 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEANER: Self-Purified Trajectories Boost Agentic Reinforcement Learning
Jan 21, 2026Agentic Reinforcement Learning (RL) has empowered Large Language Models (LLMs) to utilize tools like Python interpreters for complex problem-solving. However, for parameter-constrained models (e.g., 4B--7B), the exploration phase is often plagued by frequent execution failures, creating noisy trajectories that hinder policy optimization. Under standard outcome-based reward settings, this noise leads to a critical credit assignment issue, where erroneous actions are inadvertently reinforced alongside successful outcomes. Existing mitigations face a dilemma: dense rewards often trigger reward hacking, while supersampling incurs prohibitive computational costs. To address these challenges, we propose CLEANER. Distinct from external filtering methods, CLEANER exploits the model's intrinsic self-correction capabilities to eliminate error-contaminated context directly during data collection. At its core, the Similarity-Aware Adaptive Rollback (SAAR) mechanism autonomously constructs clean, purified trajectories by retrospectively replacing failures with successful self-corrections. Based on semantic similarity, SAAR adaptively regulates replacement granularity from shallow execution repairs to deep reasoning substitutions. By training on these self-purified paths, the model internalizes correct reasoning patterns rather than error-recovery loops. Empirical results on AIME24/25, GPQA, and LiveCodeBench show average accuracy gains of 6%, 3%, and 5% over baselines. Notably, CLEANER matches state-of-the-art performance using only one-third of the training steps, highlighting trajectory purification as a scalable solution for efficient agentic RL. Our models and code are available at GitHub
S$^4$C: Speculative Sampling with Syntactic and Semantic Coherence for Efficient Inference of Large Language Models
Jun 17, 2025Large language models (LLMs) exhibit remarkable reasoning capabilities across diverse downstream tasks. However, their autoregressive nature leads to substantial inference latency, posing challenges for real-time applications. Speculative sampling mitigates this issue by introducing a drafting phase followed by a parallel validation phase, enabling faster token generation and verification. Existing approaches, however, overlook the inherent coherence in text generation, limiting their efficiency. To address this gap, we propose a Speculative Sampling with Syntactic and Semantic Coherence (S$^4$C) framework, which extends speculative sampling by leveraging multi-head drafting for rapid token generation and a continuous verification tree for efficient candidate validation and feature reuse. Experimental results demonstrate that S$^4$C surpasses baseline methods across mainstream tasks, offering enhanced efficiency, parallelism, and the ability to generate more valid tokens with fewer computational resources. On Spec-bench benchmarks, S$^4$C achieves an acceleration ratio of 2.26x-2.60x, outperforming state-of-the-art methods.
Preconditioned Additive Gaussian Processes with Fourier Acceleration
Apr 01, 2025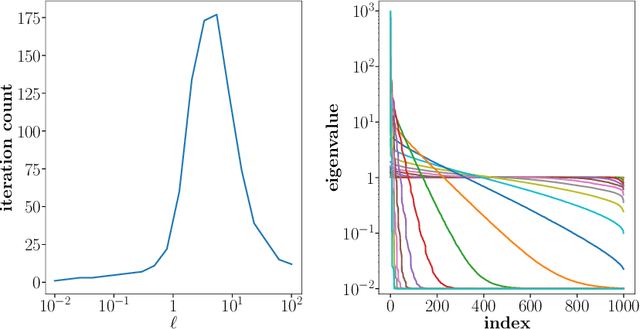



Gaussian processes (GPs) are crucial in machine learning for quantifying uncertainty in predictions. However, their associated covariance matrices, defined by kernel functions, are typically dense and large-scale, posing significant computational challenges. This paper introduces a matrix-free method that utilizes the Non-equispaced Fast Fourier Transform (NFFT) to achieve nearly linear complexity in the multiplication of kernel matrices and their derivatives with vectors for a predetermined accuracy level. To address high-dimensional problems, we propose an additive kernel approach. Each sub-kernel in this approach captures lower-order feature interactions, allowing for the efficient application of the NFFT method and potentially increasing accuracy across various real-world datasets. Additionally, we implement a preconditioning strategy that accelerates hyperparameter tuning, further improving the efficiency and effectiveness of GPs.
