 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShortFT: Diffusion Model Alignment via Shortcut-based Fine-Tuning
Jul 30, 2025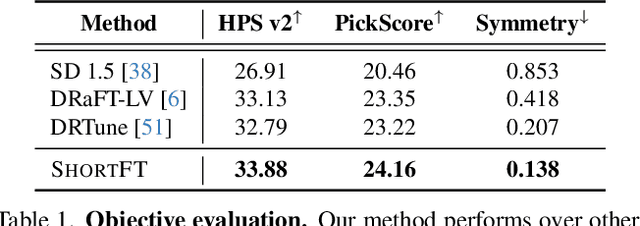


Backpropagation-based approaches aim to align diffusion models with reward functions through end-to-end backpropagation of the reward gradient within the denoising chain, offering a promising perspective. However, due to the computational costs and the risk of gradient explosion associated with the lengthy denoising chain, existing approaches struggle to achieve complete gradient backpropagation, leading to suboptimal results. In this paper, we introduce Shortcut-based Fine-Tuning (ShortFT), an efficient fine-tuning strategy that utilizes the shorter denoising chain. More specifically, we employ the recently researched trajectory-preserving few-step diffusion model, which enables a shortcut over the original denoising chain, and construct a shortcut-based denoising chain of shorter length. The optimization on this chain notably enhances the efficiency and effectiveness of fine-tuning the foundational model. Our method has been rigorously tested and can be effectively applied to various reward functions, significantly improving alignment performance and surpassing state-of-the-art alternatives.
MoSAM: Motion-Guided Segment Anything Model with Spatial-Temporal Memory Selection
Apr 30, 2025



The recent Segment Anything Model 2 (SAM2) has demonstrated exceptional capabilities in interactive object segmentation for both images and videos. However, as a foundational model on interactive segmentation, SAM2 performs segmentation directly based on mask memory from the past six frames, leading to two significant challenges. Firstly, during inference in videos, objects may disappear since SAM2 relies solely on memory without accounting for object motion information, which limits its long-range object tracking capabilities. Secondly, its memory is constructed from fixed past frames, making it susceptible to challenges associated with object disappearance or occlusion, due to potentially inaccurate segmentation results in memory. To address these problems, we present MoSAM, incorporating two key strategies to integrate object motion cues into the model and establish more reliable feature memory. Firstly, we propose Motion-Guided Prompting (MGP), which represents the object motion in both sparse and dense manners, then injects them into SAM2 through a set of motion-guided prompts. MGP enables the model to adjust its focus towards the direction of motion, thereby enhancing the object tracking capabilities. Furthermore, acknowledging that past segmentation results may be inaccurate, we devise a Spatial-Temporal Memory Selection (ST-MS) mechanism that dynamically identifies frames likely to contain accurate segmentation in both pixel- and frame-level. By eliminating potentially inaccurate mask predictions from memory, we can leverage more reliable memory features to exploit similar regions for improving segmentation results. Extensive experiments on various benchmarks of video object segmentation and video instance segmentation demonstrate that our MoSAM achieves state-of-the-art results compared to other competitors.
GaussianIP: Identity-Preserving Realistic 3D Human Generation via Human-Centric Diffusion Prior
Mar 14, 2025Text-guided 3D human generation has advanced with the development of efficient 3D representations and 2D-lifting methods like Score Distillation Sampling (SDS). However, current methods suffer from prolonged training times and often produce results that lack fine facial and garment details. In this paper, we propose GaussianIP, an effective two-stage framework for generating identity-preserving realistic 3D humans from text and image prompts. Our core insight is to leverage human-centric knowledge to facilitate the generation process. In stage 1, we propose a novel Adaptive Human Distillation Sampling (AHDS) method to rapidly generate a 3D human that maintains high identity consistency with the image prompt and achieves a realistic appearance. Compared to traditional SDS methods, AHDS better aligns with the human-centric generation process, enhancing visual quality with notably fewer training steps. To further improve the visual quality of the face and clothes regions, we design a View-Consistent Refinement (VCR) strategy in stage 2. Specifically, it produces detail-enhanced results of the multi-view images from stage 1 iteratively, ensuring the 3D texture consistency across views via mutual attention and distance-guided attention fusion. Then a polished version of the 3D human can be achieved by directly perform reconstruction with the refined images. Extensive experiments demonstrate that GaussianIP outperforms existing methods in both visual quality and training efficiency, particularly in generating identity-preserving results. Our code is available at: https://github.com/silence-tang/GaussianIP.
Perception-as-Control: Fine-grained Controllable Image Animation with 3D-aware Motion Representation
Jan 09, 2025



