 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrend-Aware Supervision: On Learning Invariance for Semi-Supervised Facial Action Unit Intensity Estimation
Mar 11, 2025



With the increasing need for facial behavior analysis, semi-supervised AU intensity estimation using only keyframe annotations has emerged as a practical and effective solution to relieve the burden of annotation. However, the lack of annotations makes the spurious correlation problem caused by AU co-occurrences and subject variation much more prominent, leading to non-robust intensity estimation that is entangled among AUs and biased among subjects. We observe that trend information inherent in keyframe annotations could act as extra supervision and raising the awareness of AU-specific facial appearance changing trends during training is the key to learning invariant AU-specific features. To this end, we propose \textbf{T}rend-\textbf{A}ware \textbf{S}upervision (TAS), which pursues three kinds of trend awareness, including intra-trend ranking awareness, intra-trend speed awareness, and inter-trend subject awareness. TAS alleviates the spurious correlation problem by raising trend awareness during training to learn AU-specific features that represent the corresponding facial appearance changes, to achieve intensity estimation invariance. Experiments conducted on two commonly used AU benchmark datasets, BP4D and DISFA, show the effectiveness of each kind of awareness. And under trend-aware supervision, the performance can be improved without extra computational or storage costs during inference.
Perception-as-Control: Fine-grained Controllable Image Animation with 3D-aware Motion Representation
Jan 09, 2025



Motion-controllable image animation is a fundamental task with a wide range of potential applications. Recent works have made progress in controlling camera or object motion via various motion representations, while they still struggle to support collaborative camera and object motion control with adaptive control granularity. To this end, we introduce 3D-aware motion representation and propose an image animation framework, called Perception-as-Control, to achieve fine-grained collaborative motion control. Specifically, we construct 3D-aware motion representation from a reference image, manipulate it based on interpreted user intentions, and perceive it from different viewpoints. In this way, camera and object motions are transformed into intuitive, consistent visual changes. Then, the proposed framework leverages the perception results as motion control signals, enabling it to support various motion-related video synthesis tasks in a unified and flexible way. Experiments demonstrate the superiority of the proposed framework. For more details and qualitative results, please refer to our project webpage: https://chen-yingjie.github.io/projects/Perception-as-Control.
I2CANSAY:Inter-Class Analogical Augmentation and Intra-Class Significance Analysis for Non-Exemplar Online Task-Free Continual Learning
Apr 21, 2024



Online task-free continual learning (OTFCL) is a more challenging variant of continual learning which emphasizes the gradual shift of task boundaries and learns in an online mode. Existing methods rely on a memory buffer composed of old samples to prevent forgetting. However,the use of memory buffers not only raises privacy concerns but also hinders the efficient learning of new samples. To address this problem, we propose a novel framework called I2CANSAY that gets rid of the dependence on memory buffers and efficiently learns the knowledge of new data from one-shot samples. Concretely, our framework comprises two main modules. Firstly, the Inter-Class Analogical Augmentation (ICAN) module generates diverse pseudo-features for old classes based on the inter-class analogy of feature distributions for different new classes, serving as a substitute for the memory buffer. Secondly, the Intra-Class Significance Analysis (ISAY) module analyzes the significance of attributes for each class via its distribution standard deviation, and generates the importance vector as a correction bias for the linear classifier, thereby enhancing the capability of learning from new samples. We run our experiments on four popular image classification datasets: CoRe50, CIFAR-10, CIFAR-100, and CUB-200, our approach outperforms the prior state-of-the-art by a large margin.
LiDAR-Forest Dataset: LiDAR Point Cloud Simulation Dataset for Forestry Application
Feb 15, 2024


The popularity of LiDAR devices and sensor technology has gradually empowered users from autonomous driving to forest monitoring, and research on 3D LiDAR has made remarkable progress over the years. Unlike 2D images, whose focused area is visible and rich in texture information, understanding the point distribution can help companies and researchers find better ways to develop point-based 3D applications. In this work, we contribute an unreal-based LiDAR simulation tool and a 3D simulation dataset named LiDAR-Forest, which can be used by various studies to evaluate forest reconstruction, tree DBH estimation, and point cloud compression for easy visualization. The simulation is customizable in tree species, LiDAR types and scene generation, with low cost and high efficiency.
