 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel View Extrapolation with Video Diffusion Priors
Nov 21, 2024The field of novel view synthesis has made significant strides thanks to the development of radiance field methods. However, most radiance field techniques are far better at novel view interpolation than novel view extrapolation where the synthesis novel views are far beyond the observed training views. We design ViewExtrapolator, a novel view synthesis approach that leverages the generative priors of Stable Video Diffusion (SVD) for realistic novel view extrapolation. By redesigning the SVD denoising process, ViewExtrapolator refines the artifact-prone views rendered by radiance fields, greatly enhancing the clarity and realism of the synthesized novel views. ViewExtrapolator is a generic novel view extrapolator that can work with different types of 3D rendering such as views rendered from point clouds when only a single view or monocular video is available. Additionally, ViewExtrapolator requires no fine-tuning of SVD, making it both data-efficient and computation-efficient. Extensive experiments demonstrate the superiority of ViewExtrapolator in novel view extrapolation. Project page: \url{https://kunhao-liu.github.io/ViewExtrapolator/}.
StyleGaussian: Instant 3D Style Transfer with Gaussian Splatting
Mar 12, 2024



We introduce StyleGaussian, a novel 3D style transfer technique that allows instant transfer of any image's style to a 3D scene at 10 frames per second (fps). Leveraging 3D Gaussian Splatting (3DGS), StyleGaussian achieves style transfer without compromising its real-time rendering ability and multi-view consistency. It achieves instant style transfer with three steps: embedding, transfer, and decoding. Initially, 2D VGG scene features are embedded into reconstructed 3D Gaussians. Next, the embedded features are transformed according to a reference style image. Finally, the transformed features are decoded into the stylized RGB. StyleGaussian has two novel designs. The first is an efficient feature rendering strategy that first renders low-dimensional features and then maps them into high-dimensional features while embedding VGG features. It cuts the memory consumption significantly and enables 3DGS to render the high-dimensional memory-intensive features. The second is a K-nearest-neighbor-based 3D CNN. Working as the decoder for the stylized features, it eliminates the 2D CNN operations that compromise strict multi-view consistency. Extensive experiments show that StyleGaussian achieves instant 3D stylization with superior stylization quality while preserving real-time rendering and strict multi-view consistency. Project page: https://kunhao-liu.github.io/StyleGaussian/
DivAvatar: Diverse 3D Avatar Generation with a Single Prompt
Feb 27, 2024



Text-to-Avatar generation has recently made significant strides due to advancements in diffusion models. However, most existing work remains constrained by limited diversity, producing avatars with subtle differences in appearance for a given text prompt. We design DivAvatar, a novel framework that generates diverse avatars, empowering 3D creatives with a multitude of distinct and richly varied 3D avatars from a single text prompt. Different from most existing work that exploits scene-specific 3D representations such as NeRF, DivAvatar finetunes a 3D generative model (i.e., EVA3D), allowing diverse avatar generation from simply noise sampling in inference time. DivAvatar has two key designs that help achieve generation diversity and visual quality. The first is a noise sampling technique during training phase which is critical in generating diverse appearances. The second is a semantic-aware zoom mechanism and a novel depth loss, the former producing appearances of high textual fidelity by separate fine-tuning of specific body parts and the latter improving geometry quality greatly by smoothing the generated mesh in the features space. Extensive experiments show that DivAvatar is highly versatile in generating avatars of diverse appearances.
AI-Generated Images as Data Source: The Dawn of Synthetic Era
Oct 09, 2023
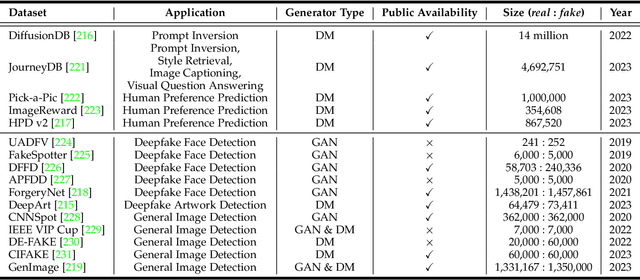