Motion-controllable image animation is a fundamental task with a wide range of potential applications. Recent works have made progress in controlling camera or object motion via various motion representations, while they still struggle to support collaborative camera and object motion control with adaptive control granularity. To this end, we introduce 3D-aware motion representation and propose an image animation framework, called Perception-as-Control, to achieve fine-grained collaborative motion control. Specifically, we construct 3D-aware motion representation from a reference image, manipulate it based on interpreted user intentions, and perceive it from different viewpoints. In this way, camera and object motions are transformed into intuitive, consistent visual changes. Then, the proposed framework leverages the perception results as motion control signals, enabling it to support various motion-related video synthesis tasks in a unified and flexible way. Experiments demonstrate the superiority of the proposed framework. For more details and qualitative results, please refer to our project webpage: https://chen-yingjie.github.io/projects/Perception-as-Control.
MIMO: Controllable Character Video Synthesis with Spatial Decomposed Modeling
Sep 24, 2024



Character video synthesis aims to produce realistic videos of animatable characters within lifelike scenes. As a fundamental problem in the computer vision and graphics community, 3D works typically require multi-view captures for per-case training, which severely limits their applicability of modeling arbitrary characters in a short time. Recent 2D methods break this limitation via pre-trained diffusion models, but they struggle for pose generality and scene interaction. To this end, we propose MIMO, a novel framework which can not only synthesize character videos with controllable attributes (i.e., character, motion and scene) provided by simple user inputs, but also simultaneously achieve advanced scalability to arbitrary characters, generality to novel 3D motions, and applicability to interactive real-world scenes in a unified framework. The core idea is to encode the 2D video to compact spatial codes, considering the inherent 3D nature of video occurrence. Concretely, we lift the 2D frame pixels into 3D using monocular depth estimators, and decompose the video clip to three spatial components (i.e., main human, underlying scene, and floating occlusion) in hierarchical layers based on the 3D depth. These components are further encoded to canonical identity code, structured motion code and full scene code, which are utilized as control signals of synthesis process. The design of spatial decomposed modeling enables flexible user control, complex motion expression, as well as 3D-aware synthesis for scene interactions. Experimental results demonstrate effectiveness and robustness of the proposed method.
MotionCom: Automatic and Motion-Aware Image Composition with LLM and Video Diffusion Prior
Sep 16, 2024
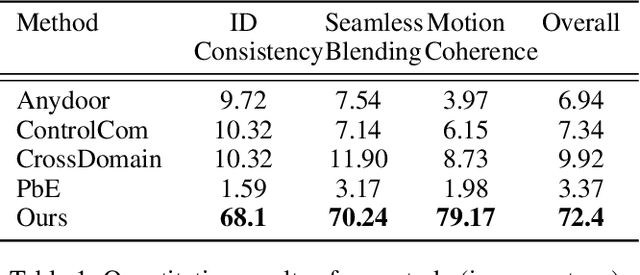


This work presents MotionCom, a training-free motion-aware diffusion based image composition, enabling automatic and seamless integration of target objects into new scenes with dynamically coherent results without finetuning or optimization. Traditional approaches in this area suffer from two significant limitations: they require manual planning for object placement and often generate static compositions lacking motion realism. MotionCom addresses these issues by utilizing a Large Vision Language Model (LVLM) for intelligent planning, and a Video Diffusion prior for motion-infused image synthesis, streamlining the composition process. Our multi-modal Chain-of-Thought (CoT) prompting with LVLM automates the strategic placement planning of foreground objects, considering their potential motion and interaction within the scenes. Complementing this, we propose a novel method MotionPaint to distill motion-aware information from pretrained video diffusion models in the generation phase, ensuring that these objects are not only seamlessly integrated but also endowed with realistic motion. Extensive quantitative and qualitative results highlight MotionCom's superiority, showcasing its efficiency in streamlining the planning process and its capability to produce compositions that authentically depict motion and interaction.
I4VGen: Image as Stepping Stone for Text-to-Video Generation
Jun 04, 2024



