 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Picture Tells a Dangerous Story: Memory-Augmented Multi-Agent Jailbreak Attacks on VLMs
Apr 14, 2026The rapid evolution of Vision-Language Models (VLMs) has catalyzed unprecedented capabilities in artificial intelligence; however, this continuous modal expansion has inadvertently exposed a vastly broadened and unconstrained adversarial attack surface. Current multimodal jailbreak strategies primarily focus on surface-level pixel perturbations and typographic attacks or harmful images; however, they fail to engage with the complex semantic structures intrinsic to visual data. This leaves the vast semantic attack surface of original, natural images largely unscrutinized. Driven by the need to expose these deep-seated semantic vulnerabilities, we introduce \textbf{MemJack}, a \textbf{MEM}ory-augmented multi-agent \textbf{JA}ilbreak atta\textbf{CK} framework that explicitly leverages visual semantics to orchestrate automated jailbreak attacks. MemJack employs coordinated multi-agent cooperation to dynamically map visual entities to malicious intents, generate adversarial prompts via multi-angle visual-semantic camouflage, and utilize an Iterative Nullspace Projection (INLP) geometric filter to bypass premature latent space refusals. By accumulating and transferring successful strategies through a persistent Multimodal Experience Memory, MemJack maintains highly coherent extended multi-turn jailbreak attack interactions across different images, thereby improving the attack success rate (ASR) on new images. Extensive empirical evaluations across full, unmodified COCO val2017 images demonstrate that MemJack achieves a 71.48\% ASR against Qwen3-VL-Plus, scaling to 90\% under extended budgets. Furthermore, to catalyze future defensive alignment research, we will release \textbf{MemJack-Bench}, a comprehensive dataset comprising over 113,000 interactive multimodal jailbreak attack trajectories, establishing a vital foundation for developing inherently robust VLMs.
SILC-EFSA: Self-aware In-context Learning Correction for Entity-level Financial Sentiment Analysis
Dec 26, 2024



In recent years, fine-grained sentiment analysis in finance has gained significant attention, but the scarcity of entity-level datasets remains a key challenge. To address this, we have constructed the largest English and Chinese financial entity-level sentiment analysis datasets to date. Building on this foundation, we propose a novel two-stage sentiment analysis approach called Self-aware In-context Learning Correction (SILC). The first stage involves fine-tuning a base large language model to generate pseudo-labeled data specific to our task. In the second stage, we train a correction model using a GNN-based example retriever, which is informed by the pseudo-labeled data. This two-stage strategy has allowed us to achieve state-of-the-art performance on the newly constructed datasets, advancing the field of financial sentiment analysis. In a case study, we demonstrate the enhanced practical utility of our data and methods in monitoring the cryptocurrency market. Our datasets and code are available at https://github.com/NLP-Bin/SILC-EFSA.
Identifying Speakers and Addressees of Quotations in Novels with Prompt Learning
Aug 18, 2024


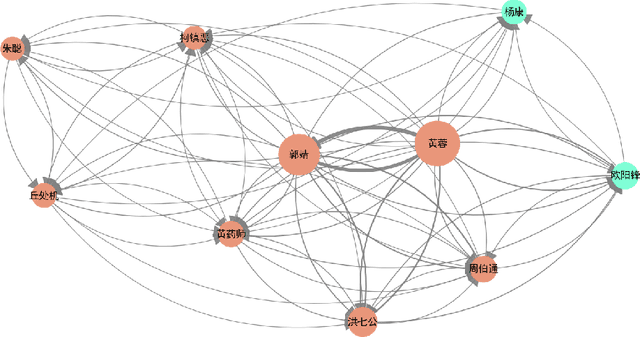
Quotations in literary works, especially novels, are important to create characters, reflect character relationships, and drive plot development. Current research on quotation extraction in novels primarily focuses on quotation attribution, i.e., identifying the speaker of the quotation. However, the addressee of the quotation is also important to construct the relationship between the speaker and the addressee. To tackle the problem of dataset scarcity, we annotate the first Chinese quotation corpus with elements including speaker, addressee, speaking mode and linguistic cue. We propose prompt learning-based methods for speaker and addressee identification based on fine-tuned pre-trained models. Experiments on both Chinese and English datasets show the effectiveness of the proposed methods, which outperform methods based on zero-shot and few-shot large language models.