Towards Unbiased Label Distribution Learning for Facial Pose Estimation Using Anisotropic Spherical Gaussian
Aug 19, 2022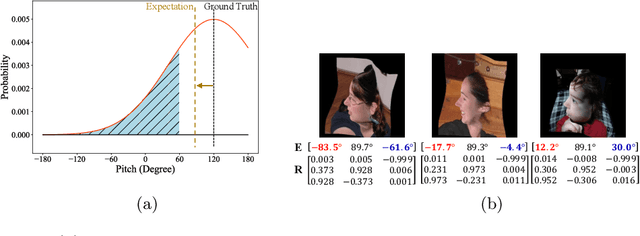
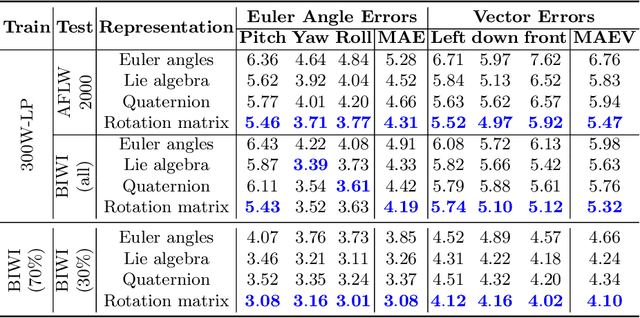
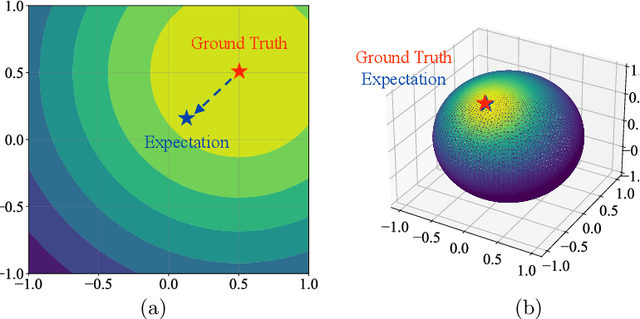
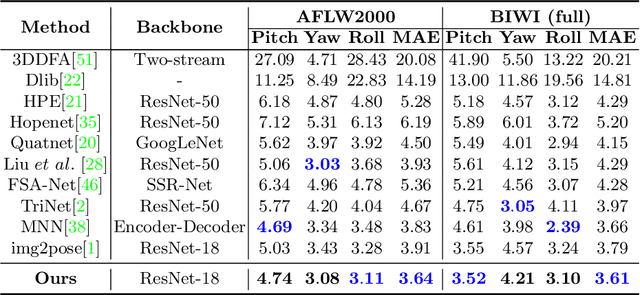
Facial pose estimation refers to the task of predicting face orientation from a single RGB image. It is an important research topic with a wide range of applications in computer vision. Label distribution learning (LDL) based methods have been recently proposed for facial pose estimation, which achieve promising results. However, there are two major issues in existing LDL methods. First, the expectations of label distributions are biased, leading to a biased pose estimation. Second, fixed distribution parameters are applied for all learning samples, severely limiting the model capability. In this paper, we propose an Anisotropic Spherical Gaussian (ASG)-based LDL approach for facial pose estimation. In particular, our approach adopts the spherical Gaussian distribution on a unit sphere which constantly generates unbiased expectation. Meanwhile, we introduce a new loss function that allows the network to learn the distribution parameter for each learning sample flexibly. Extensive experimental results show that our method sets new state-of-the-art records on AFLW2000 and BIWI datasets.
On Mitigating Hard Clusters for Face Clustering
Jul 25, 2022
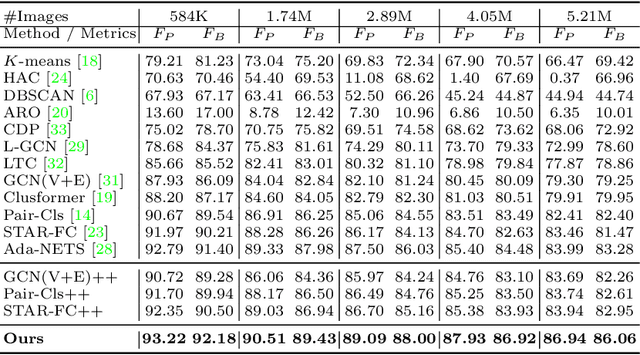
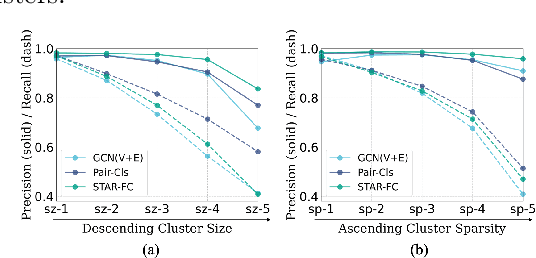
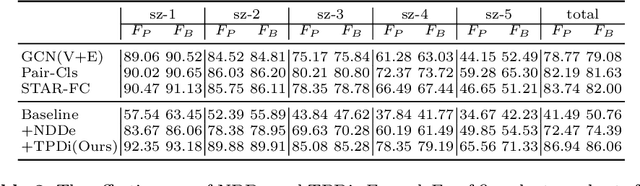
Face clustering is a promising way to scale up face recognition systems using large-scale unlabeled face images. It remains challenging to identify small or sparse face image clusters that we call hard clusters, which is caused by the heterogeneity, \ie, high variations in size and sparsity, of the clusters. Consequently, the conventional way of using a uniform threshold (to identify clusters) often leads to a terrible misclassification for the samples that should belong to hard clusters. We tackle this problem by leveraging the neighborhood information of samples and inferring the cluster memberships (of samples) in a probabilistic way. We introduce two novel modules, Neighborhood-Diffusion-based Density (NDDe) and Transition-Probability-based Distance (TPDi), based on which we can simply apply the standard Density Peak Clustering algorithm with a uniform threshold. Our experiments on multiple benchmarks show that each module contributes to the final performance of our method, and by incorporating them into other advanced face clustering methods, these two modules can boost the performance of these methods to a new state-of-the-art. Code is available at: https://github.com/echoanran/On-Mitigating-Hard-Clusters.
