 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads
Feb 10, 2026The transition from symbolic manipulation to science-grade reasoning represents a pivotal frontier for Large Language Models (LLMs), with physics serving as the critical test anchor for binding abstract logic to physical reality. Physics demands that a model maintain physical consistency with the laws governing the universe, a task that fundamentally requires multimodal perception to ground abstract logic in reality. At the Olympiad level, diagrams are often constitutive rather than illustrative, containing essential constraints, such as boundary conditions and spatial symmetries, that are absent from the text. To bridge this visual-logical gap, we introduce P1-VL, a family of open-source vision-language models engineered for advanced scientific reasoning. Our method harmonizes Curriculum Reinforcement Learning, which employs progressive difficulty expansion to stabilize post-training, with Agentic Augmentation, enabling iterative self-verification at inference. Evaluated on HiPhO, a rigorous benchmark of 13 exams from 2024-2025, our flagship P1-VL-235B-A22B becomes the first open-source Vision-Language Model (VLM) to secure 12 gold medals and achieves the state-of-the-art performance in the open-source models. Our agent-augmented system achieves the No.2 overall rank globally, trailing only Gemini-3-Pro. Beyond physics, P1-VL demonstrates remarkable scientific reasoning capacity and generalizability, establishing significant leads over base models in STEM benchmarks. By open-sourcing P1-VL, we provide a foundational step toward general-purpose physical intelligence to better align visual perceptions with abstract physical laws for machine scientific discovery.
Attention Sink Forges Native MoE in Attention Layers: Sink-Aware Training to Address Head Collapse
Feb 01, 2026Large Language Models (LLMs) often assign disproportionate attention to the first token, a phenomenon known as the attention sink. Several recent approaches aim to address this issue, including Sink Attention in GPT-OSS and Gated Attention in Qwen3-Next. However, a comprehensive analysis of the relationship among these attention mechanisms is lacking. In this work, we provide both theoretical and empirical evidence demonstrating that the sink in Vanilla Attention and Sink Attention naturally construct a Mixture-of-Experts (MoE) mechanism within attention layers. This insight explains the head collapse phenomenon observed in prior work, where only a fixed subset of attention heads contributes to generation. To mitigate head collapse, we propose a sink-aware training algorithm with an auxiliary load balancing loss designed for attention layers. Extensive experiments show that our method achieves effective head load balancing and improves model performance across Vanilla Attention, Sink Attention, and Gated Attention. We hope this study offers a new perspective on attention mechanisms and encourages further exploration of the inherent MoE structure within attention layers.
