 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEGMamba: Bidirectional State Space Models with Mixture of Experts for EEG Classification
Jul 20, 2024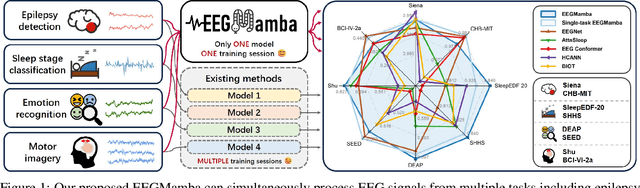
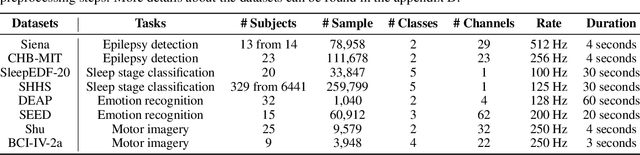
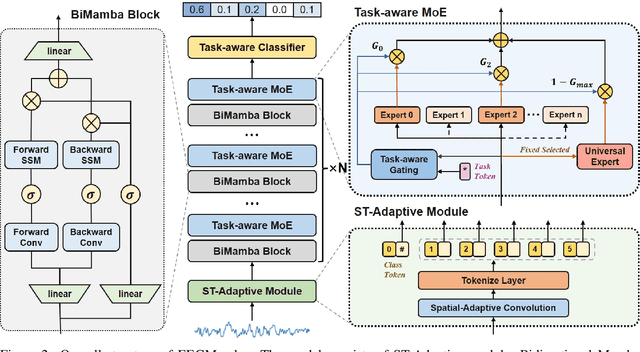
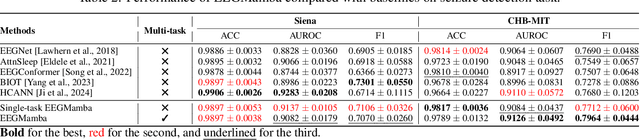
In recent years, with the development of deep learning, electroencephalogram (EEG) classification networks have achieved certain progress. Transformer-based models can perform well in capturing long-term dependencies in EEG signals. However, their quadratic computational complexity leads to significant computational overhead. Moreover, most EEG classification models are only suitable for single tasks, showing poor generalization capabilities across different tasks and further unable to handle EEG data from various tasks simultaneously due to variations in signal length and the number of channels. In this paper, we introduce a universal EEG classification network named EEGMamba, which seamlessly integrates the Spatio-Temporal-Adaptive (ST-Adaptive) module, Bidirectional Mamba, and Mixture of Experts (MoE) into a unified framework for multiple tasks. The proposed ST-Adaptive module performs unified feature extraction on EEG signals of different lengths and channel counts through spatio-adaptive convolution and incorporates a class token to achieve temporal-adaptability. Moreover, we design a bidirectional Mamba particularly suitable for EEG signals for further feature extraction, balancing high accuracy and fast inference speed in processing long EEG signals. In order to better process EEG data for different tasks, we introduce Task-aware MoE with a universal expert, achieving the capture of both differences and commonalities between EEG data from different tasks. We test our model on eight publicly available EEG datasets, and experimental results demonstrate its superior performance in four types of tasks: seizure detection, emotion recognition, sleep stage classification, and motor imagery. The code is set to be released soon.
