 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybriMoE: Hybrid CPU-GPU Scheduling and Cache Management for Efficient MoE Inference
Apr 08, 2025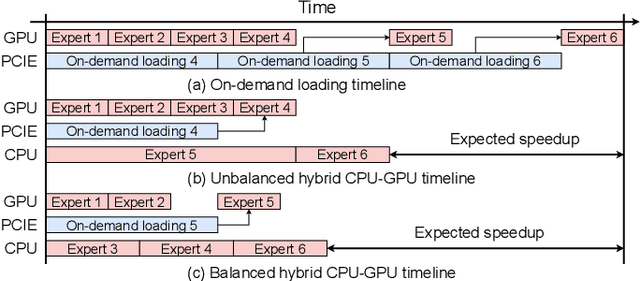
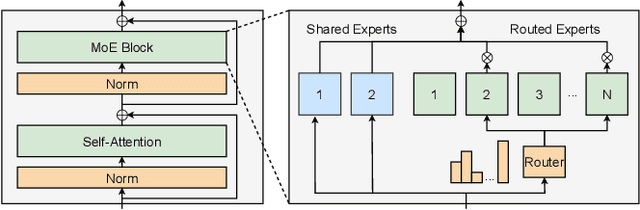
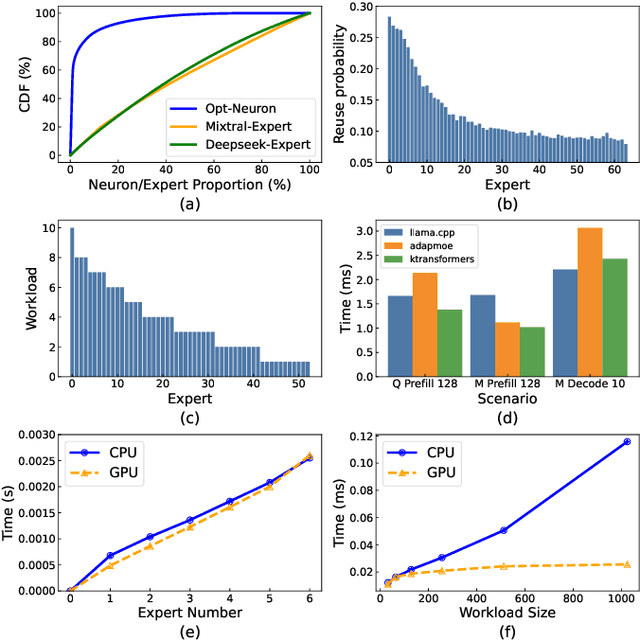
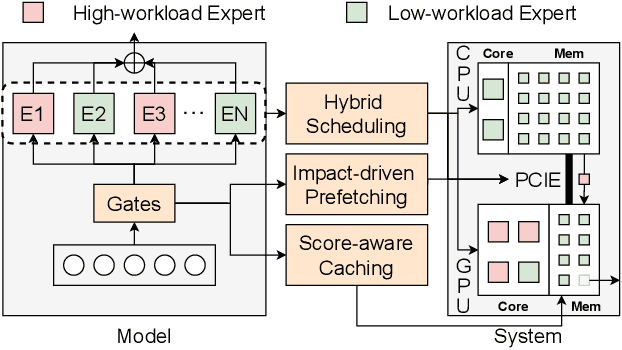
The Mixture of Experts (MoE) architecture has demonstrated significant advantages as it enables to increase the model capacity without a proportional increase in computation. However, the large MoE model size still introduces substantial memory demands, which usually requires expert offloading on resource-constrained platforms and incurs significant overhead. Hybrid CPU-GPU inference has been proposed to leverage CPU computation to reduce expert loading overhead but faces major challenges: on one hand, the expert activation patterns of MoE models are highly unstable, rendering the fixed mapping strategies in existing works inefficient; on the other hand, the hybrid CPU-GPU schedule for MoE is inherently complex due to the diverse expert sizes, structures, uneven workload distribution, etc. To address these challenges, in this paper, we propose HybriMoE, a hybrid CPU-GPU inference framework that improves resource utilization through a novel CPU-GPU scheduling and cache management system. HybriMoE introduces (i) a dynamic intra-layer scheduling strategy to balance workloads across CPU and GPU, (ii) an impact-driven inter-layer prefetching algorithm, and (iii) a score-based caching algorithm to mitigate expert activation instability. We implement HybriMoE on top of the kTransformers framework and evaluate it on three widely used MoE-based LLMs. Experimental results demonstrate that HybriMoE achieves an average speedup of 1.33$\times$ in the prefill stage and 1.70$\times$ in the decode stage compared to state-of-the-art hybrid MoE inference framework. Our code is available at: https://github.com/PKU-SEC-Lab/HybriMoE.
