 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Hand Grasp Generation for HOI and Efficient Evaluation Methods
Jan 27, 2025Controllable affordance Hand-Object Interaction (HOI) generation has become an increasingly important area of research in computer vision. In HOI generation, the hand grasp generation is a crucial step for effectively controlling the geometry of the hand. Current hand grasp generation methods rely on 3D information for both the hand and the object. In addition, these methods lack controllability concerning the hand's location and orientation. We treat the hand pose as the discrete graph structure and exploit the geometric priors. It is well established that higher order contextual dependency among the points improves the quality of the results in general. We propose a framework of higher order geometric representations (HOR's) inspired by spectral graph theory and vector algebra to improve the quality of generated hand poses. We demonstrate the effectiveness of our proposed HOR's in devising a controllable novel diffusion method (based on 2D information) for hand grasp generation that outperforms the state of the art (SOTA). Overcoming the limitations of existing methods: like lacking of controllability and dependency on 3D information. Once we have the generated pose, it is very natural to evaluate them using a metric. Popular metrics like FID and MMD are biased and inefficient for evaluating the generated hand poses. Using our proposed HOR's, we introduce an efficient and stable framework of evaluation metrics for grasp generation methods, addressing inefficiencies and biases in FID and MMD.
Pose-Free Neural Radiance Fields via Implicit Pose Regularization
Aug 29, 2023
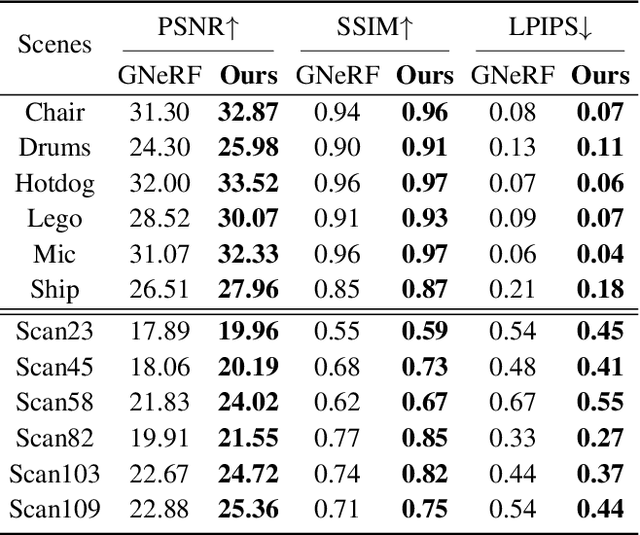
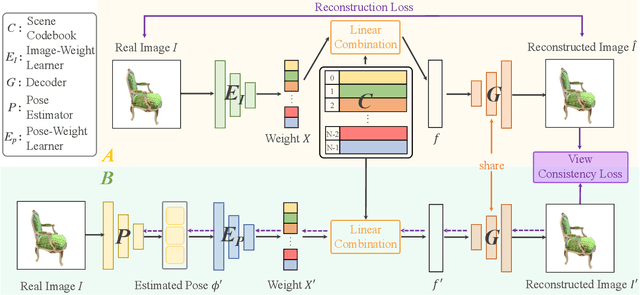

Pose-free neural radiance fields (NeRF) aim to train NeRF with unposed multi-view images and it has achieved very impressive success in recent years. Most existing works share the pipeline of training a coarse pose estimator with rendered images at first, followed by a joint optimization of estimated poses and neural radiance field. However, as the pose estimator is trained with only rendered images, the pose estimation is usually biased or inaccurate for real images due to the domain gap between real images and rendered images, leading to poor robustness for the pose estimation of real images and further local minima in joint optimization. We design IR-NeRF, an innovative pose-free NeRF that introduces implicit pose regularization to refine pose estimator with unposed real images and improve the robustness of the pose estimation for real images. With a collection of 2D images of a specific scene, IR-NeRF constructs a scene codebook that stores scene features and captures the scene-specific pose distribution implicitly as priors. Thus, the robustness of pose estimation can be promoted with the scene priors according to the rationale that a 2D real image can be well reconstructed from the scene codebook only when its estimated pose lies within the pose distribution. Extensive experiments show that IR-NeRF achieves superior novel view synthesis and outperforms the state-of-the-art consistently across multiple synthetic and real datasets.
POCE: Pose-Controllable Expression Editing
Apr 18, 2023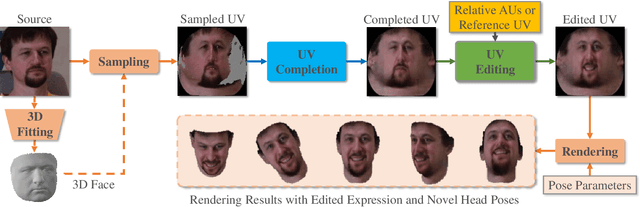