HiGP: A high-performance Python package for Gaussian Process
Mar 04, 2025Gaussian Processes (GPs) are flexible, nonparametric Bayesian models widely used for regression and classification tasks due to their ability to capture complex data patterns and provide uncertainty quantification (UQ). Traditional GP implementations often face challenges in scalability and computational efficiency, especially with large datasets. To address these challenges, HiGP, a high-performance Python package, is designed for efficient Gaussian Process regression (GPR) and classification (GPC) across datasets of varying sizes. HiGP combines multiple new iterative methods to enhance the performance and efficiency of GP computations. It implements various effective matrix-vector (MatVec) and matrix-matrix (MatMul) multiplication strategies specifically tailored for kernel matrices. To improve the convergence of iterative methods, HiGP also integrates the recently developed Adaptive Factorized Nystrom (AFN) preconditioner and employs precise formulas for computing the gradients. With a user-friendly Python interface, HiGP seamlessly integrates with PyTorch and other Python packages, allowing easy incorporation into existing machine learning and data analysis workflows.
PrivQuant: Communication-Efficient Private Inference with Quantized Network/Protocol Co-Optimization
Oct 12, 2024Private deep neural network (DNN) inference based on secure two-party computation (2PC) enables secure privacy protection for both the server and the client. However, existing secure 2PC frameworks suffer from a high inference latency due to enormous communication. As the communication of both linear and non-linear DNN layers reduces with the bit widths of weight and activation, in this paper, we propose PrivQuant, a framework that jointly optimizes the 2PC-based quantized inference protocols and the network quantization algorithm, enabling communication-efficient private inference. PrivQuant proposes DNN architecture-aware optimizations for the 2PC protocols for communication-intensive quantized operators and conducts graph-level operator fusion for communication reduction. Moreover, PrivQuant also develops a communication-aware mixed precision quantization algorithm to improve inference efficiency while maintaining high accuracy. The network/protocol co-optimization enables PrivQuant to outperform prior-art 2PC frameworks. With extensive experiments, we demonstrate PrivQuant reduces communication by $11\times, 2.5\times \mathrm{and}~ 2.8\times$, which results in $8.7\times, 1.8\times ~ \mathrm{and}~ 2.4\times$ latency reduction compared with SiRNN, COINN, and CoPriv, respectively.
FastQuery: Communication-efficient Embedding Table Query for Private LLM Inference
May 25, 2024With the fast evolution of large language models (LLMs), privacy concerns with user queries arise as they may contain sensitive information. Private inference based on homomorphic encryption (HE) has been proposed to protect user query privacy. However, a private embedding table query has to be formulated as a HE-based matrix-vector multiplication problem and suffers from enormous computation and communication overhead. We observe the overhead mainly comes from the neglect of 1) the one-hot nature of user queries and 2) the robustness of the embedding table to low bit-width quantization noise. Hence, in this paper, we propose a private embedding table query optimization framework, dubbed FastQuery. FastQuery features a communication-aware embedding table quantization algorithm and a one-hot-aware dense packing algorithm to simultaneously reduce both the computation and communication costs. Compared to prior-art HE-based frameworks, e.g., Cheetah, Iron, and Bumblebee, FastQuery achieves more than $4.3\times$, $2.7\times$, $1.3\times$ latency reduction, respectively and more than $75.7\times$, $60.2\times$, $20.2\times$ communication reduction, respectively, on both LLAMA-7B and LLAMA-30B.
