, impacting individual life quality and societal stability. Traditional computer vision tasks, such as object detection and semantic segmentation, focus on concrete visual representations, while intent recognition relies more on implicit visual clues. This poses challenges due to the wide variation and subjectivity of such clues, compounded by the problem of intra-class variety in conveying abstract concepts, e.g. "enjoy life". Existing methods seek to solve the problem by manually designing representative features or building prototypes for each class from global features. However, these methods still struggle to deal with the large visual diversity of each intent category. In this paper, we introduce a novel approach named Multi-grained Compositional visual Clue Learning (MCCL) to address these challenges for image intent recognition. Our method leverages the systematic compositionality of human cognition by breaking down intent recognition into visual clue composition and integrating multi-grained features. We adopt class-specific prototypes to alleviate data imbalance. We treat intent recognition as a multi-label classification problem, using a graph convolutional network to infuse prior knowledge through label embedding correlations. Demonstrated by a state-of-the-art performance on the Intentonomy and MDID datasets, our approach advances the accuracy of existing methods while also possessing good interpretability. Our work provides an attempt for future explorations in understanding complex and miscellaneous forms of human expression.
Generating Editable Head Avatars with 3D Gaussian GANs
Dec 26, 2024



Generating animatable and editable 3D head avatars is essential for various applications in computer vision and graphics. Traditional 3D-aware generative adversarial networks (GANs), often using implicit fields like Neural Radiance Fields (NeRF), achieve photorealistic and view-consistent 3D head synthesis. However, these methods face limitations in deformation flexibility and editability, hindering the creation of lifelike and easily modifiable 3D heads. We propose a novel approach that enhances the editability and animation control of 3D head avatars by incorporating 3D Gaussian Splatting (3DGS) as an explicit 3D representation. This method enables easier illumination control and improved editability. Central to our approach is the Editable Gaussian Head (EG-Head) model, which combines a 3D Morphable Model (3DMM) with texture maps, allowing precise expression control and flexible texture editing for accurate animation while preserving identity. To capture complex non-facial geometries like hair, we use an auxiliary set of 3DGS and tri-plane features. Extensive experiments demonstrate that our approach delivers high-quality 3D-aware synthesis with state-of-the-art controllability. Our code and models are available at https://github.com/liguohao96/EGG3D.
Consistent Diffusion: Denoising Diffusion Model with Data-Consistent Training for Image Restoration
Dec 17, 2024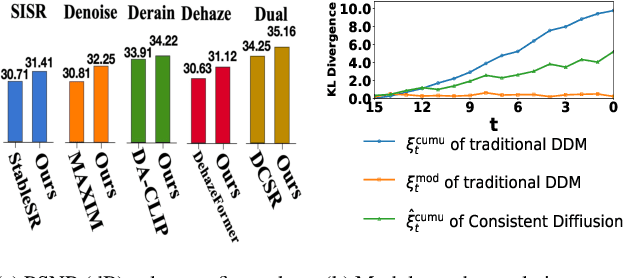
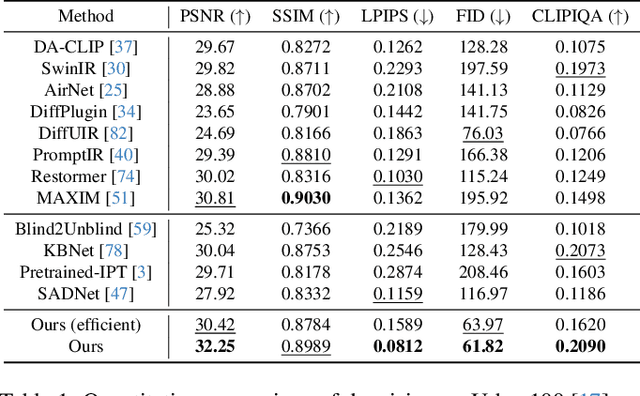


In this work, we address the limitations of denoising diffusion models (DDMs) in image restoration tasks, particularly the shape and color distortions that can compromise image quality. While DDMs have demonstrated a promising performance in many applications such as text-to-image synthesis, their effectiveness in image restoration is often hindered by shape and color distortions. We observe that these issues arise from inconsistencies between the training and testing data used by DDMs. Based on our observation, we propose a novel training method, named data-consistent training, which allows the DDMs to access images with accumulated errors during training, thereby ensuring the model to learn to correct these errors. Experimental results show that, across five image restoration tasks, our method has significant improvements over state-of-the-art methods while effectively minimizing distortions and preserving image fidelity.