 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionCom: Automatic and Motion-Aware Image Composition with LLM and Video Diffusion Prior
Paper and Code
Sep 16, 2024
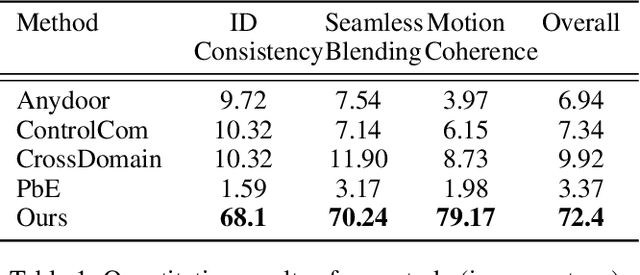


This work presents MotionCom, a training-free motion-aware diffusion based image composition, enabling automatic and seamless integration of target objects into new scenes with dynamically coherent results without finetuning or optimization. Traditional approaches in this area suffer from two significant limitations: they require manual planning for object placement and often generate static compositions lacking motion realism. MotionCom addresses these issues by utilizing a Large Vision Language Model (LVLM) for intelligent planning, and a Video Diffusion prior for motion-infused image synthesis, streamlining the composition process. Our multi-modal Chain-of-Thought (CoT) prompting with LVLM automates the strategic placement planning of foreground objects, considering their potential motion and interaction within the scenes. Complementing this, we propose a novel method MotionPaint to distill motion-aware information from pretrained video diffusion models in the generation phase, ensuring that these objects are not only seamlessly integrated but also endowed with realistic motion. Extensive quantitative and qualitative results highlight MotionCom's superiority, showcasing its efficiency in streamlining the planning process and its capability to produce compositions that authentically depict motion and interaction.