PrivCirNet: Efficient Private Inference via Block Circulant Transformation
May 23, 2024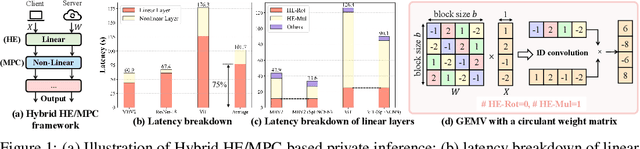
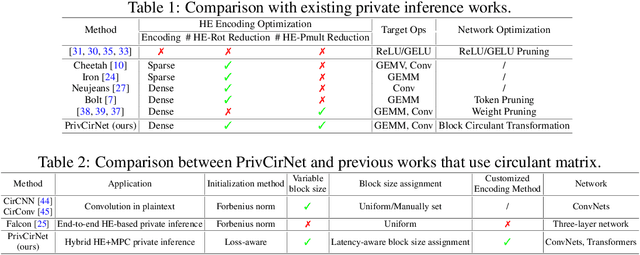

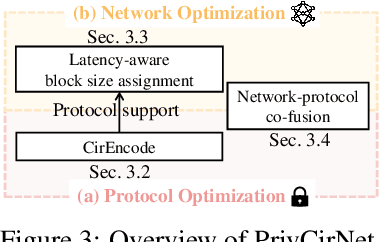
Homomorphic encryption (HE)-based deep neural network (DNN) inference protects data and model privacy but suffers from significant computation overhead. We observe transforming the DNN weights into circulant matrices converts general matrix-vector multiplications into HE-friendly 1-dimensional convolutions, drastically reducing the HE computation cost. Hence, in this paper, we propose \method, a protocol/network co-optimization framework based on block circulant transformation. At the protocol level, PrivCirNet customizes the HE encoding algorithm that is fully compatible with the block circulant transformation and reduces the computation latency in proportion to the block size. At the network level, we propose a latency-aware formulation to search for the layer-wise block size assignment based on second-order information. PrivCirNet also leverages layer fusion to further reduce the inference cost. We compare PrivCirNet with the state-of-the-art HE-based framework Bolt (IEEE S\&P 2024) and the HE-friendly pruning method SpENCNN (ICML 2023). For ResNet-18 and Vision Transformer (ViT) on Tiny ImageNet, PrivCirNet reduces latency by $5.0\times$ and $1.3\times$ with iso-accuracy over Bolt, respectively, and improves accuracy by $4.1\%$ and $12\%$ over SpENCNN, respectively. For MobileNetV2 on ImageNet, PrivCirNet achieves $1.7\times$ lower latency and $4.2\%$ better accuracy over Bolt and SpENCNN, respectively. Our code and checkpoints are available in the supplementary materials.
HEQuant: Marrying Homomorphic Encryption and Quantization for Communication-Efficient Private Inference
Jan 31, 2024Secure two-party computation with homomorphic encryption (HE) protects data privacy with a formal security guarantee but suffers from high communication overhead. While previous works, e.g., Cheetah, Iron, etc, have proposed efficient HE-based protocols for different neural network (NN) operations, they still assume high precision, e.g., fixed point 37 bit, for the NN operations and ignore NNs' native robustness against quantization error. In this paper, we propose HEQuant, which features low-precision-quantization-aware optimization for the HE-based protocols. We observe the benefit of a naive combination of quantization and HE quickly saturates as bit precision goes down. Hence, to further improve communication efficiency, we propose a series of optimizations, including an intra-coefficient packing algorithm and a quantization-aware tiling algorithm, to simultaneously reduce the number and precision of the transferred data. Compared with prior-art HE-based protocols, e.g., CrypTFlow2, Cheetah, Iron, etc, HEQuant achieves $3.5\sim 23.4\times$ communication reduction and $3.0\sim 9.3\times$ latency reduction. Meanwhile, when compared with prior-art network optimization frameworks, e.g., SENet, SNL, etc, HEQuant also achieves $3.1\sim 3.6\times$ communication reduction.
Falcon: Accelerating Homomorphically Encrypted Convolutions for Efficient Private Mobile Network Inference
Aug 25, 2023Efficient networks, e.g., MobileNetV2, EfficientNet, etc, achieves state-of-the-art (SOTA) accuracy with lightweight computation. However, existing homomorphic encryption (HE)-based two-party computation (2PC) frameworks are not optimized for these networks and suffer from a high inference overhead. We observe the inefficiency mainly comes from the packing algorithm, which ignores the computation characteristics and the communication bottleneck of homomorphically encrypted depthwise convolutions. Therefore, in this paper, we propose Falcon, an effective dense packing algorithm for HE-based 2PC frameworks. Falcon features a zero-aware greedy packing algorithm and a communication-aware operator tiling strategy to improve the packing density for depthwise convolutions. Compared to SOTA HE-based 2PC frameworks, e.g., CrypTFlow2, Iron and Cheetah, Falcon achieves more than 15.6x, 5.1x and 1.8x latency reduction, respectively, at operator level. Meanwhile, at network level, Falcon allows for 1.4% and 4.2% accuracy improvement over Cheetah on CIFAR-100 and TinyImagenet datasets with iso-communication, respecitvely.