Facial expression editing has attracted increasing attention with the advance of deep neural networks in recent years. However, most existing methods suffer from compromised editing fidelity and limited usability as they either ignore pose variations (unrealistic editing) or require paired training data (not easy to collect) for pose controls. This paper presents POCE, an innovative pose-controllable expression editing network that can generate realistic facial expressions and head poses simultaneously with just unpaired training images. POCE achieves the more accessible and realistic pose-controllable expression editing by mapping face images into UV space, where facial expressions and head poses can be disentangled and edited separately. POCE has two novel designs. The first is self-supervised UV completion that allows to complete UV maps sampled under different head poses, which often suffer from self-occlusions and missing facial texture. The second is weakly-supervised UV editing that allows to generate new facial expressions with minimal modification of facial identity, where the synthesized expression could be controlled by either an expression label or directly transplanted from a reference UV map via feature transfer. Extensive experiments show that POCE can learn from unpaired face images effectively, and the learned model can generate realistic and high-fidelity facial expressions under various new poses.
Audio-Driven Talking Face Generation with Diverse yet Realistic Facial Animations
Apr 18, 2023



Audio-driven talking face generation, which aims to synthesize talking faces with realistic facial animations (including accurate lip movements, vivid facial expression details and natural head poses) corresponding to the audio, has achieved rapid progress in recent years. However, most existing work focuses on generating lip movements only without handling the closely correlated facial expressions, which degrades the realism of the generated faces greatly. This paper presents DIRFA, a novel method that can generate talking faces with diverse yet realistic facial animations from the same driving audio. To accommodate fair variation of plausible facial animations for the same audio, we design a transformer-based probabilistic mapping network that can model the variational facial animation distribution conditioned upon the input audio and autoregressively convert the audio signals into a facial animation sequence. In addition, we introduce a temporally-biased mask into the mapping network, which allows to model the temporal dependency of facial animations and produce temporally smooth facial animation sequence. With the generated facial animation sequence and a source image, photo-realistic talking faces can be synthesized with a generic generation network. Extensive experiments show that DIRFA can generate talking faces with realistic facial animations effectively.
Face Transformer: Towards High Fidelity and Accurate Face Swapping
