 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyPER: Bridging Exploration and Exploitation for Scalable LLM Reasoning with Hypothesis Path Expansion and Reduction
Feb 06, 2026Scaling test-time compute with multi-path chain-of-thought improves reasoning accuracy, but its effectiveness depends critically on the exploration-exploitation trade-off. Existing approaches address this trade-off in rigid ways: tree-structured search hard-codes exploration through brittle expansion rules that interfere with post-trained reasoning, while parallel reasoning over-explores redundant hypothesis paths and relies on weak answer selection. Motivated by the observation that the optimal balance is phase-dependent and that correct and incorrect reasoning paths often diverge only at late stages, we reformulate test-time scaling as a dynamic expand-reduce control problem over a pool of hypotheses. We propose HyPER, a training-free online control policy for multi-path decoding in mixture-of-experts models that reallocates computation under a fixed budget using lightweight path statistics. HyPER consists of an online controller that transitions from exploration to exploitation as the hypothesis pool evolves, a token-level refinement mechanism that enables efficient generation-time exploitation without full-path resampling, and a length- and confidence-aware aggregation strategy for reliable answer-time exploitation. Experiments on four mixture-of-experts language models across diverse reasoning benchmarks show that HyPER consistently achieves a superior accuracy-compute trade-off, improving accuracy by 8 to 10 percent while reducing token usage by 25 to 40 percent.
HybriMoE: Hybrid CPU-GPU Scheduling and Cache Management for Efficient MoE Inference
Apr 08, 2025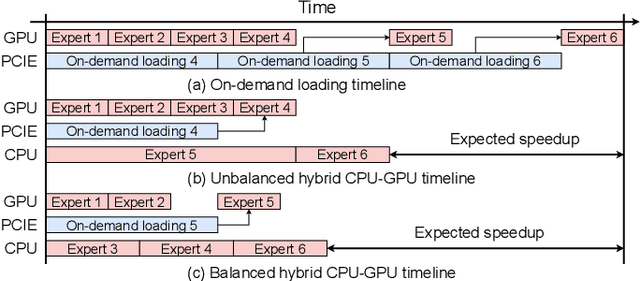
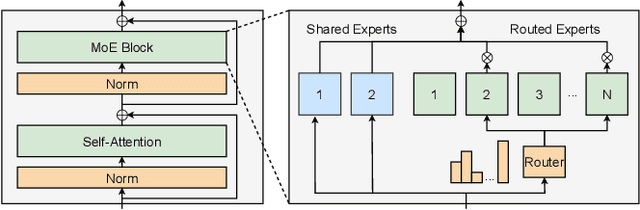
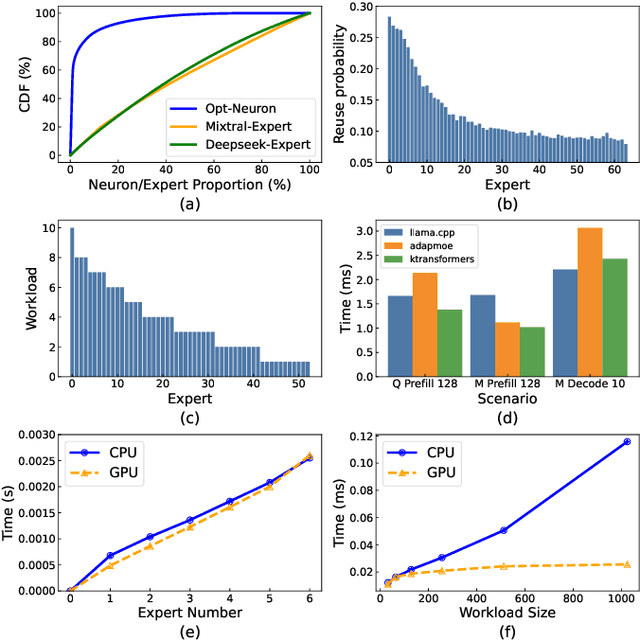
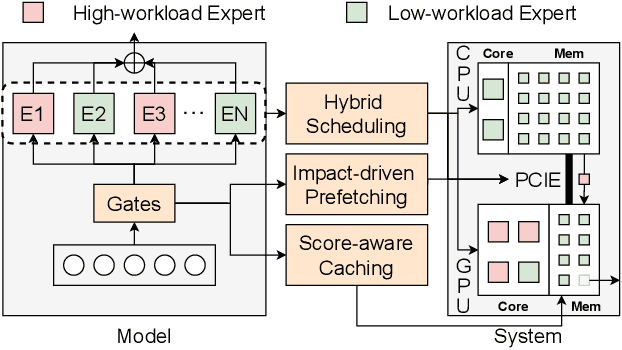
The Mixture of Experts (MoE) architecture has demonstrated significant advantages as it enables to increase the model capacity without a proportional increase in computation. However, the large MoE model size still introduces substantial memory demands, which usually requires expert offloading on resource-constrained platforms and incurs significant overhead. Hybrid CPU-GPU inference has been proposed to leverage CPU computation to reduce expert loading overhead but faces major challenges: on one hand, the expert activation patterns of MoE models are highly unstable, rendering the fixed mapping strategies in existing works inefficient; on the other hand, the hybrid CPU-GPU schedule for MoE is inherently complex due to the diverse expert sizes, structures, uneven workload distribution, etc. To address these challenges, in this paper, we propose HybriMoE, a hybrid CPU-GPU inference framework that improves resource utilization through a novel CPU-GPU scheduling and cache management system. HybriMoE introduces (i) a dynamic intra-layer scheduling strategy to balance workloads across CPU and GPU, (ii) an impact-driven inter-layer prefetching algorithm, and (iii) a score-based caching algorithm to mitigate expert activation instability. We implement HybriMoE on top of the kTransformers framework and evaluate it on three widely used MoE-based LLMs. Experimental results demonstrate that HybriMoE achieves an average speedup of 1.33$\times$ in the prefill stage and 1.70$\times$ in the decode stage compared to state-of-the-art hybrid MoE inference framework. Our code is available at: https://github.com/PKU-SEC-Lab/HybriMoE.
