 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating Your Editable 3D Photorealistic Avatar with Tetrahedron-constrained Gaussian Splatting
Apr 29, 2025



Personalized 3D avatar editing holds significant promise due to its user-friendliness and availability to applications such as AR/VR and virtual try-ons. Previous studies have explored the feasibility of 3D editing, but often struggle to generate visually pleasing results, possibly due to the unstable representation learning under mixed optimization of geometry and texture in complicated reconstructed scenarios. In this paper, we aim to provide an accessible solution for ordinary users to create their editable 3D avatars with precise region localization, geometric adaptability, and photorealistic renderings. To tackle this challenge, we introduce a meticulously designed framework that decouples the editing process into local spatial adaptation and realistic appearance learning, utilizing a hybrid Tetrahedron-constrained Gaussian Splatting (TetGS) as the underlying representation. TetGS combines the controllable explicit structure of tetrahedral grids with the high-precision rendering capabilities of 3D Gaussian Splatting and is optimized in a progressive manner comprising three stages: 3D avatar instantiation from real-world monocular videos to provide accurate priors for TetGS initialization; localized spatial adaptation with explicitly partitioned tetrahedrons to guide the redistribution of Gaussian kernels; and geometry-based appearance generation with a coarse-to-fine activation strategy. Both qualitative and quantitative experiments demonstrate the effectiveness and superiority of our approach in generating photorealistic 3D editable avatars.
Prompt Valuation Based on Shapley Values
Dec 24, 2023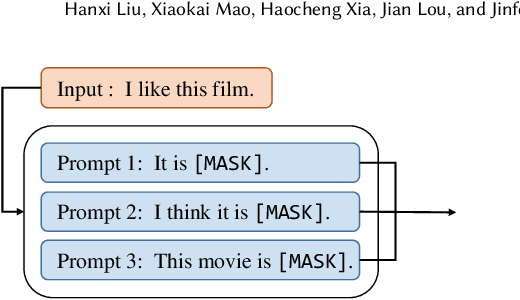
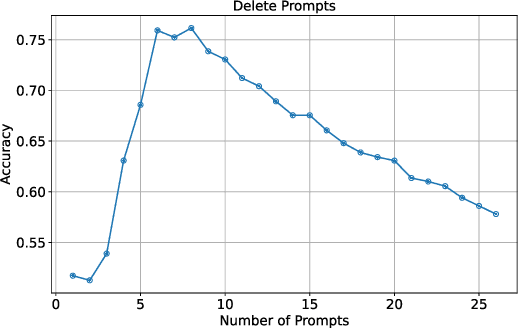
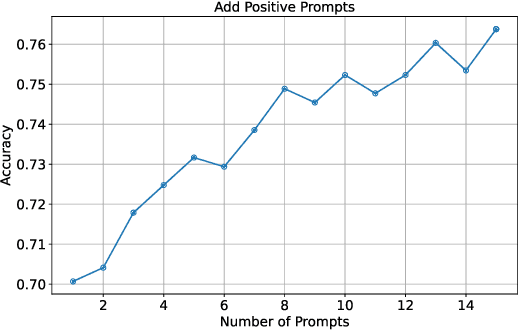
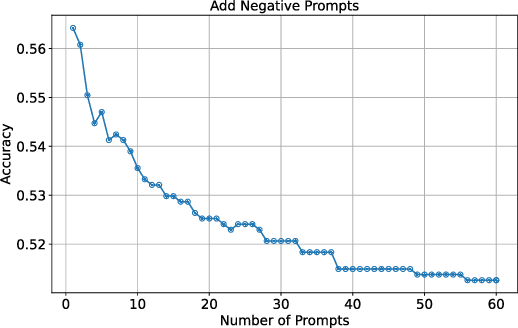
Large language models (LLMs) excel on new tasks without additional training, simply by providing natural language prompts that demonstrate how the task should be performed. Prompt ensemble methods comprehensively harness the knowledge of LLMs while mitigating individual biases and errors and further enhancing performance. However, more prompts do not necessarily lead to better results, and not all prompts are beneficial. A small number of high-quality prompts often outperform many low-quality prompts. Currently, there is a lack of a suitable method for evaluating the impact of prompts on the results. In this paper, we utilize the Shapley value to fairly quantify the contributions of prompts, helping to identify beneficial or detrimental prompts, and potentially guiding prompt valuation in data markets. Through extensive experiments employing various ensemble methods and utility functions on diverse tasks, we validate the effectiveness of using the Shapley value method for prompts as it effectively distinguishes and quantifies the contributions of each prompt.