Jupiter: Enhancing LLM Data Analysis Capabilities via Notebook and Inference-Time Value-Guided Search
Sep 11, 2025

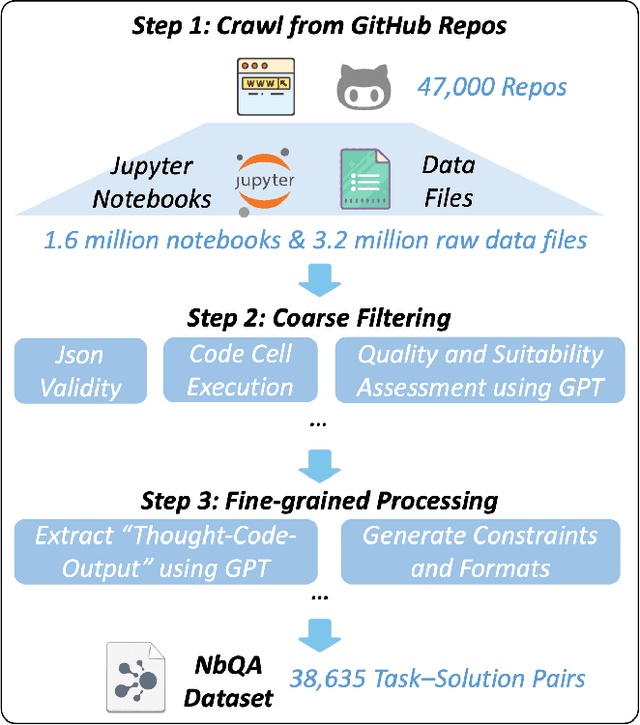
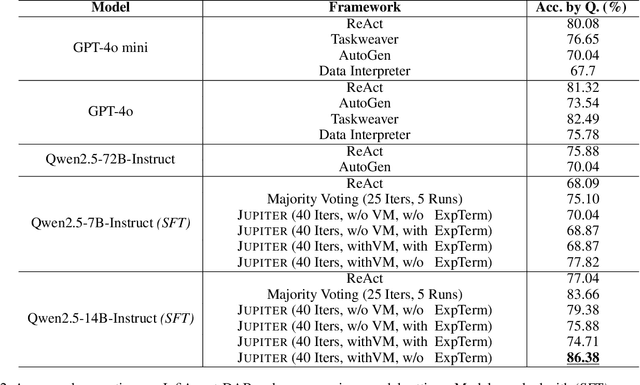
Large language models (LLMs) have shown great promise in automating data science workflows, but existing models still struggle with multi-step reasoning and tool use, which limits their effectiveness on complex data analysis tasks. To address this, we propose a scalable pipeline that extracts high-quality, tool-based data analysis tasks and their executable multi-step solutions from real-world Jupyter notebooks and associated data files. Using this pipeline, we introduce NbQA, a large-scale dataset of standardized task-solution pairs that reflect authentic tool-use patterns in practical data science scenarios. To further enhance multi-step reasoning, we present Jupiter, a framework that formulates data analysis as a search problem and applies Monte Carlo Tree Search (MCTS) to generate diverse solution trajectories for value model learning. During inference, Jupiter combines the value model and node visit counts to efficiently collect executable multi-step plans with minimal search steps. Experimental results show that Qwen2.5-7B and 14B-Instruct models on NbQA solve 77.82% and 86.38% of tasks on InfiAgent-DABench, respectively-matching or surpassing GPT-4o and advanced agent frameworks. Further evaluations demonstrate improved generalization and stronger tool-use reasoning across diverse multi-step reasoning tasks.
PrivQuant: Communication-Efficient Private Inference with Quantized Network/Protocol Co-Optimization
Oct 12, 2024Private deep neural network (DNN) inference based on secure two-party computation (2PC) enables secure privacy protection for both the server and the client. However, existing secure 2PC frameworks suffer from a high inference latency due to enormous communication. As the communication of both linear and non-linear DNN layers reduces with the bit widths of weight and activation, in this paper, we propose PrivQuant, a framework that jointly optimizes the 2PC-based quantized inference protocols and the network quantization algorithm, enabling communication-efficient private inference. PrivQuant proposes DNN architecture-aware optimizations for the 2PC protocols for communication-intensive quantized operators and conducts graph-level operator fusion for communication reduction. Moreover, PrivQuant also develops a communication-aware mixed precision quantization algorithm to improve inference efficiency while maintaining high accuracy. The network/protocol co-optimization enables PrivQuant to outperform prior-art 2PC frameworks. With extensive experiments, we demonstrate PrivQuant reduces communication by $11\times, 2.5\times \mathrm{and}~ 2.8\times$, which results in $8.7\times, 1.8\times ~ \mathrm{and}~ 2.4\times$ latency reduction compared with SiRNN, COINN, and CoPriv, respectively.