MCUBERT: Memory-Efficient BERT Inference on Commodity Microcontrollers
Oct 23, 2024



In this paper, we propose MCUBERT to enable language models like BERT on tiny microcontroller units (MCUs) through network and scheduling co-optimization. We observe the embedding table contributes to the major storage bottleneck for tiny BERT models. Hence, at the network level, we propose an MCU-aware two-stage neural architecture search algorithm based on clustered low-rank approximation for embedding compression. To reduce the inference memory requirements, we further propose a novel fine-grained MCU-friendly scheduling strategy. Through careful computation tiling and re-ordering as well as kernel design, we drastically increase the input sequence lengths supported on MCUs without any latency or accuracy penalty. MCUBERT reduces the parameter size of BERT-tiny and BERT-mini by 5.7$\times$ and 3.0$\times$ and the execution memory by 3.5$\times$ and 4.3$\times$, respectively. MCUBERT also achieves 1.5$\times$ latency reduction. For the first time, MCUBERT enables lightweight BERT models on commodity MCUs and processing more than 512 tokens with less than 256KB of memory.
AdapMoE: Adaptive Sensitivity-based Expert Gating and Management for Efficient MoE Inference
Aug 19, 2024
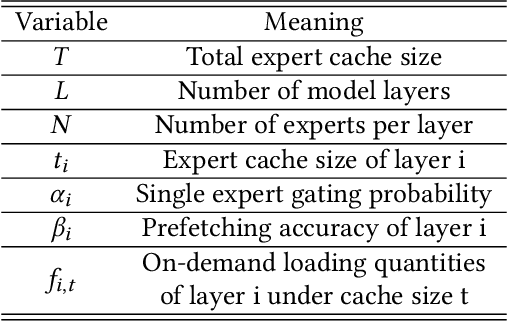
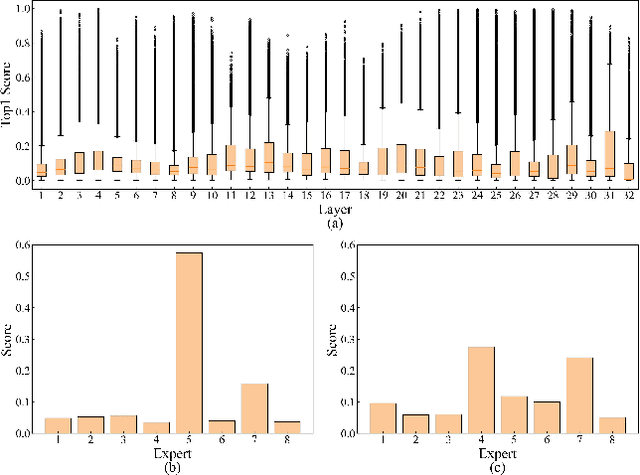
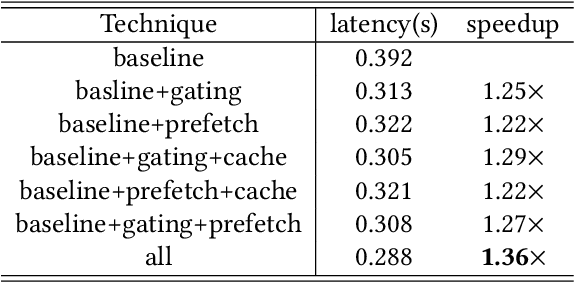
Mixture-of-Experts (MoE) models are designed to enhance the efficiency of large language models (LLMs) without proportionally increasing the computational demands. However, their deployment on edge devices still faces significant challenges due to high on-demand loading overheads from managing sparsely activated experts. This paper introduces AdapMoE, an algorithm-system co-design framework for efficient MoE inference. AdapMoE features adaptive expert gating and management to reduce the on-demand loading overheads. We observe the heterogeneity of experts loading across layers and tokens, based on which we propose a sensitivity-based strategy to adjust the number of activated experts dynamically. Meanwhile, we also integrate advanced prefetching and cache management techniques to further reduce the loading latency. Through comprehensive evaluations on various platforms, we demonstrate AdapMoE consistently outperforms existing techniques, reducing the average number of activated experts by 25% and achieving a 1.35x speedup without accuracy degradation. Code is available at: https://github.com/PKU-SEC-Lab/AdapMoE.