Causal Intervention for Subject-Deconfounded Facial Action Unit Recognition
Apr 17, 2022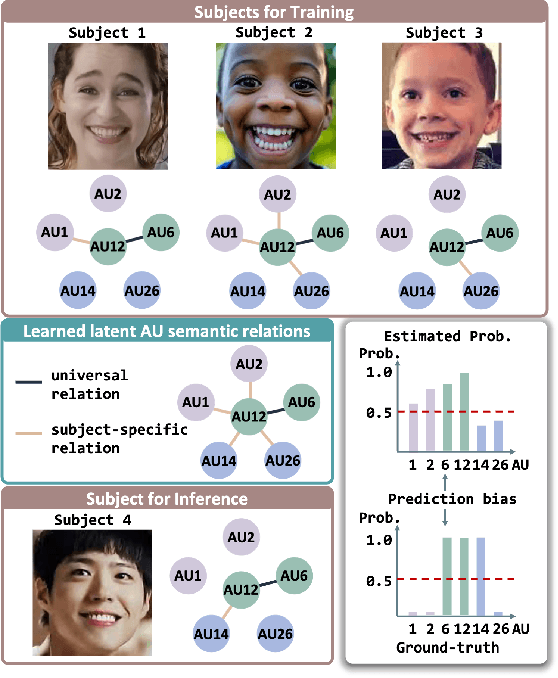
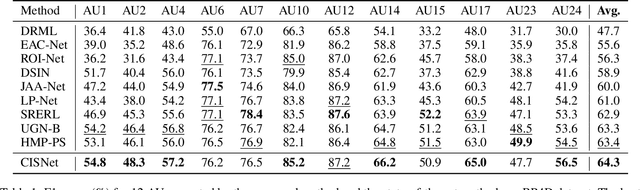
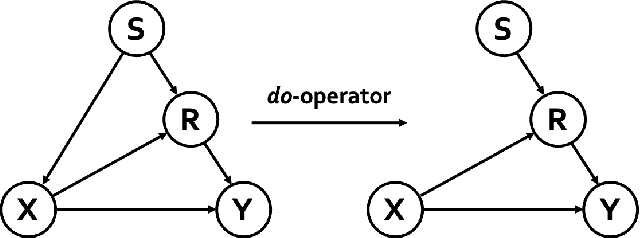
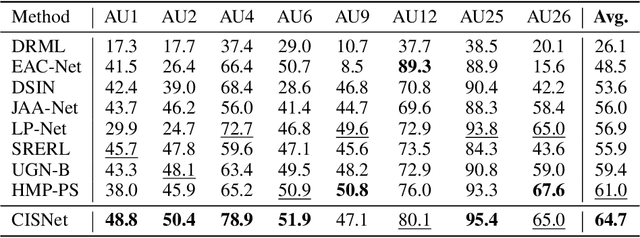
Subject-invariant facial action unit (AU) recognition remains challenging for the reason that the data distribution varies among subjects. In this paper, we propose a causal inference framework for subject-invariant facial action unit recognition. To illustrate the causal effect existing in AU recognition task, we formulate the causalities among facial images, subjects, latent AU semantic relations, and estimated AU occurrence probabilities via a structural causal model. By constructing such a causal diagram, we clarify the causal effect among variables and propose a plug-in causal intervention module, CIS, to deconfound the confounder \emph{Subject} in the causal diagram. Extensive experiments conducted on two commonly used AU benchmark datasets, BP4D and DISFA, show the effectiveness of our CIS, and the model with CIS inserted, CISNet, has achieved state-of-the-art performance.