Apr 05, 2023Face swapping aims to generate swapped images that fuse the identity of source faces and the attributes of target faces. Most existing works address this challenging task through 3D modelling or generation using generative adversarial networks (GANs), but 3D modelling suffers from limited reconstruction accuracy and GANs often struggle in preserving subtle yet important identity details of source faces (e.g., skin colors, face features) and structural attributes of target faces (e.g., face shapes, facial expressions). This paper presents Face Transformer, a novel face swapping network that can accurately preserve source identities and target attributes simultaneously in the swapped face images. We introduce a transformer network for the face swapping task, which learns high-quality semantic-aware correspondence between source and target faces and maps identity features of source faces to the corresponding region in target faces. The high-quality semantic-aware correspondence enables smooth and accurate transfer of source identity information with minimal modification of target shapes and expressions. In addition, our Face Transformer incorporates a multi-scale transformation mechanism for preserving the rich fine facial details. Extensive experiments show that our Face Transformer achieves superior face swapping performance qualitatively and quantitatively.
Latent Multi-Relation Reasoning for GAN-Prior based Image Super-Resolution
Aug 04, 2022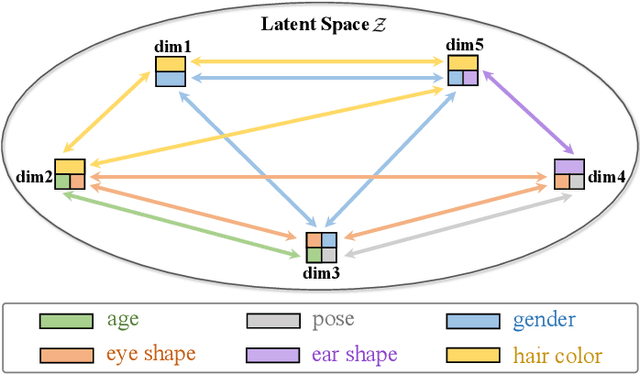
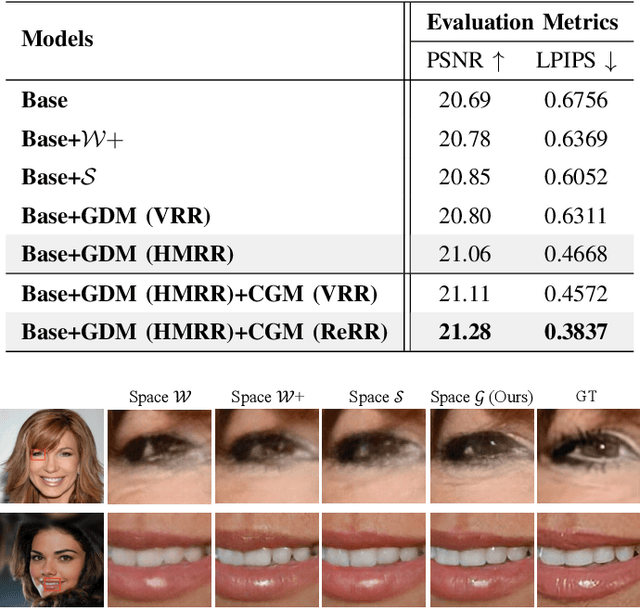


Recently, single image super-resolution (SR) under large scaling factors has witnessed impressive progress by introducing pre-trained generative adversarial networks (GANs) as priors. However, most GAN-Priors based SR methods are constrained by an attribute disentanglement problem in inverted latent codes which directly leads to mismatches of visual attributes in the generator layers and further degraded reconstruction. In addition, stochastic noises fed to the generator are employed for unconditional detail generation, which tends to produce unfaithful details that compromise the fidelity of the generated SR image. We design LAREN, a LAtent multi-Relation rEasoNing technique that achieves superb large-factor SR through graph-based multi-relation reasoning in latent space. LAREN consists of two innovative designs. The first is graph-based disentanglement that constructs a superior disentangled latent space via hierarchical multi-relation reasoning. The second is graph-based code generation that produces image-specific codes progressively via recursive relation reasoning which enables prior GANs to generate desirable image details. Extensive experiments show that LAREN achieves superior large-factor image SR and outperforms the state-of-the-art consistently across multiple benchmarks.
Auto-regressive Image Synthesis with Integrated Quantization
Jul 21, 2022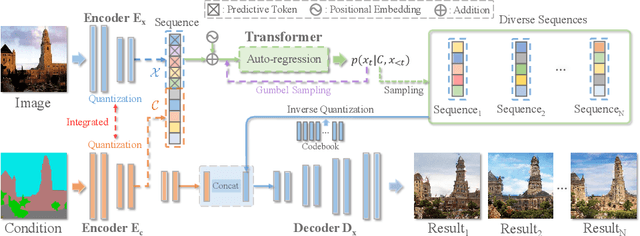

