 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRACap: Relation-Aware Prompting for Lightweight Retrieval-Augmented Image Captioning
Sep 19, 2025Recent retrieval-augmented image captioning methods incorporate external knowledge to compensate for the limitations in comprehending complex scenes. However, current approaches face challenges in relation modeling: (1) the representation of semantic prompts is too coarse-grained to capture fine-grained relationships; (2) these methods lack explicit modeling of image objects and their semantic relationships. To address these limitations, we propose RACap, a relation-aware retrieval-augmented model for image captioning, which not only mines structured relation semantics from retrieval captions, but also identifies heterogeneous objects from the image. RACap effectively retrieves structured relation features that contain heterogeneous visual information to enhance the semantic consistency and relational expressiveness. Experimental results show that RACap, with only 10.8M trainable parameters, achieves superior performance compared to previous lightweight captioning models.
SILC-EFSA: Self-aware In-context Learning Correction for Entity-level Financial Sentiment Analysis
Dec 26, 2024



In recent years, fine-grained sentiment analysis in finance has gained significant attention, but the scarcity of entity-level datasets remains a key challenge. To address this, we have constructed the largest English and Chinese financial entity-level sentiment analysis datasets to date. Building on this foundation, we propose a novel two-stage sentiment analysis approach called Self-aware In-context Learning Correction (SILC). The first stage involves fine-tuning a base large language model to generate pseudo-labeled data specific to our task. In the second stage, we train a correction model using a GNN-based example retriever, which is informed by the pseudo-labeled data. This two-stage strategy has allowed us to achieve state-of-the-art performance on the newly constructed datasets, advancing the field of financial sentiment analysis. In a case study, we demonstrate the enhanced practical utility of our data and methods in monitoring the cryptocurrency market. Our datasets and code are available at https://github.com/NLP-Bin/SILC-EFSA.
Identifying Speakers and Addressees of Quotations in Novels with Prompt Learning
Aug 18, 2024


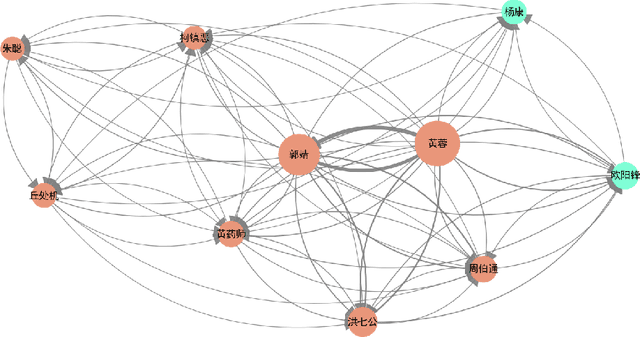
Quotations in literary works, especially novels, are important to create characters, reflect character relationships, and drive plot development. Current research on quotation extraction in novels primarily focuses on quotation attribution, i.e., identifying the speaker of the quotation. However, the addressee of the quotation is also important to construct the relationship between the speaker and the addressee. To tackle the problem of dataset scarcity, we annotate the first Chinese quotation corpus with elements including speaker, addressee, speaking mode and linguistic cue. We propose prompt learning-based methods for speaker and addressee identification based on fine-tuned pre-trained models. Experiments on both Chinese and English datasets show the effectiveness of the proposed methods, which outperform methods based on zero-shot and few-shot large language models.
LaiDA: Linguistics-aware In-context Learning with Data Augmentation for Metaphor Components Identification
Aug 10, 2024Metaphor Components Identification (MCI) contributes to enhancing machine understanding of metaphors, thereby advancing downstream natural language processing tasks. However, the complexity, diversity, and dependency on context and background knowledge pose significant challenges for MCI. Large language models (LLMs) offer new avenues for accurate comprehension of complex natural language texts due to their strong semantic analysis and extensive commonsense knowledge. In this research, a new LLM-based framework is proposed, named Linguistics-aware In-context Learning with Data Augmentation (LaiDA). Specifically, ChatGPT and supervised fine-tuning are utilized to tailor a high-quality dataset. LaiDA incorporates a simile dataset for pre-training. A graph attention network encoder generates linguistically rich feature representations to retrieve similar examples. Subsequently, LLM is fine-tuned with prompts that integrate linguistically similar examples. LaiDA ranked 2nd in Subtask 2 of NLPCC2024 Shared Task 9, demonstrating its effectiveness. Code and data are available at https://github.com/WXLJZ/LaiDA.
FaiMA: Feature-aware In-context Learning for Multi-domain Aspect-based Sentiment Analysis
Mar 02, 2024



Multi-domain aspect-based sentiment analysis (ABSA) seeks to capture fine-grained sentiment across diverse domains. While existing research narrowly focuses on single-domain applications constrained by methodological limitations and data scarcity, the reality is that sentiment naturally traverses multiple domains. Although large language models (LLMs) offer a promising solution for ABSA, it is difficult to integrate effectively with established techniques, including graph-based models and linguistics, because modifying their internal architecture is not easy. To alleviate this problem, we propose a novel framework, Feature-aware In-context Learning for Multi-domain ABSA (FaiMA). The core insight of FaiMA is to utilize in-context learning (ICL) as a feature-aware mechanism that facilitates adaptive learning in multi-domain ABSA tasks. Specifically, we employ a multi-head graph attention network as a text encoder optimized by heuristic rules for linguistic, domain, and sentiment features. Through contrastive learning, we optimize sentence representations by focusing on these diverse features. Additionally, we construct an efficient indexing mechanism, allowing FaiMA to stably retrieve highly relevant examples across multiple dimensions for any given input. To evaluate the efficacy of FaiMA, we build the first multi-domain ABSA benchmark dataset. Extensive experimental results demonstrate that FaiMA achieves significant performance improvements in multiple domains compared to baselines, increasing F1 by 2.07% on average. Source code and data sets are anonymously available at https://github.com/SupritYoung/FaiMA.