The advancement of visual intelligence is intrinsically tethered to the availability of data. In parallel, generative Artificial Intelligence (AI) has unlocked the potential to create synthetic images that closely resemble real-world photographs, which prompts a compelling inquiry: how visual intelligence benefit from the advance of generative AI? This paper explores the innovative concept of harnessing these AI-generated images as a new data source, reshaping traditional model paradigms in visual intelligence. In contrast to real data, AI-generated data sources exhibit remarkable advantages, including unmatched abundance and scalability, the rapid generation of vast datasets, and the effortless simulation of edge cases. Built on the success of generative AI models, we examines the potential of their generated data in a range of applications, from training machine learning models to simulating scenarios for computational modeling, testing, and validation. We probe the technological foundations that support this groundbreaking use of generative AI, engaging in an in-depth discussion on the ethical, legal, and practical considerations that accompany this transformative paradigm shift. Through an exhaustive survey of current technologies and applications, this paper presents a comprehensive view of the synthetic era in visual intelligence. A project associated with this paper can be found at https://github.com/mwxely/AIGS .
Pose-Free Neural Radiance Fields via Implicit Pose Regularization
Aug 29, 2023
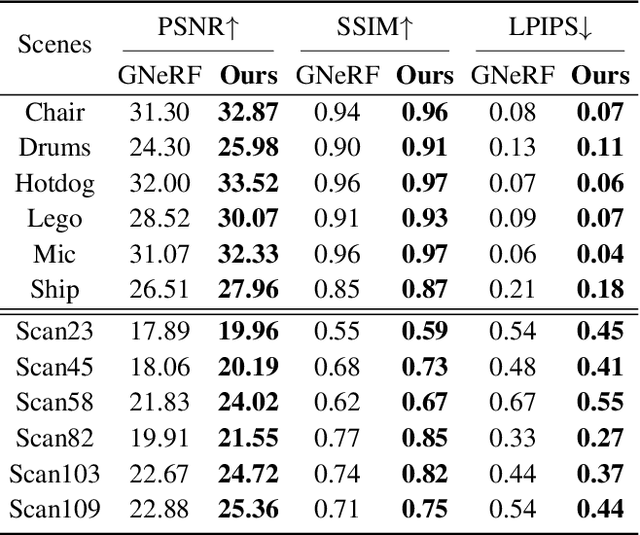
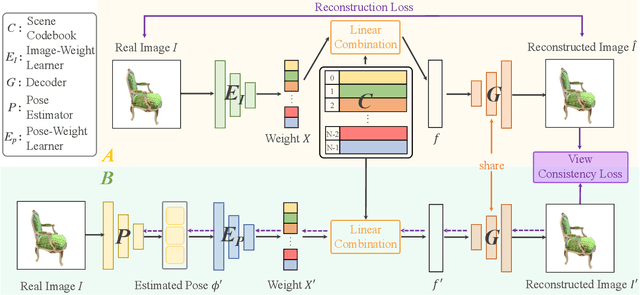

Pose-free neural radiance fields (NeRF) aim to train NeRF with unposed multi-view images and it has achieved very impressive success in recent years. Most existing works share the pipeline of training a coarse pose estimator with rendered images at first, followed by a joint optimization of estimated poses and neural radiance field. However, as the pose estimator is trained with only rendered images, the pose estimation is usually biased or inaccurate for real images due to the domain gap between real images and rendered images, leading to poor robustness for the pose estimation of real images and further local minima in joint optimization. We design IR-NeRF, an innovative pose-free NeRF that introduces implicit pose regularization to refine pose estimator with unposed real images and improve the robustness of the pose estimation for real images. With a collection of 2D images of a specific scene, IR-NeRF constructs a scene codebook that stores scene features and captures the scene-specific pose distribution implicitly as priors. Thus, the robustness of pose estimation can be promoted with the scene priors according to the rationale that a 2D real image can be well reconstructed from the scene codebook only when its estimated pose lies within the pose distribution. Extensive experiments show that IR-NeRF achieves superior novel view synthesis and outperforms the state-of-the-art consistently across multiple synthetic and real datasets.
3D Open-vocabulary Segmentation with Foundation Models
May 24, 2023