The Exploration-Exploitation Dilemma Revisited: An Entropy Perspective
Aug 19, 2024

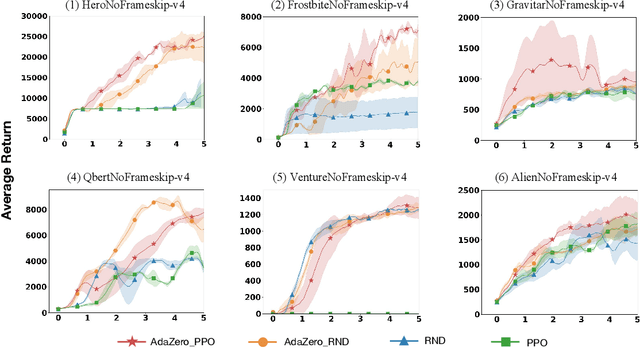
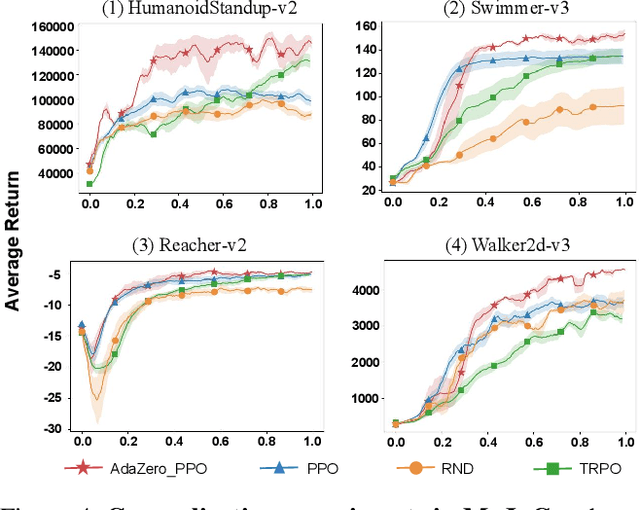
The imbalance of exploration and exploitation has long been a significant challenge in reinforcement learning. In policy optimization, excessive reliance on exploration reduces learning efficiency, while over-dependence on exploitation might trap agents in local optima. This paper revisits the exploration-exploitation dilemma from the perspective of entropy by revealing the relationship between entropy and the dynamic adaptive process of exploration and exploitation. Based on this theoretical insight, we establish an end-to-end adaptive framework called AdaZero, which automatically determines whether to explore or to exploit as well as their balance of strength. Experiments show that AdaZero significantly outperforms baseline models across various Atari and MuJoCo environments with only a single setting. Especially in the challenging environment of Montezuma, AdaZero boosts the final returns by up to fifteen times. Moreover, we conduct a series of visualization analyses to reveal the dynamics of our self-adaptive mechanism, demonstrating how entropy reflects and changes with respect to the agent's performance and adaptive process.