EventFormer: AU Event Transformer for Facial Action Unit Event Detection
Mar 12, 2022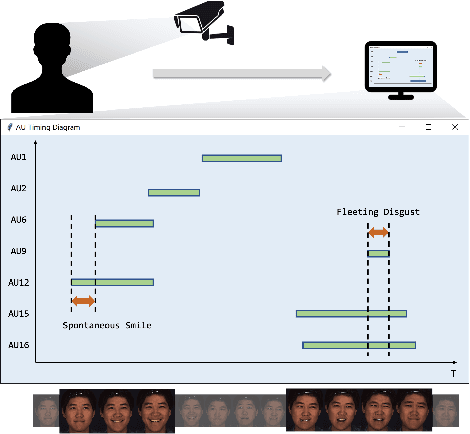
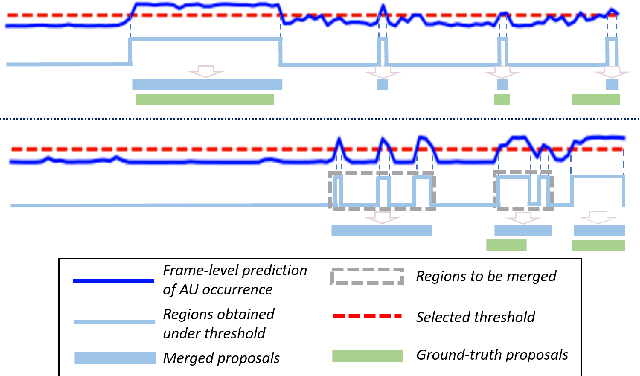
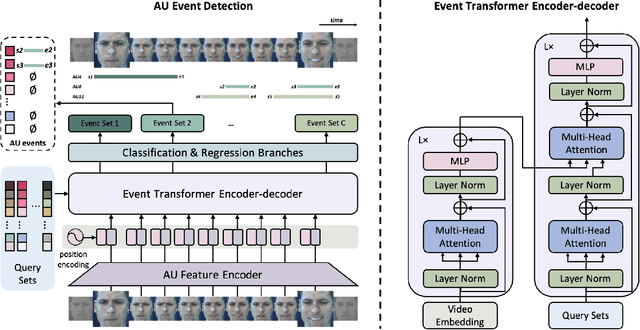
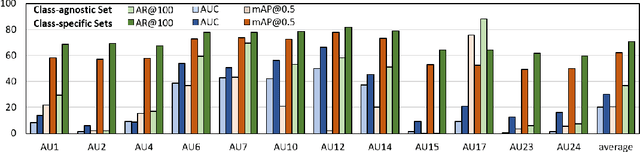
Facial action units (AUs) play an indispensable role in human emotion analysis. We observe that although AU-based high-level emotion analysis is urgently needed by real-world applications, frame-level AU results provided by previous works cannot be directly used for such analysis. Moreover, as AUs are dynamic processes, the utilization of global temporal information is important but has been gravely ignored in the literature. To this end, we propose EventFormer for AU event detection, which is the first work directly detecting AU events from a video sequence by viewing AU event detection as a multiple class-specific sets prediction problem. Extensive experiments conducted on a commonly used AU benchmark dataset, BP4D, show the superiority of EventFormer under suitable metrics.
