 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Attribution in Directed Acyclic Graphs Using Edge Intervention
Jun 13, 2026Shapley value-based feature attribution methods face challenges in scenarios involving complex feature interactions and causal relationships, even when a causal structure is provided. Existing methods typically adopt a node-centric view, attributing importance solely to individual features. Consequently, they often fail to simultaneously capture the externality and exogenous influence of features, leading to unreasonable interpretations. To overcome these limitations, we propose a novel feature attribution method called DAG-SHAP, which is based on edge intervention. DAG-SHAP treats each feature edge as an individual attribution object, ensuring that both externality and exogenous contributions of features are appropriately captured. Additionally, we introduce an approximation method for efficiently computing DAG-SHAP. Extensive experiments on both real and synthetic datasets validate the effectiveness of DAG-SHAP. Our code is available at https://github.com/ZJU-DIVER/DAG-SHAP.
LazyAttention: Efficient Retrieval-Augmented Generation with Deferred Positional Encoding
Jun 03, 2026Key-value (KV) caching accelerates inference of large language models (LLMs) by reusing past computations for generated tokens. Its importance becomes even greater in long-context applications such as retrieval-augmented generation (RAG) and in-context learning (ICL). However, conventional KV caching embeds positional information directly into the cache, limiting its reusability. Existing solutions either restrict reuse to prefixes or require expensive memory materialization for positional re-encoding. We introduce LazyAttention, a novel attention mechanism that kernelizes deferred positional encoding to enable zero-copy, position-agnostic KV reuse. By adjusting positional encoding within attention kernels on-the-fly, LazyAttention resolves the materialization bottleneck, allowing a single physical KV copy to serve multiple logical requests at arbitrary positions. Leveraging attention kernels tailored for prefilling and decoding, our system achieves significant efficiency improvements: under skewed document distributions, it reduces time-to-first-token (TTFT) by 1.37$\times$ and increases inference throughput by 1.40$\times$ compared to the state-of-the-art Block-Attention, while maintaining comparable output quality.
CoKV: Optimizing KV Cache Allocation via Cooperative Game
Feb 21, 2025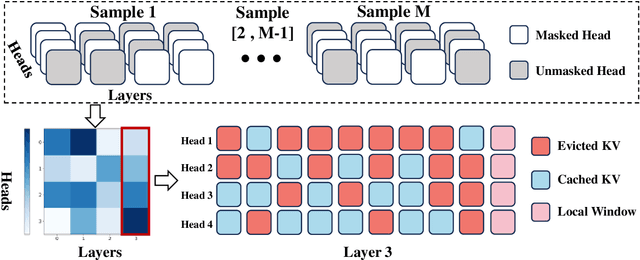
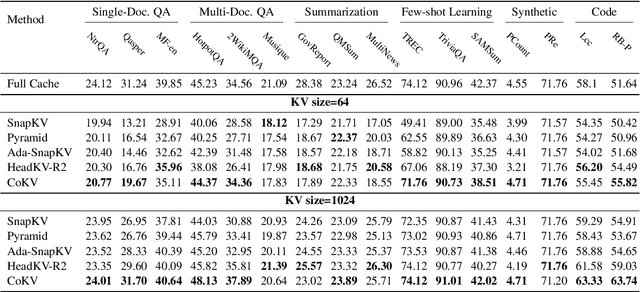
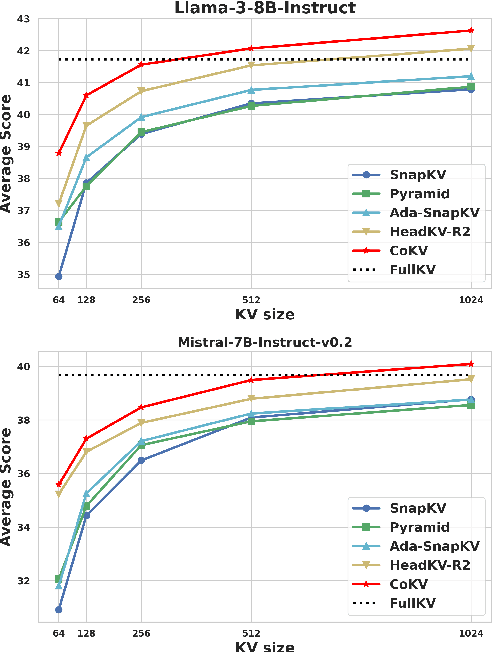

Large language models (LLMs) have achieved remarkable success on various aspects of human life. However, one of the major challenges in deploying these models is the substantial memory consumption required to store key-value pairs (KV), which imposes significant resource demands. Recent research has focused on KV cache budget allocation, with several approaches proposing head-level budget distribution by evaluating the importance of individual attention heads. These methods, however, assess the importance of heads independently, overlooking their cooperative contributions within the model, which may result in a deviation from their true impact on model performance. In light of this limitation, we propose CoKV, a novel method that models the cooperation between heads in model inference as a cooperative game. By evaluating the contribution of each head within the cooperative game, CoKV can allocate the cache budget more effectively. Extensive experiments show that CoKV achieves state-of-the-art performance on the LongBench benchmark using LLama-3-8B-Instruct and Mistral-7B models.