GAIA: Rethinking Action Quality Assessment for AI-Generated Videos
Jun 10, 2024



Assessing action quality is both imperative and challenging due to its significant impact on the quality of AI-generated videos, further complicated by the inherently ambiguous nature of actions within AI-generated video (AIGV). Current action quality assessment (AQA) algorithms predominantly focus on actions from real specific scenarios and are pre-trained with normative action features, thus rendering them inapplicable in AIGVs. To address these problems, we construct GAIA, a Generic AI-generated Action dataset, by conducting a large-scale subjective evaluation from a novel causal reasoning-based perspective, resulting in 971,244 ratings among 9,180 video-action pairs. Based on GAIA, we evaluate a suite of popular text-to-video (T2V) models on their ability to generate visually rational actions, revealing their pros and cons on different categories of actions. We also extend GAIA as a testbed to benchmark the AQA capacity of existing automatic evaluation methods. Results show that traditional AQA methods, action-related metrics in recent T2V benchmarks, and mainstream video quality methods correlate poorly with human opinions, indicating a sizable gap between current models and human action perception patterns in AIGVs. Our findings underscore the significance of action quality as a unique perspective for studying AIGVs and can catalyze progress towards methods with enhanced capacities for AQA in AIGVs.
FastQuery: Communication-efficient Embedding Table Query for Private LLM Inference
May 25, 2024With the fast evolution of large language models (LLMs), privacy concerns with user queries arise as they may contain sensitive information. Private inference based on homomorphic encryption (HE) has been proposed to protect user query privacy. However, a private embedding table query has to be formulated as a HE-based matrix-vector multiplication problem and suffers from enormous computation and communication overhead. We observe the overhead mainly comes from the neglect of 1) the one-hot nature of user queries and 2) the robustness of the embedding table to low bit-width quantization noise. Hence, in this paper, we propose a private embedding table query optimization framework, dubbed FastQuery. FastQuery features a communication-aware embedding table quantization algorithm and a one-hot-aware dense packing algorithm to simultaneously reduce both the computation and communication costs. Compared to prior-art HE-based frameworks, e.g., Cheetah, Iron, and Bumblebee, FastQuery achieves more than $4.3\times$, $2.7\times$, $1.3\times$ latency reduction, respectively and more than $75.7\times$, $60.2\times$, $20.2\times$ communication reduction, respectively, on both LLAMA-7B and LLAMA-30B.