DG-Labeler and DGL-MOTS Dataset: Boost the Autonomous Driving Perception
Oct 15, 2021
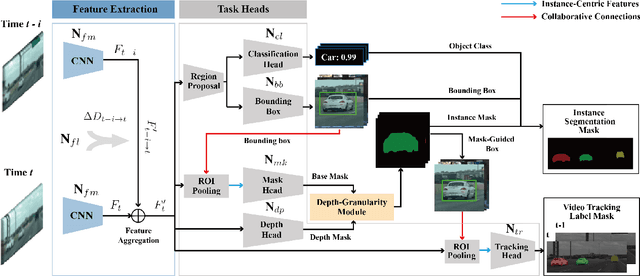
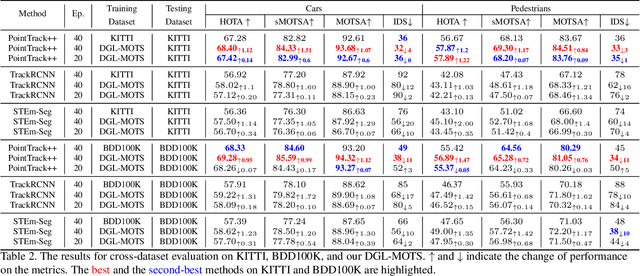
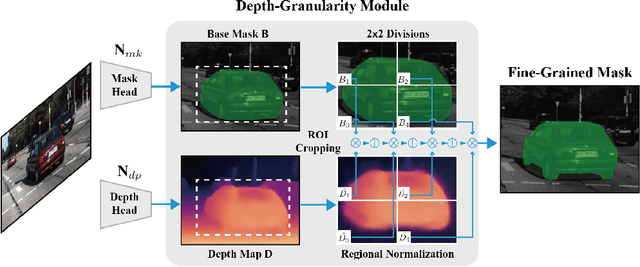
Multi-object tracking and segmentation (MOTS) is a critical task for autonomous driving applications. The existing MOTS studies face two critical challenges: 1) the published datasets inadequately capture the real-world complexity for network training to address various driving settings; 2) the working pipeline annotation tool is under-studied in the literature to improve the quality of MOTS learning examples. In this work, we introduce the DG-Labeler and DGL-MOTS dataset to facilitate the training data annotation for the MOTS task and accordingly improve network training accuracy and efficiency. DG-Labeler uses the novel Depth-Granularity Module to depict the instance spatial relations and produce fine-grained instance masks. Annotated by DG-Labeler, our DGL-MOTS dataset exceeds the prior effort (i.e., KITTI MOTS and BDD100K) in data diversity, annotation quality, and temporal representations. Results on extensive cross-dataset evaluations indicate significant performance improvements for several state-of-the-art methods trained on our DGL-MOTS dataset. We believe our DGL-MOTS Dataset and DG-Labeler hold the valuable potential to boost the visual perception of future transportation.
Density-Based Clustering with Kernel Diffusion
Oct 14, 2021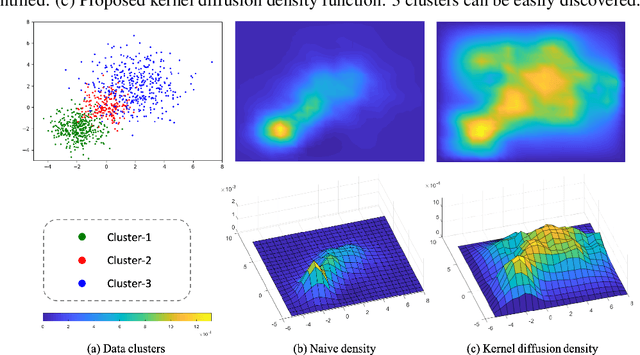
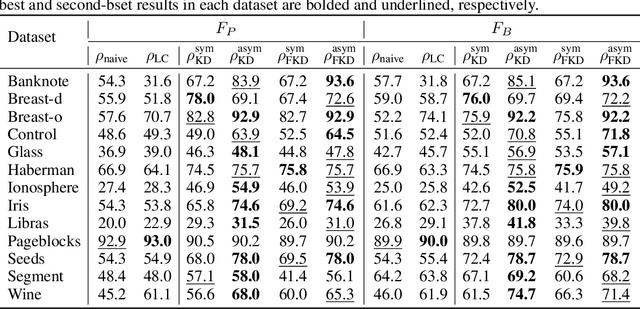
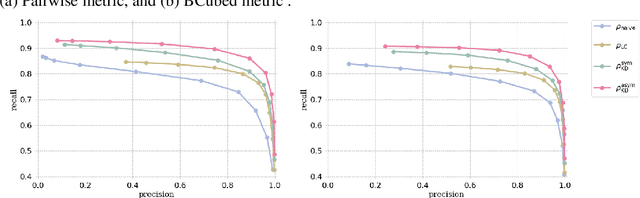

Finding a suitable density function is essential for density-based clustering algorithms such as DBSCAN and DPC. A naive density corresponding to the indicator function of a unit $d$-dimensional Euclidean ball is commonly used in these algorithms. Such density suffers from capturing local features in complex datasets. To tackle this issue, we propose a new kernel diffusion density function, which is adaptive to data of varying local distributional characteristics and smoothness. Furthermore, we develop a surrogate that can be efficiently computed in linear time and space and prove that it is asymptotically equivalent to the kernel diffusion density function. Extensive empirical experiments on benchmark and large-scale face image datasets show that the proposed approach not only achieves a significant improvement over classic density-based clustering algorithms but also outperforms the state-of-the-art face clustering methods by a large margin.