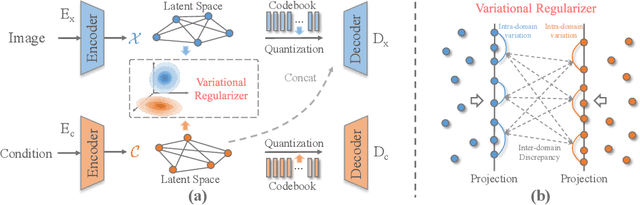

Deep generative models have achieved conspicuous progress in realistic image synthesis with multifarious conditional inputs, while generating diverse yet high-fidelity images remains a grand challenge in conditional image generation. This paper presents a versatile framework for conditional image generation which incorporates the inductive bias of CNNs and powerful sequence modeling of auto-regression that naturally leads to diverse image generation. Instead of independently quantizing the features of multiple domains as in prior research, we design an integrated quantization scheme with a variational regularizer that mingles the feature discretization in multiple domains, and markedly boosts the auto-regressive modeling performance. Notably, the variational regularizer enables to regularize feature distributions in incomparable latent spaces by penalizing the intra-domain variations of distributions. In addition, we design a Gumbel sampling strategy that allows to incorporate distribution uncertainty into the auto-regressive training procedure. The Gumbel sampling substantially mitigates the exposure bias that often incurs misalignment between the training and inference stages and severely impairs the inference performance. Extensive experiments over multiple conditional image generation tasks show that our method achieves superior diverse image generation performance qualitatively and quantitatively as compared with the state-of-the-art.
Towards Counterfactual Image Manipulation via CLIP
Jul 12, 2022
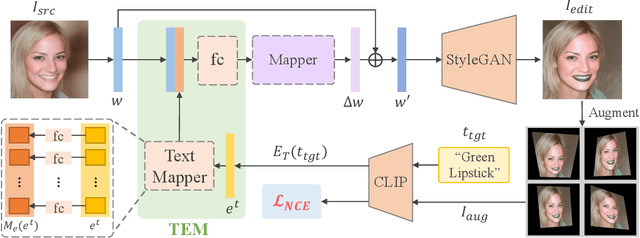
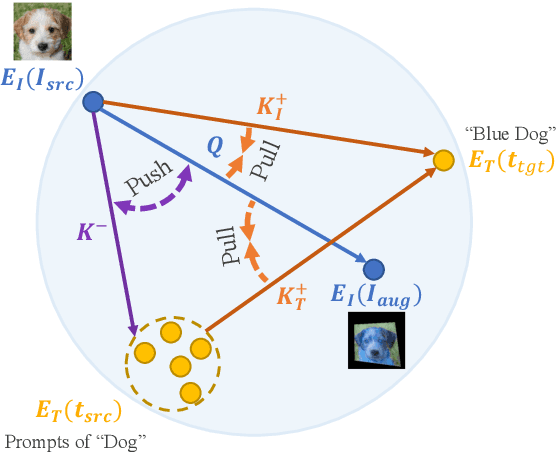

Leveraging StyleGAN's expressivity and its disentangled latent codes, existing methods can achieve realistic editing of different visual attributes such as age and gender of facial images. An intriguing yet challenging problem arises: Can generative models achieve counterfactual editing against their learnt priors? Due to the lack of counterfactual samples in natural datasets, we investigate this problem in a text-driven manner with Contrastive-Language-Image-Pretraining (CLIP), which can offer rich semantic knowledge even for various counterfactual concepts. Different from in-domain manipulation, counterfactual manipulation requires more comprehensive exploitation of semantic knowledge encapsulated in CLIP as well as more delicate handling of editing directions for avoiding being stuck in local minimum or undesired editing. To this end, we design a novel contrastive loss that exploits predefined CLIP-space directions to guide the editing toward desired directions from different perspectives. In addition, we design a simple yet effective scheme that explicitly maps CLIP embeddings (of target text) to the latent space and fuses them with latent codes for effective latent code optimization and accurate editing. Extensive experiments show that our design achieves accurate and realistic editing while driving by target texts with various counterfactual concepts.
VMRF: View Matching Neural Radiance Fields
Jul 06, 2022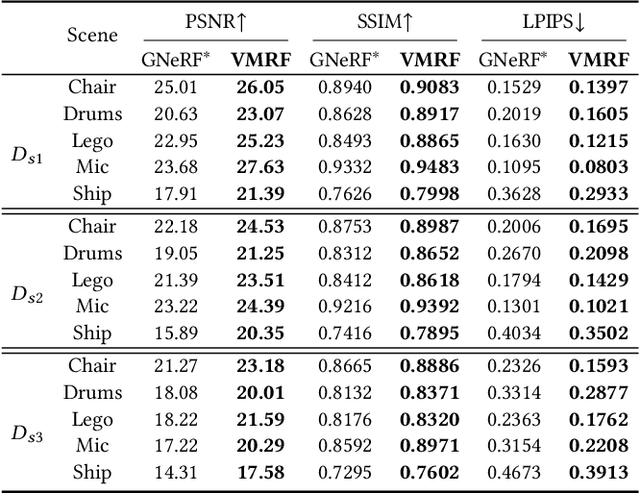