PrivQuant: Communication-Efficient Private Inference with Quantized Network/Protocol Co-Optimization
Oct 12, 2024Private deep neural network (DNN) inference based on secure two-party computation (2PC) enables secure privacy protection for both the server and the client. However, existing secure 2PC frameworks suffer from a high inference latency due to enormous communication. As the communication of both linear and non-linear DNN layers reduces with the bit widths of weight and activation, in this paper, we propose PrivQuant, a framework that jointly optimizes the 2PC-based quantized inference protocols and the network quantization algorithm, enabling communication-efficient private inference. PrivQuant proposes DNN architecture-aware optimizations for the 2PC protocols for communication-intensive quantized operators and conducts graph-level operator fusion for communication reduction. Moreover, PrivQuant also develops a communication-aware mixed precision quantization algorithm to improve inference efficiency while maintaining high accuracy. The network/protocol co-optimization enables PrivQuant to outperform prior-art 2PC frameworks. With extensive experiments, we demonstrate PrivQuant reduces communication by $11\times, 2.5\times \mathrm{and}~ 2.8\times$, which results in $8.7\times, 1.8\times ~ \mathrm{and}~ 2.4\times$ latency reduction compared with SiRNN, COINN, and CoPriv, respectively.
AdapMoE: Adaptive Sensitivity-based Expert Gating and Management for Efficient MoE Inference
Aug 19, 2024
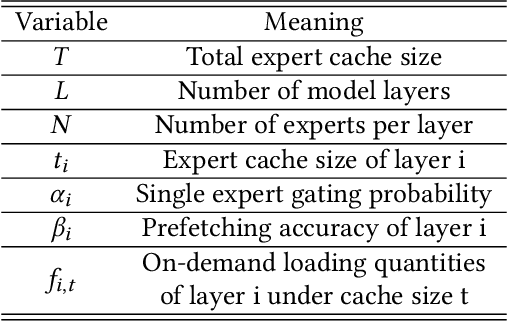
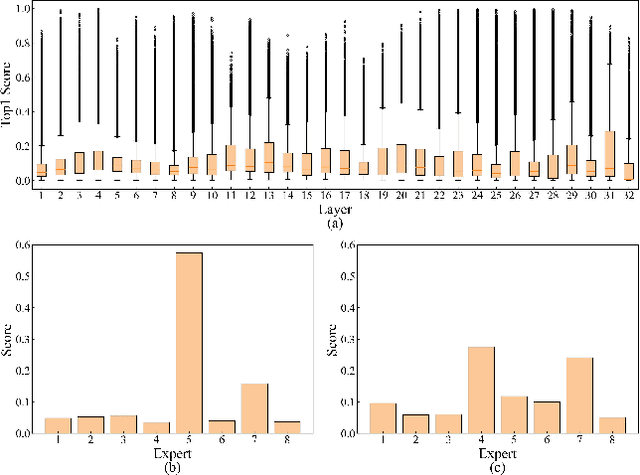
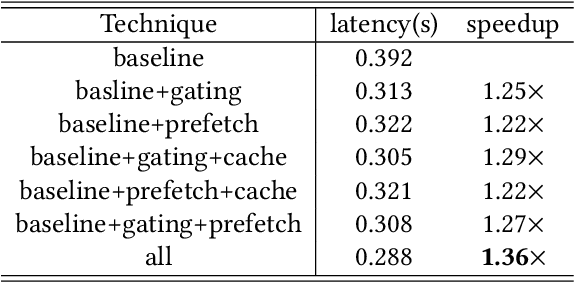
Mixture-of-Experts (MoE) models are designed to enhance the efficiency of large language models (LLMs) without proportionally increasing the computational demands. However, their deployment on edge devices still faces significant challenges due to high on-demand loading overheads from managing sparsely activated experts. This paper introduces AdapMoE, an algorithm-system co-design framework for efficient MoE inference. AdapMoE features adaptive expert gating and management to reduce the on-demand loading overheads. We observe the heterogeneity of experts loading across layers and tokens, based on which we propose a sensitivity-based strategy to adjust the number of activated experts dynamically. Meanwhile, we also integrate advanced prefetching and cache management techniques to further reduce the loading latency. Through comprehensive evaluations on various platforms, we demonstrate AdapMoE consistently outperforms existing techniques, reducing the average number of activated experts by 25% and achieving a 1.35x speedup without accuracy degradation. Code is available at: https://github.com/PKU-SEC-Lab/AdapMoE.