FaiMA: Feature-aware In-context Learning for Multi-domain Aspect-based Sentiment Analysis
Mar 02, 2024



Multi-domain aspect-based sentiment analysis (ABSA) seeks to capture fine-grained sentiment across diverse domains. While existing research narrowly focuses on single-domain applications constrained by methodological limitations and data scarcity, the reality is that sentiment naturally traverses multiple domains. Although large language models (LLMs) offer a promising solution for ABSA, it is difficult to integrate effectively with established techniques, including graph-based models and linguistics, because modifying their internal architecture is not easy. To alleviate this problem, we propose a novel framework, Feature-aware In-context Learning for Multi-domain ABSA (FaiMA). The core insight of FaiMA is to utilize in-context learning (ICL) as a feature-aware mechanism that facilitates adaptive learning in multi-domain ABSA tasks. Specifically, we employ a multi-head graph attention network as a text encoder optimized by heuristic rules for linguistic, domain, and sentiment features. Through contrastive learning, we optimize sentence representations by focusing on these diverse features. Additionally, we construct an efficient indexing mechanism, allowing FaiMA to stably retrieve highly relevant examples across multiple dimensions for any given input. To evaluate the efficacy of FaiMA, we build the first multi-domain ABSA benchmark dataset. Extensive experimental results demonstrate that FaiMA achieves significant performance improvements in multiple domains compared to baselines, increasing F1 by 2.07% on average. Source code and data sets are anonymously available at https://github.com/SupritYoung/FaiMA.
Kuaiji: the First Chinese Accounting Large Language Model
Feb 24, 2024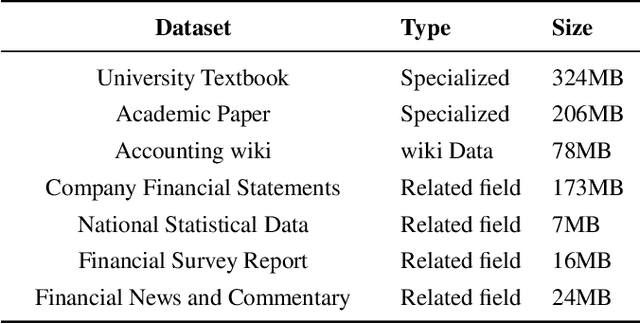
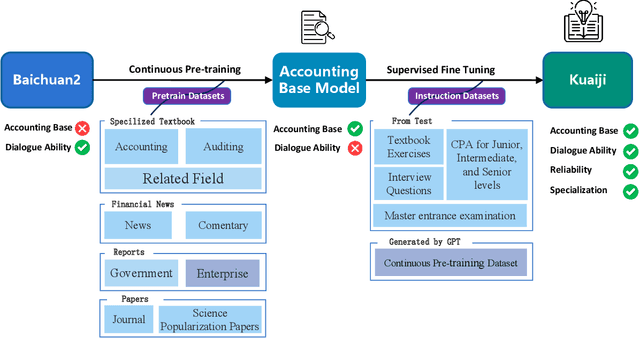
Large Language Models (LLMs) like ChatGPT and GPT-4 have demonstrated impressive proficiency in comprehending and generating natural language. However, they encounter difficulties when tasked with adapting to specialized domains such as accounting. To address this challenge, we introduce Kuaiji, a tailored Accounting Large Language Model. Kuaiji is meticulously fine-tuned using the Baichuan framework, which encompasses continuous pre-training and supervised fine-tuning processes. Supported by CAtAcctQA, a dataset containing large genuine accountant-client dialogues, Kuaiji exhibits exceptional accuracy and response speed. Our contributions encompass the creation of the first Chinese accounting dataset, the establishment of Kuaiji as a leading open-source Chinese accounting LLM, and the validation of its efficacy through real-world accounting scenarios.