EasyACIM: An End-to-End Automated Analog CIM with Synthesizable Architecture and Agile Design Space Exploration
Apr 12, 2024Analog Computing-in-Memory (ACIM) is an emerging architecture to perform efficient AI edge computing. However, current ACIM designs usually have unscalable topology and still heavily rely on manual efforts. These drawbacks limit the ACIM application scenarios and lead to an undesired time-to-market. This work proposes an end-to-end automated ACIM based on a synthesizable architecture (EasyACIM). With a given array size and customized cell library, EasyACIM can generate layouts for ACIMs with various design specifications end-to-end automatically. Leveraging the multi-objective genetic algorithm (MOGA)-based design space explorer, EasyACIM can obtain high-quality ACIM solutions based on the proposed synthesizable architecture, targeting versatile application scenarios. The ACIM solutions given by EasyACIM have a wide design space and competitive performance compared to the state-of-the-art (SOTA) ACIMs.
PDNNet: PDN-Aware GNN-CNN Heterogeneous Network for Dynamic IR Drop Prediction
Mar 27, 2024
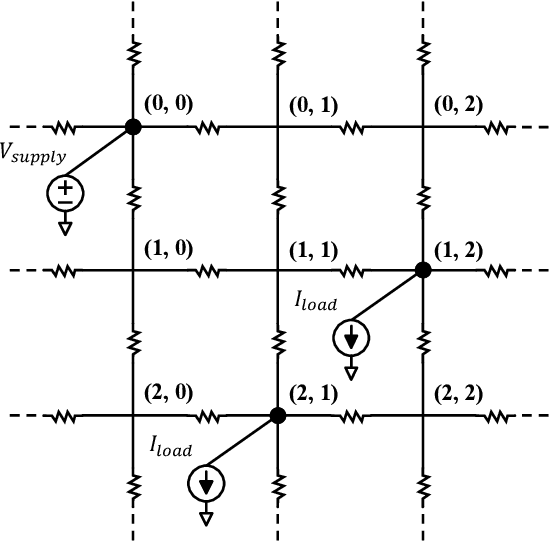
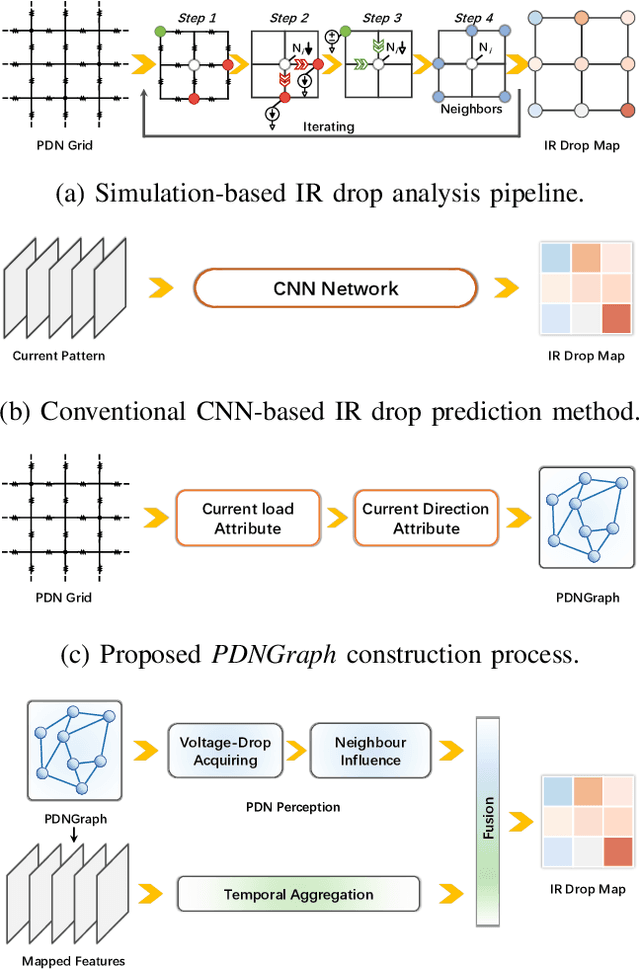
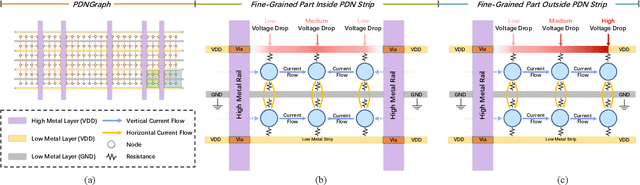
IR drop on the power delivery network (PDN) is closely related to PDN's configuration and cell current consumption. As the integrated circuit (IC) design is growing larger, dynamic IR drop simulation becomes computationally unaffordable and machine learning based IR drop prediction has been explored as a promising solution. Although CNN-based methods have been adapted to IR drop prediction task in several works, the shortcomings of overlooking PDN configuration is non-negligible. In this paper, we consider not only how to properly represent cell-PDN relation, but also how to model IR drop following its physical nature in the feature aggregation procedure. Thus, we propose a novel graph structure, PDNGraph, to unify the representations of the PDN structure and the fine-grained cell-PDN relation. We further propose a dual-branch heterogeneous network, PDNNet, incorporating two parallel GNN-CNN branches to favorably capture the above features during the learning process. Several key designs are presented to make the dynamic IR drop prediction highly effective and interpretable. We are the first work to apply graph structure to deep-learning based dynamic IR drop prediction method. Experiments show that PDNNet outperforms the state-of-the-art CNN-based methods by up to 39.3% reduction in prediction error and achieves 545x speedup compared to the commercial tool, which demonstrates the superiority of our method.