ZZU-NLP at SIGHAN-2024 dimABSA Task: Aspect-Based Sentiment Analysis with Coarse-to-Fine In-context Learning
Jul 22, 2024



The DimABSA task requires fine-grained sentiment intensity prediction for restaurant reviews, including scores for Valence and Arousal dimensions for each Aspect Term. In this study, we propose a Coarse-to-Fine In-context Learning(CFICL) method based on the Baichuan2-7B model for the DimABSA task in the SIGHAN 2024 workshop. Our method improves prediction accuracy through a two-stage optimization process. In the first stage, we use fixed in-context examples and prompt templates to enhance the model's sentiment recognition capability and provide initial predictions for the test data. In the second stage, we encode the Opinion field using BERT and select the most similar training data as new in-context examples based on similarity. These examples include the Opinion field and its scores, as well as related opinion words and their average scores. By filtering for sentiment polarity, we ensure that the examples are consistent with the test data. Our method significantly improves prediction accuracy and consistency by effectively utilizing training data and optimizing in-context examples, as validated by experimental results.
MRC-based Nested Medical NER with Co-prediction and Adaptive Pre-training
Mar 23, 2024
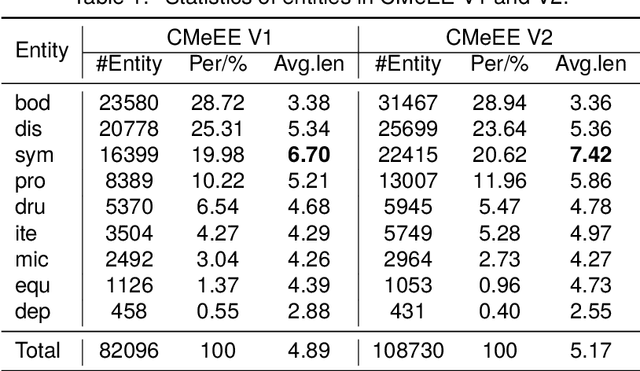
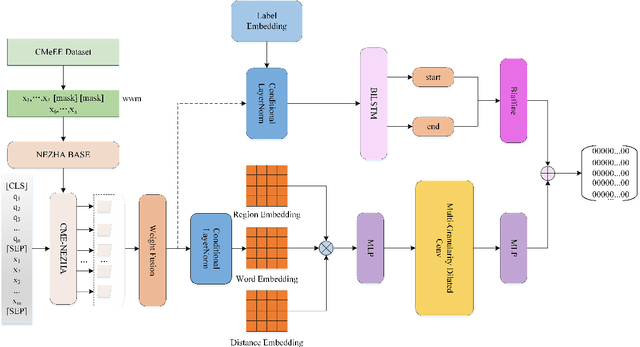
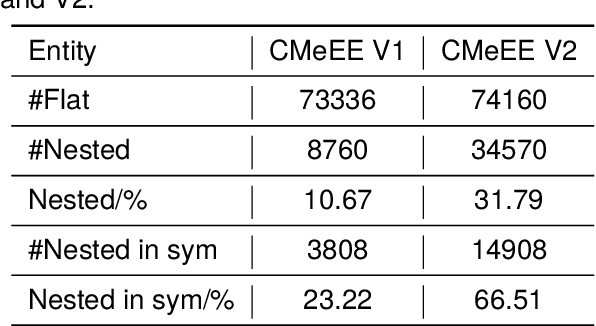
In medical information extraction, medical Named Entity Recognition (NER) is indispensable, playing a crucial role in developing medical knowledge graphs, enhancing medical question-answering systems, and analyzing electronic medical records. The challenge in medical NER arises from the complex nested structures and sophisticated medical terminologies, distinguishing it from its counterparts in traditional domains. In response to these complexities, we propose a medical NER model based on Machine Reading Comprehension (MRC), which uses a task-adaptive pre-training strategy to improve the model's capability in the medical field. Meanwhile, our model introduces multiple word-pair embeddings and multi-granularity dilated convolution to enhance the model's representation ability and uses a combined predictor of Biaffine and MLP to improve the model's recognition performance. Experimental evaluations conducted on the CMeEE, a benchmark for Chinese nested medical NER, demonstrate that our proposed model outperforms the compared state-of-the-art (SOTA) models.