ASGEA: Exploiting Logic Rules from Align-Subgraphs for Entity Alignment
Feb 16, 2024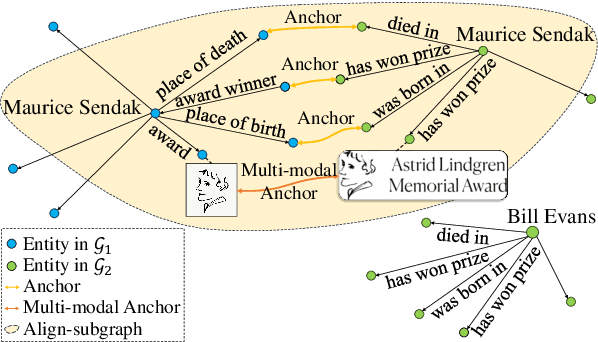
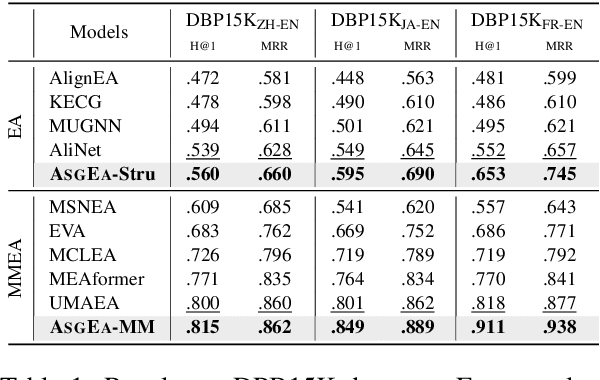
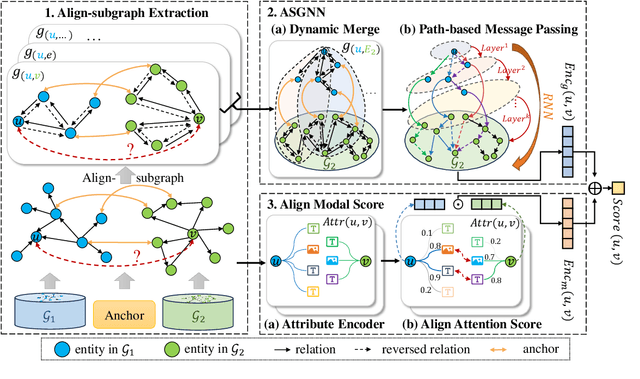
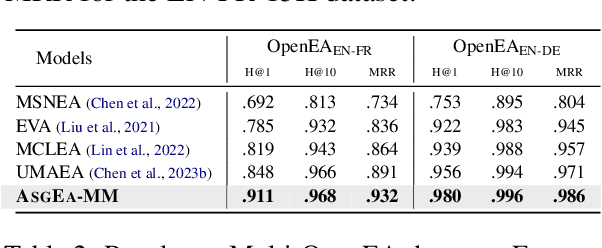
Entity alignment (EA) aims to identify entities across different knowledge graphs that represent the same real-world objects. Recent embedding-based EA methods have achieved state-of-the-art performance in EA yet faced interpretability challenges as they purely rely on the embedding distance and neglect the logic rules behind a pair of aligned entities. In this paper, we propose the Align-Subgraph Entity Alignment (ASGEA) framework to exploit logic rules from Align-Subgraphs. ASGEA uses anchor links as bridges to construct Align-Subgraphs and spreads along the paths across KGs, which distinguishes it from the embedding-based methods. Furthermore, we design an interpretable Path-based Graph Neural Network, ASGNN, to effectively identify and integrate the logic rules across KGs. We also introduce a node-level multi-modal attention mechanism coupled with multi-modal enriched anchors to augment the Align-Subgraph. Our experimental results demonstrate the superior performance of ASGEA over the existing embedding-based methods in both EA and Multi-Modal EA (MMEA) tasks. Our code will be available soon.
BAT: Behavior-Aware Human-Like Trajectory Prediction for Autonomous Driving
Dec 15, 2023



The ability to accurately predict the trajectory of surrounding vehicles is a critical hurdle to overcome on the journey to fully autonomous vehicles. To address this challenge, we pioneer a novel behavior-aware trajectory prediction model (BAT) that incorporates insights and findings from traffic psychology, human behavior, and decision-making. Our model consists of behavior-aware, interaction-aware, priority-aware, and position-aware modules that perceive and understand the underlying interactions and account for uncertainty and variability in prediction, enabling higher-level learning and flexibility without rigid categorization of driving behavior. Importantly, this approach eliminates the need for manual labeling in the training process and addresses the challenges of non-continuous behavior labeling and the selection of appropriate time windows. We evaluate BAT's performance across the Next Generation Simulation (NGSIM), Highway Drone (HighD), Roundabout Drone (RounD), and Macao Connected Autonomous Driving (MoCAD) datasets, showcasing its superiority over prevailing state-of-the-art (SOTA) benchmarks in terms of prediction accuracy and efficiency. Remarkably, even when trained on reduced portions of the training data (25%), our model outperforms most of the baselines, demonstrating its robustness and efficiency in predicting vehicle trajectories, and the potential to reduce the amount of data required to train autonomous vehicles, especially in corner cases. In conclusion, the behavior-aware model represents a significant advancement in the development of autonomous vehicles capable of predicting trajectories with the same level of proficiency as human drivers. The project page is available at https://github.com/Petrichor625/BATraj-Behavior-aware-Model.