A Survey on Data Markets
Nov 09, 2024



Data is the new oil of the 21st century. The growing trend of trading data for greater welfare has led to the emergence of data markets. A data market is any mechanism whereby the exchange of data products including datasets and data derivatives takes place as a result of data buyers and data sellers being in contact with one another, either directly or through mediating agents. It serves as a coordinating mechanism by which several functions, including the pricing and the distribution of data as the most important ones, interact to make the value of data fully exploited and enhanced. In this article, we present a comprehensive survey of this important and emerging direction from the aspects of data search, data productization, data transaction, data pricing, revenue allocation as well as privacy, security, and trust issues. We also investigate the government policies and industry status of data markets across different countries and different domains. Finally, we identify the unresolved challenges and discuss possible future directions for the development of data markets.
TabularMark: Watermarking Tabular Datasets for Machine Learning
Jun 21, 2024
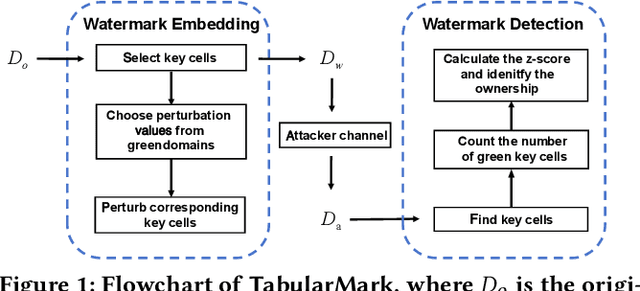
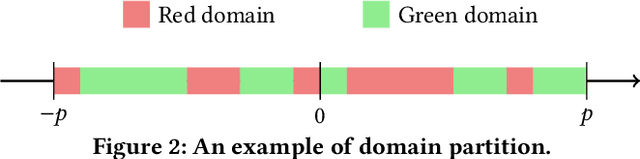
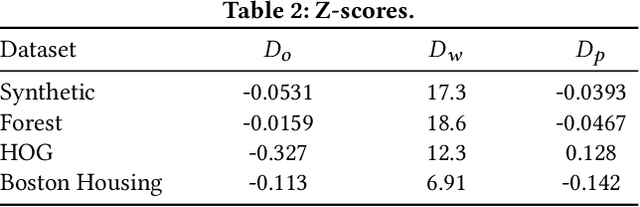
Watermarking is broadly utilized to protect ownership of shared data while preserving data utility. However, existing watermarking methods for tabular datasets fall short on the desired properties (detectability, non-intrusiveness, and robustness) and only preserve data utility from the perspective of data statistics, ignoring the performance of downstream ML models trained on the datasets. Can we watermark tabular datasets without significantly compromising their utility for training ML models while preventing attackers from training usable ML models on attacked datasets? In this paper, we propose a hypothesis testing-based watermarking scheme, TabularMark. Data noise partitioning is utilized for data perturbation during embedding, which is adaptable for numerical and categorical attributes while preserving the data utility. For detection, a custom-threshold one proportion z-test is employed, which can reliably determine the presence of the watermark. Experiments on real-world and synthetic datasets demonstrate the superiority of TabularMark in detectability, non-intrusiveness, and robustness.
