 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating Your Editable 3D Photorealistic Avatar with Tetrahedron-constrained Gaussian Splatting
Apr 29, 2025



Personalized 3D avatar editing holds significant promise due to its user-friendliness and availability to applications such as AR/VR and virtual try-ons. Previous studies have explored the feasibility of 3D editing, but often struggle to generate visually pleasing results, possibly due to the unstable representation learning under mixed optimization of geometry and texture in complicated reconstructed scenarios. In this paper, we aim to provide an accessible solution for ordinary users to create their editable 3D avatars with precise region localization, geometric adaptability, and photorealistic renderings. To tackle this challenge, we introduce a meticulously designed framework that decouples the editing process into local spatial adaptation and realistic appearance learning, utilizing a hybrid Tetrahedron-constrained Gaussian Splatting (TetGS) as the underlying representation. TetGS combines the controllable explicit structure of tetrahedral grids with the high-precision rendering capabilities of 3D Gaussian Splatting and is optimized in a progressive manner comprising three stages: 3D avatar instantiation from real-world monocular videos to provide accurate priors for TetGS initialization; localized spatial adaptation with explicitly partitioned tetrahedrons to guide the redistribution of Gaussian kernels; and geometry-based appearance generation with a coarse-to-fine activation strategy. Both qualitative and quantitative experiments demonstrate the effectiveness and superiority of our approach in generating photorealistic 3D editable avatars.
Perception-as-Control: Fine-grained Controllable Image Animation with 3D-aware Motion Representation
Jan 09, 2025



Motion-controllable image animation is a fundamental task with a wide range of potential applications. Recent works have made progress in controlling camera or object motion via various motion representations, while they still struggle to support collaborative camera and object motion control with adaptive control granularity. To this end, we introduce 3D-aware motion representation and propose an image animation framework, called Perception-as-Control, to achieve fine-grained collaborative motion control. Specifically, we construct 3D-aware motion representation from a reference image, manipulate it based on interpreted user intentions, and perceive it from different viewpoints. In this way, camera and object motions are transformed into intuitive, consistent visual changes. Then, the proposed framework leverages the perception results as motion control signals, enabling it to support various motion-related video synthesis tasks in a unified and flexible way. Experiments demonstrate the superiority of the proposed framework. For more details and qualitative results, please refer to our project webpage: https://chen-yingjie.github.io/projects/Perception-as-Control.
Generating Editable Head Avatars with 3D Gaussian GANs
Dec 26, 2024



Generating animatable and editable 3D head avatars is essential for various applications in computer vision and graphics. Traditional 3D-aware generative adversarial networks (GANs), often using implicit fields like Neural Radiance Fields (NeRF), achieve photorealistic and view-consistent 3D head synthesis. However, these methods face limitations in deformation flexibility and editability, hindering the creation of lifelike and easily modifiable 3D heads. We propose a novel approach that enhances the editability and animation control of 3D head avatars by incorporating 3D Gaussian Splatting (3DGS) as an explicit 3D representation. This method enables easier illumination control and improved editability. Central to our approach is the Editable Gaussian Head (EG-Head) model, which combines a 3D Morphable Model (3DMM) with texture maps, allowing precise expression control and flexible texture editing for accurate animation while preserving identity. To capture complex non-facial geometries like hair, we use an auxiliary set of 3DGS and tri-plane features. Extensive experiments demonstrate that our approach delivers high-quality 3D-aware synthesis with state-of-the-art controllability. Our code and models are available at https://github.com/liguohao96/EGG3D.
MIMO: Controllable Character Video Synthesis with Spatial Decomposed Modeling
Sep 24, 2024



Character video synthesis aims to produce realistic videos of animatable characters within lifelike scenes. As a fundamental problem in the computer vision and graphics community, 3D works typically require multi-view captures for per-case training, which severely limits their applicability of modeling arbitrary characters in a short time. Recent 2D methods break this limitation via pre-trained diffusion models, but they struggle for pose generality and scene interaction. To this end, we propose MIMO, a novel framework which can not only synthesize character videos with controllable attributes (i.e., character, motion and scene) provided by simple user inputs, but also simultaneously achieve advanced scalability to arbitrary characters, generality to novel 3D motions, and applicability to interactive real-world scenes in a unified framework. The core idea is to encode the 2D video to compact spatial codes, considering the inherent 3D nature of video occurrence. Concretely, we lift the 2D frame pixels into 3D using monocular depth estimators, and decompose the video clip to three spatial components (i.e., main human, underlying scene, and floating occlusion) in hierarchical layers based on the 3D depth. These components are further encoded to canonical identity code, structured motion code and full scene code, which are utilized as control signals of synthesis process. The design of spatial decomposed modeling enables flexible user control, complex motion expression, as well as 3D-aware synthesis for scene interactions. Experimental results demonstrate effectiveness and robustness of the proposed method.
En3D: An Enhanced Generative Model for Sculpting 3D Humans from 2D Synthetic Data
Jan 02, 2024