Converge to the Truth: Factual Error Correction via Iterative Constrained Editing
Dec 02, 2022



Given a possibly false claim sentence, how can we automatically correct it with minimal editing? Existing methods either require a large number of pairs of false and corrected claims for supervised training or do not handle well errors spanning over multiple tokens within an utterance. In this paper, we propose VENCE, a novel method for factual error correction (FEC) with minimal edits. VENCE formulates the FEC problem as iterative sampling editing actions with respect to a target density function. We carefully design the target function with predicted truthfulness scores from an offline trained fact verification model. VENCE samples the most probable editing positions based on back-calculated gradients of the truthfulness score concerning input tokens and the editing actions using a distantly-supervised language model (T5). Experiments on a public dataset show that VENCE improves the well-adopted SARI metric by 5.3 (or a relative improvement of 11.8%) over the previous best distantly-supervised methods.
MPCViT: Searching for MPC-friendly Vision Transformer with Heterogeneous Attention
Nov 25, 2022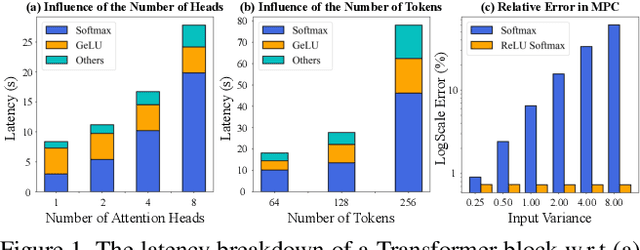

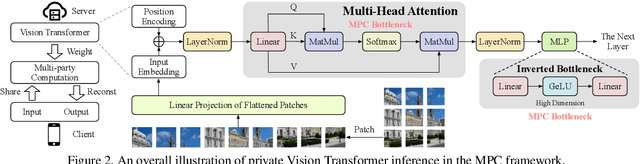
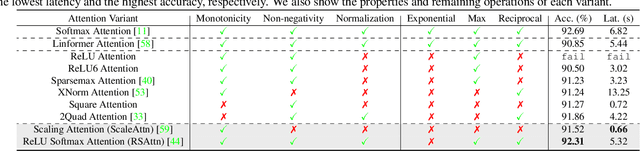
Secure multi-party computation (MPC) enables computation directly on encrypted data on non-colluding untrusted servers and protects both data and model privacy in deep learning inference. However, existing neural network (NN) architectures, including Vision Transformers (ViTs), are not designed or optimized for MPC protocols and incur significant latency overhead due to the Softmax function in the multi-head attention (MHA). In this paper, we propose an MPC-friendly ViT, dubbed MPCViT, to enable accurate yet efficient ViT inference in MPC. We systematically compare different attention variants in MPC and propose a heterogeneous attention search space, which combines the high-accuracy and MPC-efficient attentions with diverse structure granularities. We further propose a simple yet effective differentiable neural architecture search (NAS) algorithm for fast ViT optimization. MPCViT significantly outperforms prior-art ViT variants in MPC. With the proposed NAS algorithm, our extensive experiments demonstrate that MPCViT achieves 7.9x and 2.8x latency reduction with better accuracy compared to Linformer and MPCFormer on the Tiny-ImageNet dataset, respectively. Further, with proper knowledge distillation (KD), MPCViT even achieves 1.9% better accuracy compared to the baseline ViT with 9.9x latency reduction on the Tiny-ImageNet dataset.