Prompt Valuation Based on Shapley Values
Dec 24, 2023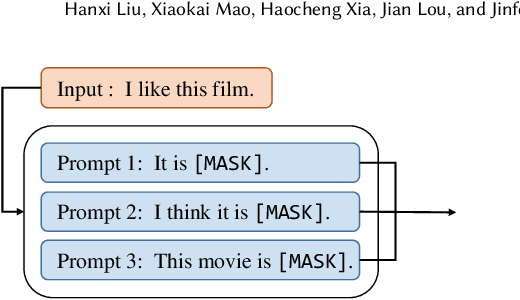
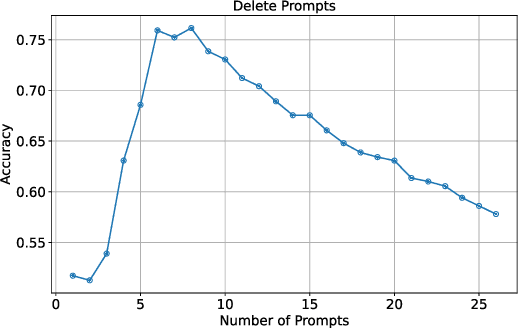
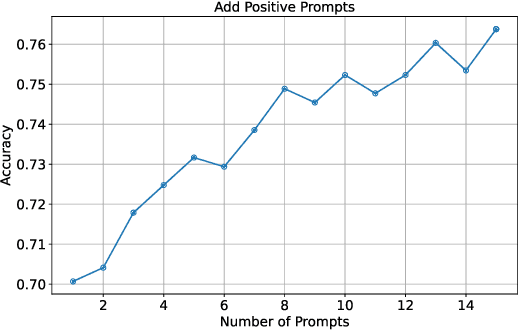
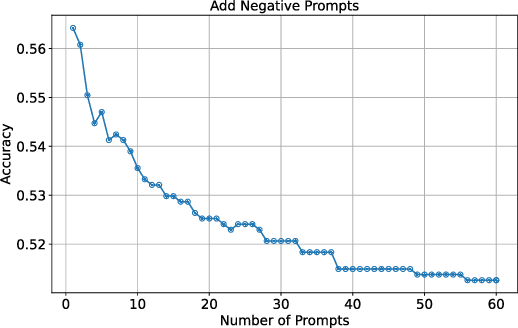
Large language models (LLMs) excel on new tasks without additional training, simply by providing natural language prompts that demonstrate how the task should be performed. Prompt ensemble methods comprehensively harness the knowledge of LLMs while mitigating individual biases and errors and further enhancing performance. However, more prompts do not necessarily lead to better results, and not all prompts are beneficial. A small number of high-quality prompts often outperform many low-quality prompts. Currently, there is a lack of a suitable method for evaluating the impact of prompts on the results. In this paper, we utilize the Shapley value to fairly quantify the contributions of prompts, helping to identify beneficial or detrimental prompts, and potentially guiding prompt valuation in data markets. Through extensive experiments employing various ensemble methods and utility functions on diverse tasks, we validate the effectiveness of using the Shapley value method for prompts as it effectively distinguishes and quantifies the contributions of each prompt.
Shapley Value on Probabilistic Classifiers
Jun 12, 2023



Data valuation has become an increasingly significant discipline in data science due to the economic value of data. In the context of machine learning (ML), data valuation methods aim to equitably measure the contribution of each data point to the utility of an ML model. One prevalent method is Shapley value, which helps identify data points that are beneficial or detrimental to an ML model. However, traditional Shapley-based data valuation methods may not effectively distinguish between beneficial and detrimental training data points for probabilistic classifiers. In this paper, we propose Probabilistic Shapley (P-Shapley) value by constructing a probability-wise utility function that leverages the predicted class probabilities of probabilistic classifiers rather than binarized prediction results in the traditional Shapley value. We also offer several activation functions for confidence calibration to effectively quantify the marginal contribution of each data point to the probabilistic classifiers. Extensive experiments on four real-world datasets demonstrate the effectiveness of our proposed P-Shapley value in evaluating the importance of data for building a high-usability and trustworthy ML model.