FaiMA: Feature-aware In-context Learning for Multi-domain Aspect-based Sentiment Analysis
Mar 02, 2024



Multi-domain aspect-based sentiment analysis (ABSA) seeks to capture fine-grained sentiment across diverse domains. While existing research narrowly focuses on single-domain applications constrained by methodological limitations and data scarcity, the reality is that sentiment naturally traverses multiple domains. Although large language models (LLMs) offer a promising solution for ABSA, it is difficult to integrate effectively with established techniques, including graph-based models and linguistics, because modifying their internal architecture is not easy. To alleviate this problem, we propose a novel framework, Feature-aware In-context Learning for Multi-domain ABSA (FaiMA). The core insight of FaiMA is to utilize in-context learning (ICL) as a feature-aware mechanism that facilitates adaptive learning in multi-domain ABSA tasks. Specifically, we employ a multi-head graph attention network as a text encoder optimized by heuristic rules for linguistic, domain, and sentiment features. Through contrastive learning, we optimize sentence representations by focusing on these diverse features. Additionally, we construct an efficient indexing mechanism, allowing FaiMA to stably retrieve highly relevant examples across multiple dimensions for any given input. To evaluate the efficacy of FaiMA, we build the first multi-domain ABSA benchmark dataset. Extensive experimental results demonstrate that FaiMA achieves significant performance improvements in multiple domains compared to baselines, increasing F1 by 2.07% on average. Source code and data sets are anonymously available at https://github.com/SupritYoung/FaiMA.
A Corpus for Named Entity Recognition in Chinese Novels with Multi-genres
Nov 27, 2023Entities like person, location, organization are important for literary text analysis. The lack of annotated data hinders the progress of named entity recognition (NER) in literary domain. To promote the research of literary NER, we build the largest multi-genre literary NER corpus containing 263,135 entities in 105,851 sentences from 260 online Chinese novels spanning 13 different genres. Based on the corpus, we investigate characteristics of entities from different genres. We propose several baseline NER models and conduct cross-genre and cross-domain experiments. Experimental results show that genre difference significantly impact NER performance though not as much as domain difference like literary domain and news domain. Compared with NER in news domain, literary NER still needs much improvement and the Out-of-Vocabulary (OOV) problem is more challenging due to the high variety of entities in literary works.
Zhongjing: Enhancing the Chinese Medical Capabilities of Large Language Model through Expert Feedback and Real-world Multi-turn Dialogue
Aug 14, 2023Recent advances in Large Language Models (LLMs) have achieved remarkable breakthroughs in understanding and responding to user intents. However, their performance lag behind general use cases in some expertise domains, such as Chinese medicine. Existing efforts to incorporate Chinese medicine into LLMs rely on Supervised Fine-Tuning (SFT) with single-turn and distilled dialogue data. These models lack the ability for doctor-like proactive inquiry and multi-turn comprehension and cannot always align responses with safety and professionalism experts. In this work, we introduce Zhongjing, the first Chinese medical LLaMA-based LLM that implements an entire training pipeline from pre-training to reinforcement learning with human feedback (RLHF). Additionally, we introduce a Chinese multi-turn medical dialogue dataset of 70,000 authentic doctor-patient dialogues, CMtMedQA, which significantly enhances the model's capability for complex dialogue and proactive inquiry initiation. We define a refined annotation rule and evaluation criteria given the biomedical domain's unique characteristics. Results show that our model outperforms baselines in various capacities and matches the performance of ChatGPT in a few abilities, despite having 50x training data with previous best model and 100x parameters with ChatGPT. RLHF further improves the model's instruction-following ability and safety.We also release our code, datasets and model for further research.