ProPD: Dynamic Token Tree Pruning and Generation for LLM Parallel Decoding
Feb 21, 2024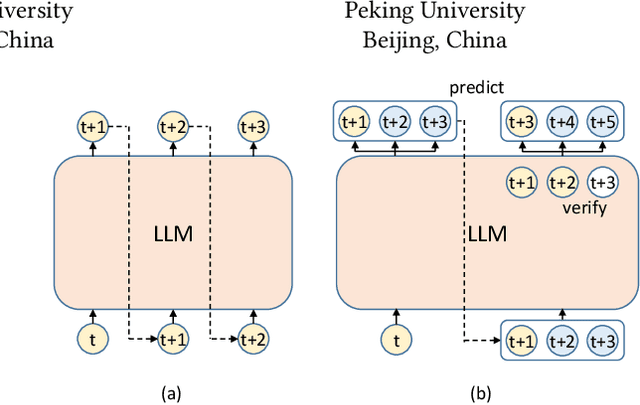
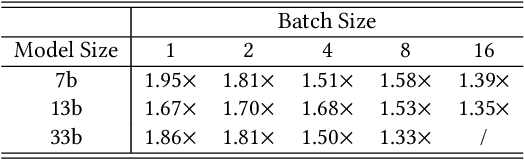
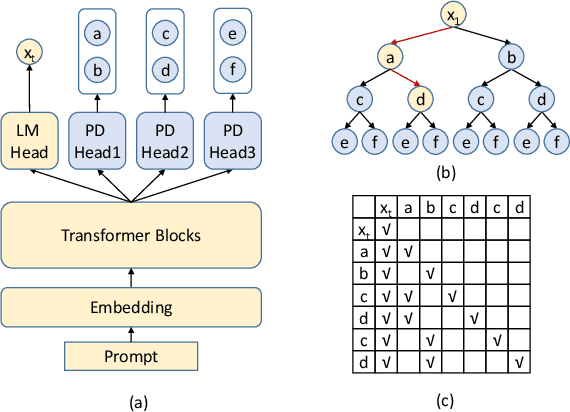
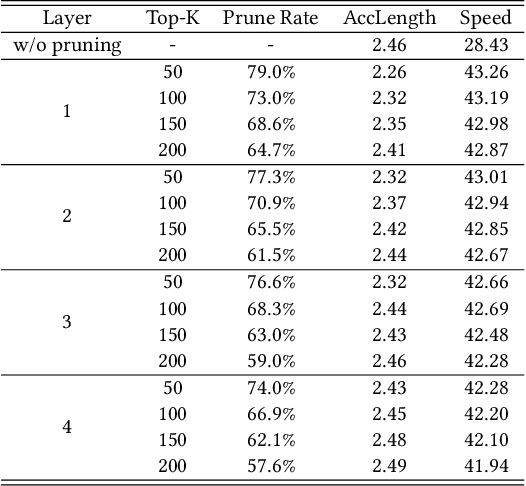
Recent advancements in generative large language models (LLMs) have significantly boosted the performance in natural language processing tasks. However, their efficiency is hampered by the inherent limitations in autoregressive token generation. While parallel decoding with token tree verification, e.g., Medusa, has been proposed to improve decoding parallelism and efficiency, it often struggles with maintaining contextual relationships due to its independent token prediction approach and incurs significant verification overhead, especially with large tree sizes and batch processing. In this paper, we propose ProPD, an efficient LLM parallel decoding framework based on dynamic token tree pruning and generation. ProPD features an advanced early pruning mechanism to efficiently eliminate unpromising token sequences to improve verification efficiency. Additionally, it introduces a dynamic token tree generation algorithm to balance the computation and parallelism of the verification phase in real-time and maximize the overall efficiency across different batch sizes, sequence lengths, and tasks, etc. We verify ProPD across a diverse set of datasets, LLMs, and batch sizes and demonstrate ProPD consistently outperforms existing decoding algorithms by 1.1-3.2x.
AttentionLego: An Open-Source Building Block For Spatially-Scalable Large Language Model Accelerator With Processing-In-Memory Technology
Jan 21, 2024Large language models (LLMs) with Transformer architectures have become phenomenal in natural language processing, multimodal generative artificial intelligence, and agent-oriented artificial intelligence. The self-attention module is the most dominating sub-structure inside Transformer-based LLMs. Computation using general-purpose graphics processing units (GPUs) inflicts reckless demand for I/O bandwidth for transferring intermediate calculation results between memories and processing units. To tackle this challenge, this work develops a fully customized vanilla self-attention accelerator, AttentionLego, as the basic building block for constructing spatially expandable LLM processors. AttentionLego provides basic implementation with fully-customized digital logic incorporating Processing-In-Memory (PIM) technology. It is based on PIM-based matrix-vector multiplication and look-up table-based Softmax design. The open-source code is available online: https://bonany.cc/attentionleg.