ProPD: Dynamic Token Tree Pruning and Generation for LLM Parallel Decoding
Feb 21, 2024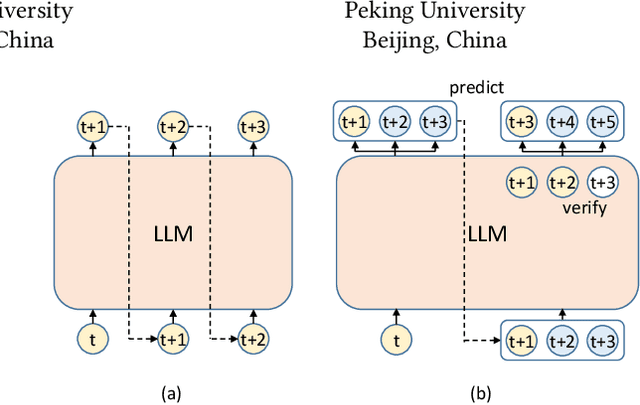
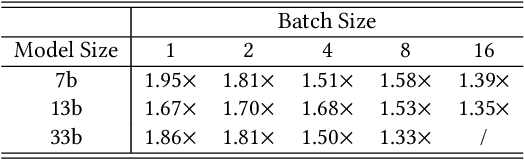
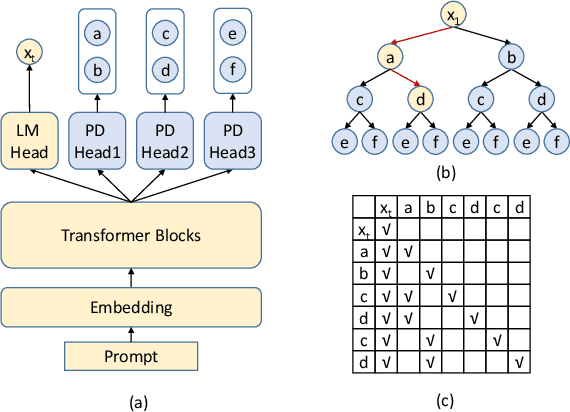
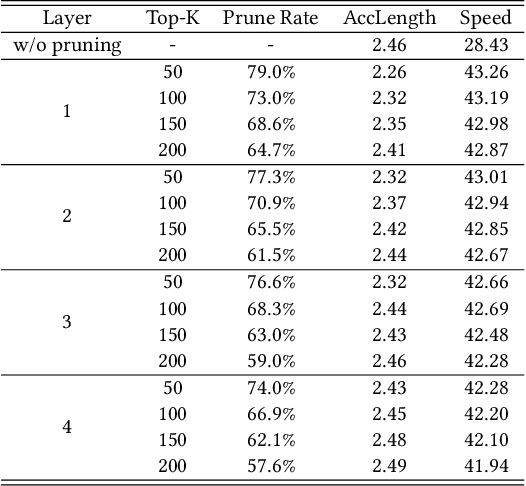
Recent advancements in generative large language models (LLMs) have significantly boosted the performance in natural language processing tasks. However, their efficiency is hampered by the inherent limitations in autoregressive token generation. While parallel decoding with token tree verification, e.g., Medusa, has been proposed to improve decoding parallelism and efficiency, it often struggles with maintaining contextual relationships due to its independent token prediction approach and incurs significant verification overhead, especially with large tree sizes and batch processing. In this paper, we propose ProPD, an efficient LLM parallel decoding framework based on dynamic token tree pruning and generation. ProPD features an advanced early pruning mechanism to efficiently eliminate unpromising token sequences to improve verification efficiency. Additionally, it introduces a dynamic token tree generation algorithm to balance the computation and parallelism of the verification phase in real-time and maximize the overall efficiency across different batch sizes, sequence lengths, and tasks, etc. We verify ProPD across a diverse set of datasets, LLMs, and batch sizes and demonstrate ProPD consistently outperforms existing decoding algorithms by 1.1-3.2x.
Memory-aware Scheduling for Complex Wired Networks with Iterative Graph Optimization
Aug 26, 2023



Memory-aware network scheduling is becoming increasingly important for deep neural network (DNN) inference on resource-constrained devices. However, due to the complex cell-level and network-level topologies, memory-aware scheduling becomes very challenging. While previous algorithms all suffer from poor scalability, in this paper, we propose an efficient memory-aware scheduling framework based on iterative computation graph optimization. Our framework features an iterative graph fusion algorithm that simplifies the computation graph while preserving the scheduling optimality. We further propose an integer linear programming formulation together with topology-aware variable pruning to schedule the simplified graph efficiently. We evaluate our method against prior-art algorithms on different networks and demonstrate that our method outperforms existing techniques in all the benchmarks, reducing the peak memory footprint by 13.4%, and achieving better scalability for networks with complex network-level topologies.