We present En3D, an enhanced generative scheme for sculpting high-quality 3D human avatars. Unlike previous works that rely on scarce 3D datasets or limited 2D collections with imbalanced viewing angles and imprecise pose priors, our approach aims to develop a zero-shot 3D generative scheme capable of producing visually realistic, geometrically accurate and content-wise diverse 3D humans without relying on pre-existing 3D or 2D assets. To address this challenge, we introduce a meticulously crafted workflow that implements accurate physical modeling to learn the enhanced 3D generative model from synthetic 2D data. During inference, we integrate optimization modules to bridge the gap between realistic appearances and coarse 3D shapes. Specifically, En3D comprises three modules: a 3D generator that accurately models generalizable 3D humans with realistic appearance from synthesized balanced, diverse, and structured human images; a geometry sculptor that enhances shape quality using multi-view normal constraints for intricate human anatomy; and a texturing module that disentangles explicit texture maps with fidelity and editability, leveraging semantical UV partitioning and a differentiable rasterizer. Experimental results show that our approach significantly outperforms prior works in terms of image quality, geometry accuracy and content diversity. We also showcase the applicability of our generated avatars for animation and editing, as well as the scalability of our approach for content-style free adaptation.
DCT-Net: Domain-Calibrated Translation for Portrait Stylization
Jul 06, 2022
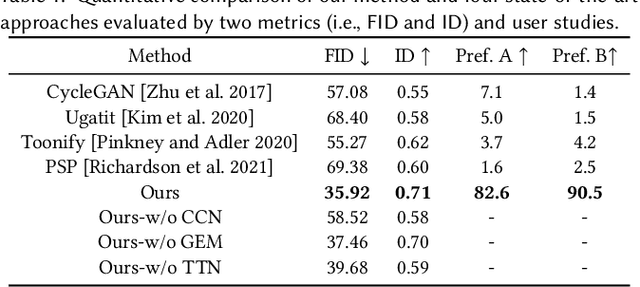
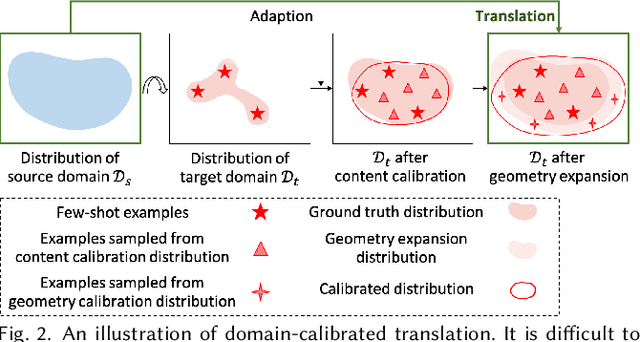
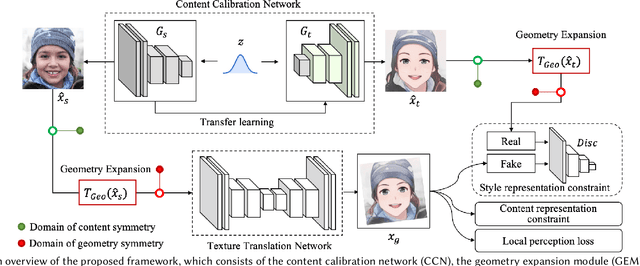
This paper introduces DCT-Net, a novel image translation architecture for few-shot portrait stylization. Given limited style exemplars ($\sim$100), the new architecture can produce high-quality style transfer results with advanced ability to synthesize high-fidelity contents and strong generality to handle complicated scenes (e.g., occlusions and accessories). Moreover, it enables full-body image translation via one elegant evaluation network trained by partial observations (i.e., stylized heads). Few-shot learning based style transfer is challenging since the learned model can easily