 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyEgg: Joint Implementation Selection and Scheduling for Hardware Synthesis using E-graphs
Nov 19, 2025Hardware synthesis from high-level descriptions remains fundamentally limited by the sequential optimization of interdependent design decisions. Current methodologies, including state-of-the-art high-level synthesis (HLS) tools, artificially separate implementation selection from scheduling, leading to suboptimal designs that cannot fully exploit modern FPGA heterogeneous architectures. Implementation selection is typically performed by ad-hoc pattern matching on operations, a process that does not consider the impact on scheduling. Subsequently, scheduling algorithms operate on fixed selection solutions with inaccurate delay estimates, which misses critical optimization opportunities from appropriately configured FPGA blocks like DSP slices. We present SkyEgg, a novel hardware synthesis framework that jointly optimizes implementation selection and scheduling using the e-graph data structure. Our key insight is that both algebraic transformations and hardware implementation choices can be uniformly represented as rewrite rules within an e-graph, modeling the complete design space of implementation candidates to be selected and scheduled together. First, SkyEgg constructs an e-graph from the input program. It then applies both algebraic and implementation rewrites through equality saturation. Finally, it formulates the joint optimization as a mixed-integer linear programming (MILP) problem on the saturated e-graph. We provide both exact MILP solving and an efficient ASAP heuristic for scalable synthesis. Our evaluation on benchmarks from diverse applications targeting Xilinx Kintex UltraScale+ FPGAs demonstrates that SkyEgg achieves an average speedup of 3.01x over Vitis HLS, with improvements up to 5.22x for complex expressions.
semi-PD: Towards Efficient LLM Serving via Phase-Wise Disaggregated Computation and Unified Storage
Apr 28, 2025Existing large language model (LLM) serving systems fall into two categories: 1) a unified system where prefill phase and decode phase are co-located on the same GPU, sharing the unified computational resource and storage, and 2) a disaggregated system where the two phases are disaggregated to different GPUs. The design of the disaggregated system addresses the latency interference and sophisticated scheduling issues in the unified system but leads to storage challenges including 1) replicated weights for both phases that prevent flexible deployment, 2) KV cache transfer overhead between the two phases, 3) storage imbalance that causes substantial wasted space of the GPU capacity, and 4) suboptimal resource adjustment arising from the difficulties in migrating KV cache. Such storage inefficiency delivers poor serving performance under high request rates. In this paper, we identify that the advantage of the disaggregated system lies in the disaggregated computation, i.e., partitioning the computational resource to enable the asynchronous computation of two phases. Thus, we propose a novel LLM serving system, semi-PD, characterized by disaggregated computation and unified storage. In semi-PD, we introduce a computation resource controller to achieve disaggregated computation at the streaming multi-processor (SM) level, and a unified memory manager to manage the asynchronous memory access from both phases. semi-PD has a low-overhead resource adjustment mechanism between the two phases, and a service-level objective (SLO) aware dynamic partitioning algorithm to optimize the SLO attainment. Compared to state-of-the-art systems, semi-PD maintains lower latency at higher request rates, reducing the average end-to-end latency per request by 1.27-2.58x on DeepSeek series models, and serves 1.55-1.72x more requests adhering to latency constraints on Llama series models.
Trend-Aware Supervision: On Learning Invariance for Semi-Supervised Facial Action Unit Intensity Estimation
Mar 11, 2025



With the increasing need for facial behavior analysis, semi-supervised AU intensity estimation using only keyframe annotations has emerged as a practical and effective solution to relieve the burden of annotation. However, the lack of annotations makes the spurious correlation problem caused by AU co-occurrences and subject variation much more prominent, leading to non-robust intensity estimation that is entangled among AUs and biased among subjects. We observe that trend information inherent in keyframe annotations could act as extra supervision and raising the awareness of AU-specific facial appearance changing trends during training is the key to learning invariant AU-specific features. To this end, we propose \textbf{T}rend-\textbf{A}ware \textbf{S}upervision (TAS), which pursues three kinds of trend awareness, including intra-trend ranking awareness, intra-trend speed awareness, and inter-trend subject awareness. TAS alleviates the spurious correlation problem by raising trend awareness during training to learn AU-specific features that represent the corresponding facial appearance changes, to achieve intensity estimation invariance. Experiments conducted on two commonly used AU benchmark datasets, BP4D and DISFA, show the effectiveness of each kind of awareness. And under trend-aware supervision, the performance can be improved without extra computational or storage costs during inference.
MCUBERT: Memory-Efficient BERT Inference on Commodity Microcontrollers
Oct 23, 2024