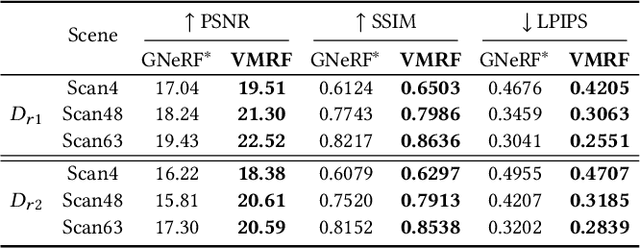

Neural Radiance Fields (NeRF) have demonstrated very impressive performance in novel view synthesis via implicitly modelling 3D representations from multi-view 2D images. However, most existing studies train NeRF models with either reasonable camera pose initialization or manually-crafted camera pose distributions which are often unavailable or hard to acquire in various real-world data. We design VMRF, an innovative view matching NeRF that enables effective NeRF training without requiring prior knowledge in camera poses or camera pose distributions. VMRF introduces a view matching scheme, which exploits unbalanced optimal transport to produce a feature transport plan for mapping a rendered image with randomly initialized camera pose to the corresponding real image. With the feature transport plan as the guidance, a novel pose calibration technique is designed which rectifies the initially randomized camera poses by predicting relative pose transformations between the pair of rendered and real images. Extensive experiments over a number of synthetic and real datasets show that the proposed VMRF outperforms the state-of-the-art qualitatively and quantitatively by large margins.
Marginal Contrastive Correspondence for Guided Image Generation
Apr 01, 2022

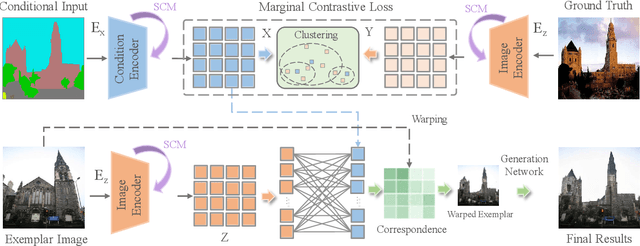

Exemplar-based image translation establishes dense correspondences between a conditional input and an exemplar (from two different domains) for leveraging detailed exemplar styles to achieve realistic image translation. Existing work builds the cross-domain correspondences implicitly by minimizing feature-wise distances across the two domains. Without explicit exploitation of domain-invariant features, this approach may not reduce the domain gap effectively which often leads to sub-optimal correspondences and image translation. We design a Marginal Contrastive Learning Network (MCL-Net) that explores contrastive learning to learn domain-invariant features for realistic exemplar-based image translation. Specifically, we design an innovative marginal contrastive loss that guides to establish dense correspondences explicitly. Nevertheless, building correspondence with domain-invariant semantics alone may impair the texture patterns and lead to degraded texture generation. We thus design a Self-Correlation Map (SCM) that incorporates scene structures as auxiliary information which improves the built correspondences substantially. Quantitative and qualitative experiments on multifarious image translation tasks show that the proposed method outperforms the state-of-the-art consistently.