Text-to-video generation has lagged behind text-to-image synthesis in quality and diversity due to the complexity of spatio-temporal modeling and limited video-text datasets. This paper presents I4VGen, a training-free and plug-and-play video diffusion inference framework, which enhances text-to-video generation by leveraging robust image techniques. Specifically, following text-to-image-to-video, I4VGen decomposes the text-to-video generation into two stages: anchor image synthesis and anchor image-guided video synthesis. Correspondingly, a well-designed generation-selection pipeline is employed to achieve visually-realistic and semantically-faithful anchor image, and an innovative Noise-Invariant Video Score Distillation Sampling is incorporated to animate the image to a dynamic video, followed by a video regeneration process to refine the video. This inference strategy effectively mitigates the prevalent issue of non-zero terminal signal-to-noise ratio. Extensive evaluations show that I4VGen not only produces videos with higher visual realism and textual fidelity but also integrates seamlessly into existing image-to-video diffusion models, thereby improving overall video quality.
Disentangling Foreground and Background Motion for Enhanced Realism in Human Video Generation
May 28, 2024



Recent advancements in human video synthesis have enabled the generation of high-quality videos through the application of stable diffusion models. However, existing methods predominantly concentrate on animating solely the human element (the foreground) guided by pose information, while leaving the background entirely static. Contrary to this, in authentic, high-quality videos, backgrounds often dynamically adjust in harmony with foreground movements, eschewing stagnancy. We introduce a technique that concurrently learns both foreground and background dynamics by segregating their movements using distinct motion representations. Human figures are animated leveraging pose-based motion, capturing intricate actions. Conversely, for backgrounds, we employ sparse tracking points to model motion, thereby reflecting the natural interaction between foreground activity and environmental changes. Training on real-world videos enhanced with this innovative motion depiction approach, our model generates videos exhibiting coherent movement in both foreground subjects and their surrounding contexts. To further extend video generation to longer sequences without accumulating errors, we adopt a clip-by-clip generation strategy, introducing global features at each step. To ensure seamless continuity across these segments, we ingeniously link the final frame of a produced clip with input noise to spawn the succeeding one, maintaining narrative flow. Throughout the sequential generation process, we infuse the feature representation of the initial reference image into the network, effectively curtailing any cumulative color inconsistencies that may otherwise arise. Empirical evaluations attest to the superiority of our method in producing videos that exhibit harmonious interplay between foreground actions and responsive background dynamics, surpassing prior methodologies in this regard.
InitNO: Boosting Text-to-Image Diffusion Models via Initial Noise Optimization
Apr 06, 2024



Recent strides in the development of diffusion models, exemplified by advancements such as Stable Diffusion, have underscored their remarkable prowess in generating visually compelling images. However, the imperative of achieving a seamless alignment between the generated image and the provided prompt persists as a formidable challenge. This paper traces the root of these difficulties to invalid initial noise, and proposes a solution in the form of Initial Noise Optimization (InitNO), a paradigm that refines this noise. Considering text prompts, not all random noises are effective in synthesizing semantically-faithful images. We design the cross-attention response score and the self-attention conflict score to evaluate the initial noise, bifurcating the initial latent space into valid and invalid sectors. A strategically crafted noise optimization pipeline is developed to guide the initial noise towards valid regions. Our method, validated through rigorous experimentation, shows a commendable proficiency in generating images in strict accordance with text prompts. Our code is available at https://github.com/xiefan-guo/initno.
DivAvatar: Diverse 3D Avatar Generation with a Single Prompt
Feb 27, 2024



Text-to-Avatar generation has recently made significant strides due to advancements in diffusion models. However, most existing work remains constrained by limited diversity, producing avatars with subtle differences in appearance for a given text prompt. We design DivAvatar, a novel framework that generates diverse avatars, empowering 3D creatives with a multitude of distinct and richly varied 3D avatars from a single text prompt. Different from most existing work that exploits scene-specific 3D representations such as NeRF, DivAvatar finetunes a 3D generative model (i.e., EVA3D), allowing diverse avatar generation from simply noise sampling in inference time. DivAvatar has two key designs that help achieve generation diversity and visual quality. The first is a noise sampling technique during training phase which is critical in generating diverse appearances. The second is a semantic-aware zoom mechanism and a novel depth loss, the former producing appearances of high textual fidelity by separate fine-tuning of specific body parts and the latter improving geometry quality greatly by smoothing the generated mesh in the features space. Extensive experiments show that DivAvatar is highly versatile in generating avatars of diverse appearances.