become overfitted in the target domain, due to the biased distribution formed by only a few training examples. This paper aims to handle the challenge by adopting the key idea of "calibration first, translation later" and exploring the augmented global structure with locally-focused translation. Specifically, the proposed DCT-Net consists of three modules: a content adapter borrowing the powerful prior from source photos to calibrate the content distribution of target samples; a geometry expansion module using affine transformations to release spatially semantic constraints; and a texture translation module leveraging samples produced by the calibrated distribution to learn a fine-grained conversion. Experimental results demonstrate the proposed method's superiority over the state of the art in head stylization and its effectiveness on full image translation with adaptive deformations.
Controllable Person Image Synthesis with Attribute-Decomposed GAN
Apr 18, 2020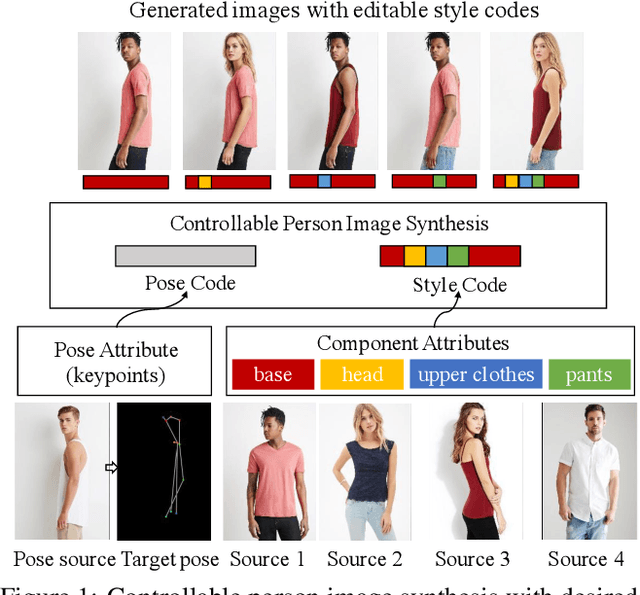
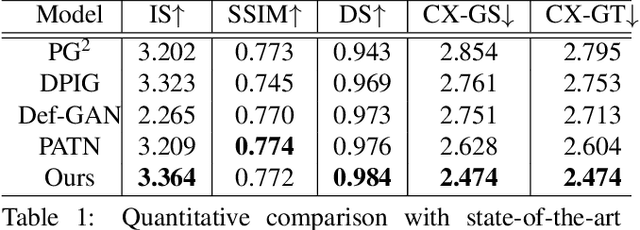
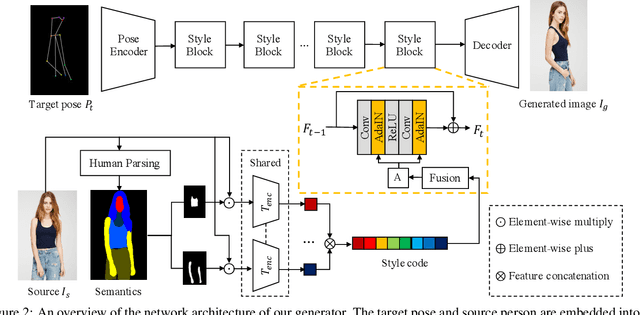
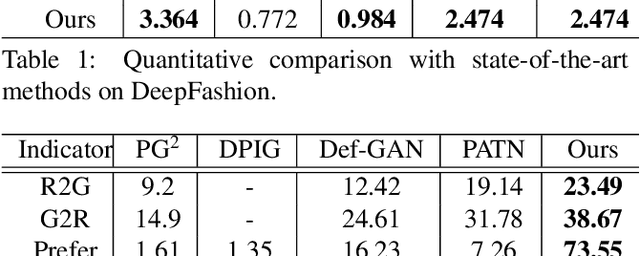
This paper introduces the Attribute-Decomposed GAN, a novel generative model for controllable person image synthesis, which can produce realistic person images with desired human attributes (e.g., pose, head, upper clothes and pants) provided in various source inputs. The core idea of the proposed model is to embed human attributes into the latent space as independent codes and thus achieve flexible and continuous control of attributes via mixing and interpolation operations in explicit style representations. Specifically, a new architecture consisting of two encoding pathways with style block connections is proposed to decompose the original hard mapping into multiple more accessible subtasks. In source pathway, we further extract component layouts with an off-the-shelf human parser and feed them into a shared global texture encoder for decomposed latent codes. This strategy allows for the synthesis of more realistic output images and automatic separation of un-annotated attributes. Experimental results demonstrate the proposed method's superiority over the state of the art in pose transfer and its effectiveness in the brand-new task of component attribute transfer.