 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Valuation Based on Shapley Values
Paper and Code
Dec 24, 2023
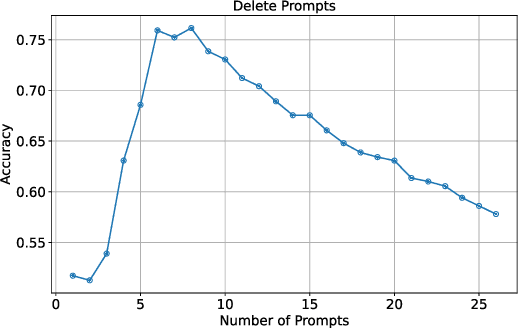
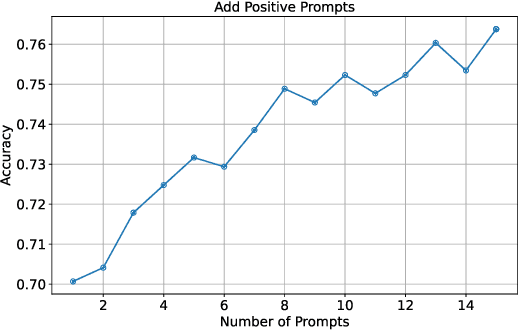
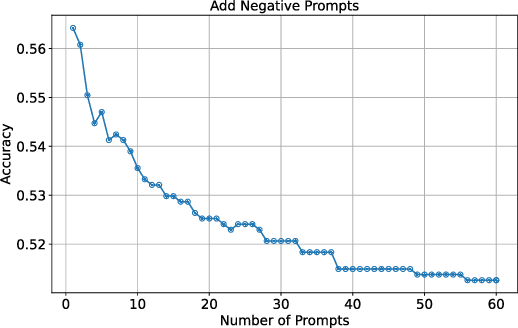
Large language models (LLMs) excel on new tasks without additional training, simply by providing natural language prompts that demonstrate how the task should be performed. Prompt ensemble methods comprehensively harness the knowledge of LLMs while mitigating individual biases and errors and further enhancing performance. However, more prompts do not necessarily lead to better results, and not all prompts are beneficial. A small number of high-quality prompts often outperform many low-quality prompts. Currently, there is a lack of a suitable method for evaluating the impact of prompts on the results. In this paper, we utilize the Shapley value to fairly quantify the contributions of prompts, helping to identify beneficial or detrimental prompts, and potentially guiding prompt valuation in data markets. Through extensive experiments employing various ensemble methods and utility functions on diverse tasks, we validate the effectiveness of using the Shapley value method for prompts as it effectively distinguishes and quantifies the contributions of each prompt.