In this paper, we propose MCUBERT to enable language models like BERT on tiny microcontroller units (MCUs) through network and scheduling co-optimization. We observe the embedding table contributes to the major storage bottleneck for tiny BERT models. Hence, at the network level, we propose an MCU-aware two-stage neural architecture search algorithm based on clustered low-rank approximation for embedding compression. To reduce the inference memory requirements, we further propose a novel fine-grained MCU-friendly scheduling strategy. Through careful computation tiling and re-ordering as well as kernel design, we drastically increase the input sequence lengths supported on MCUs without any latency or accuracy penalty. MCUBERT reduces the parameter size of BERT-tiny and BERT-mini by 5.7$\times$ and 3.0$\times$ and the execution memory by 3.5$\times$ and 4.3$\times$, respectively. MCUBERT also achieves 1.5$\times$ latency reduction. For the first time, MCUBERT enables lightweight BERT models on commodity MCUs and processing more than 512 tokens with less than 256KB of memory.
Memory Matching is not Enough: Jointly Improving Memory Matching and Decoding for Video Object Segmentation
Sep 22, 2024Memory-based video object segmentation methods model multiple objects over long temporal-spatial spans by establishing memory bank, which achieve the remarkable performance. However, they struggle to overcome the false matching and are prone to lose critical information, resulting in confusion among different objects. In this paper, we propose an effective approach which jointly improving the matching and decoding stages to alleviate the false matching issue.For the memory matching stage, we present a cost aware mechanism that suppresses the slight errors for short-term memory and a shunted cross-scale matching for long-term memory which establish a wide filed matching spaces for various object scales. For the readout decoding stage, we implement a compensatory mechanism aims at recovering the essential information where missing at the matching stage. Our approach achieves the outstanding performance in several popular benchmarks (i.e., DAVIS 2016&2017 Val (92.4%&88.1%), and DAVIS 2017 Test (83.9%)), and achieves 84.8%&84.6% on YouTubeVOS 2018&2019 Val.
ToCoAD: Two-Stage Contrastive Learning for Industrial Anomaly Detection
Jul 01, 2024



Current unsupervised anomaly detection approaches perform well on public datasets but struggle with specific anomaly types due to the domain gap between pre-trained feature extractors and target-specific domains. To tackle this issue, this paper presents a two-stage training strategy, called \textbf{ToCoAD}. In the first stage, a discriminative network is trained by using synthetic anomalies in a self-supervised learning manner. This network is then utilized in the second stage to provide a negative feature guide, aiding in the training of the feature extractor through bootstrap contrastive learning. This approach enables the model to progressively learn the distribution of anomalies specific to industrial datasets, effectively enhancing its generalizability to various types of anomalies. Extensive experiments are conducted to demonstrate the effectiveness of our proposed two-stage training strategy, and our model produces competitive performance, achieving pixel-level AUROC scores of 98.21\%, 98.43\% and 97.70\% on MVTec AD, VisA and BTAD respectively.
AAT: Adapting Audio Transformer for Various Acoustics Recognition Tasks
Jan 19, 2024Recently, Transformers have been introduced into the field of acoustics recognition. They are pre-trained on large-scale datasets using methods such as supervised learning and semi-supervised learning, demonstrating robust generality--It fine-tunes easily to downstream tasks and shows more robust performance. However, the predominant fine-tuning method currently used is still full fine-tuning, which involves updating all parameters during training. This not only incurs significant memory usage and time costs but also compromises the model's generality. Other fine-tuning methods either struggle to address this issue or fail to achieve matching performance. Therefore, we conducted a comprehensive analysis of existing fine-tuning methods and proposed an efficient fine-tuning approach based on Adapter tuning, namely AAT. The core idea is to freeze the audio Transformer model and insert extra learnable Adapters, efficiently acquiring downstream task knowledge without compromising the model's original generality. Extensive experiments have shown that our method achieves performance comparable to or even superior to full fine-tuning while optimizing only 7.118% of the parameters. It also demonstrates superiority over other fine-tuning methods.
Structure-Aware Parametric Representations for Time-Resolved Light Transport
Aug 30, 2023