Open-vocabulary segmentation of 3D scenes is a fundamental function of human perception and thus a crucial objective in computer vision research. However, this task is heavily impeded by the lack of large-scale and diverse 3D open-vocabulary segmentation datasets for training robust and generalizable models. Distilling knowledge from pre-trained 2D open-vocabulary segmentation models helps but it compromises the open-vocabulary feature significantly as the 2D models are mostly finetuned with close-vocabulary datasets. We tackle the challenges in 3D open-vocabulary segmentation by exploiting the open-vocabulary multimodal knowledge and object reasoning capability of pre-trained foundation models CLIP and DINO, without necessitating any fine-tuning. Specifically, we distill open-vocabulary visual and textual knowledge from CLIP into a neural radiance field (NeRF) which effectively lifts 2D features into view-consistent 3D segmentation. Furthermore, we introduce the Relevancy-Distribution Alignment loss and Feature-Distribution Alignment loss to respectively mitigate the ambiguities of CLIP features and distill precise object boundaries from DINO features, eliminating the need for segmentation annotations during training. Extensive experiments show that our method even outperforms fully supervised models trained with segmentation annotations, suggesting that 3D open-vocabulary segmentation can be effectively learned from 2D images and text-image pairs.
StyleRF: Zero-shot 3D Style Transfer of Neural Radiance Fields
Mar 24, 2023
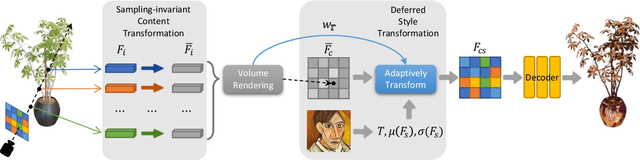
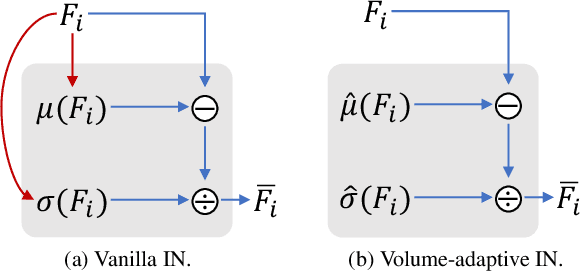
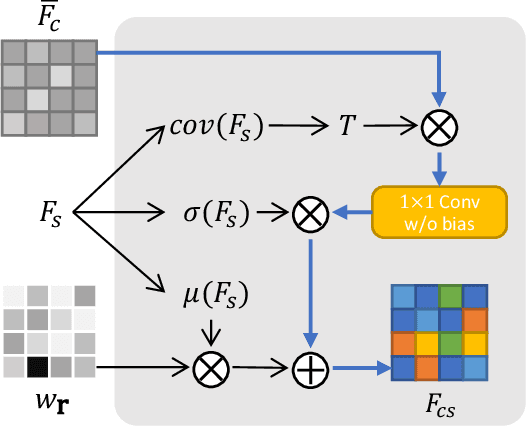
3D style transfer aims to render stylized novel views of a 3D scene with multi-view consistency. However, most existing work suffers from a three-way dilemma over accurate geometry reconstruction, high-quality stylization, and being generalizable to arbitrary new styles. We propose StyleRF (Style Radiance Fields), an innovative 3D style transfer technique that resolves the three-way dilemma by performing style transformation within the feature space of a radiance field. StyleRF employs an explicit grid of high-level features to represent 3D scenes, with which high-fidelity geometry can be reliably restored via volume rendering. In addition, it transforms the grid features according to the reference style which directly leads to high-quality zero-shot style transfer. StyleRF consists of two innovative designs. The first is sampling-invariant content transformation that makes the transformation invariant to the holistic statistics of the sampled 3D points and accordingly ensures multi-view consistency. The second is deferred style transformation of 2D feature maps which is equivalent to the transformation of 3D points but greatly reduces memory footprint without degrading multi-view consistency. Extensive experiments show that StyleRF achieves superior 3D stylization quality with precise geometry reconstruction and it can generalize to various new styles in a zero-shot manner.