Time-resolved illumination provides rich spatio-temporal information for applications such as accurate depth sensing or hidden geometry reconstruction, becoming a useful asset for prototyping and as input for data-driven approaches. However, time-resolved illumination measurements are high-dimensional and have a low signal-to-noise ratio, hampering their applicability in real scenarios. We propose a novel method to compactly represent time-resolved illumination using mixtures of exponentially-modified Gaussians that are robust to noise and preserve structural information. Our method yields representations two orders of magnitude smaller than discretized data, providing consistent results in applications such as hidden scene reconstruction and depth estimation, and quantitative improvements over previous approaches.
Memory-aware Scheduling for Complex Wired Networks with Iterative Graph Optimization
Aug 26, 2023



Memory-aware network scheduling is becoming increasingly important for deep neural network (DNN) inference on resource-constrained devices. However, due to the complex cell-level and network-level topologies, memory-aware scheduling becomes very challenging. While previous algorithms all suffer from poor scalability, in this paper, we propose an efficient memory-aware scheduling framework based on iterative computation graph optimization. Our framework features an iterative graph fusion algorithm that simplifies the computation graph while preserving the scheduling optimality. We further propose an integer linear programming formulation together with topology-aware variable pruning to schedule the simplified graph efficiently. We evaluate our method against prior-art algorithms on different networks and demonstrate that our method outperforms existing techniques in all the benchmarks, reducing the peak memory footprint by 13.4%, and achieving better scalability for networks with complex network-level topologies.
On Mitigating Hard Clusters for Face Clustering
Jul 25, 2022
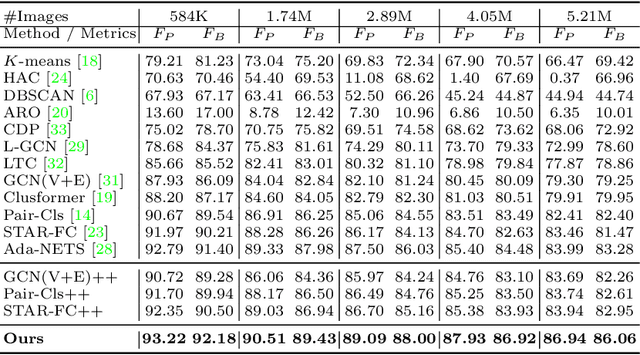
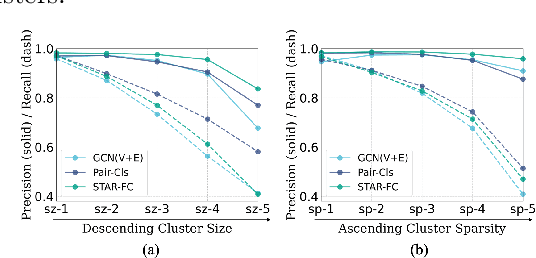
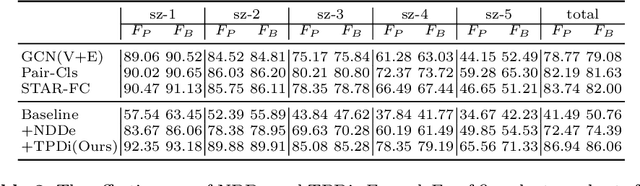
Face clustering is a promising way to scale up face recognition systems using large-scale unlabeled face images. It remains challenging to identify small or sparse face image clusters that we call hard clusters, which is caused by the heterogeneity, \ie, high variations in size and sparsity, of the clusters. Consequently, the conventional way of using a uniform threshold (to identify clusters) often leads to a terrible misclassification for the samples that should belong to hard clusters. We tackle this problem by leveraging the neighborhood information of samples and inferring the cluster memberships (of samples) in a probabilistic way. We introduce two novel modules, Neighborhood-Diffusion-based Density (NDDe) and Transition-Probability-based Distance (TPDi), based on which we can simply apply the standard Density Peak Clustering algorithm with a uniform threshold. Our experiments on multiple benchmarks show that each module contributes to the final performance of our method, and by incorporating them into other advanced face clustering methods, these two modules can boost the performance of these methods to a new state-of-the-art. Code is available at: https://github.com/echoanran/On-Mitigating-Hard-Clusters.