Improving EEG Classification Through Randomly Reassembling Original and Generated Data with Transformer-based Diffusion Models
Jul 20, 2024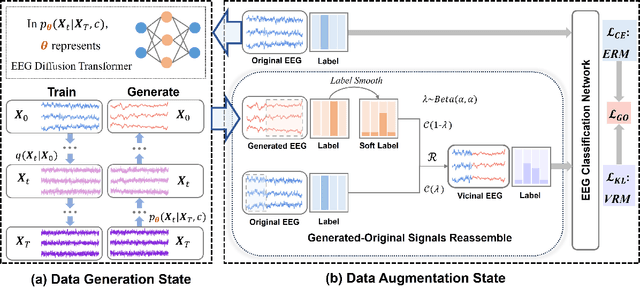
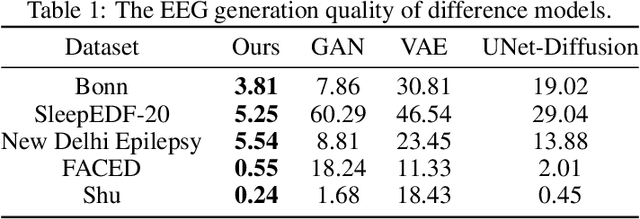
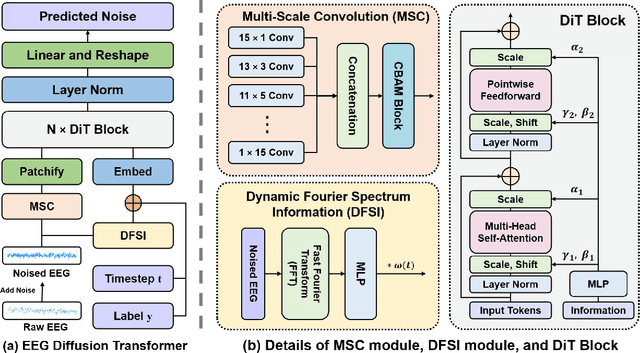
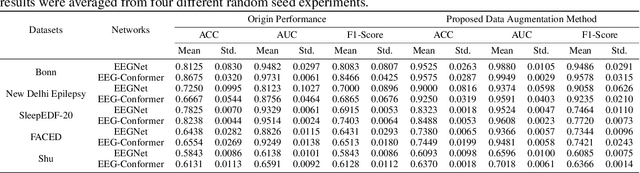
Electroencephalogram (EEG) classification has been widely used in various medical and engineering applications, where it is important for understanding brain function, diagnosing diseases, and assessing mental health conditions. However, the scarcity of EEG data severely restricts the performance of EEG classification networks, and generative model-based data augmentation methods emerging as potential solutions to overcome this challenge. There are two problems with existing such methods: (1) The quality of the generated EEG signals is not high. (2) The enhancement of EEG classification networks is not effective. In this paper, we propose a Transformer-based denoising diffusion probabilistic model and a generated data-based data augmentation method to address the above two problems. For the characteristics of EEG signals, we propose a constant-factor scaling method to preprocess the signals, which reduces the loss of information. We incorporated Multi-Scale Convolution and Dynamic Fourier Spectrum Information modules into the model, improving the stability of the training process and the quality of the generated data. The proposed augmentation method randomly reassemble the generated data with original data in the time-domain to obtain vicinal data, which improves the model performance by minimizing the empirical risk and the vicinal risk. We experiment the proposed augmentation method on five EEG datasets for four tasks and observe significant accuracy performance improvements: 14.00% on the Bonn dataset; 25.83% on the New Delhi epilepsy dataset; 4.98% on the SleepEDF-20 dataset; 9.42% on the FACED dataset; 2.5% on the Shu dataset. We intend to make the code of our method publicly accessible shortly
Roadmap to Neuromorphic Computing with Emerging Technologies
Jul 02, 2024



The roadmap is organized into several thematic sections, outlining current computing challenges, discussing the neuromorphic computing approach, analyzing mature and currently utilized technologies, providing an overview of emerging technologies, addressing material challenges, exploring novel computing concepts, and finally examining the maturity level of emerging technologies while determining the next essential steps for their advancement.
AttentionLego: An Open-Source Building Block For Spatially-Scalable Large Language Model Accelerator With Processing-In-Memory Technology
Jan 21, 2024Large language models (LLMs) with Transformer architectures have become phenomenal in natural language processing, multimodal generative artificial intelligence, and agent-oriented artificial intelligence. The self-attention module is the most dominating sub-structure inside Transformer-based LLMs. Computation using general-purpose graphics processing units (GPUs) inflicts reckless demand for I/O bandwidth for transferring intermediate calculation results between memories and processing units. To tackle this challenge, this work develops a fully customized vanilla self-attention accelerator, AttentionLego, as the basic building block for constructing spatially expandable LLM processors. AttentionLego provides basic implementation with fully-customized digital logic incorporating Processing-In-Memory (PIM) technology. It is based on PIM-based matrix-vector multiplication and look-up table-based Softmax design. The open-source code is available online: https://bonany.cc/attentionleg.
Human-Machine Cooperative Multimodal Learning Method for Cross-subject Olfactory Preference Recognition
Nov 24, 2023Odor sensory evaluation has a broad application in food, clothing, cosmetics, and other fields. Traditional artificial sensory evaluation has poor repeatability, and the machine olfaction represented by the electronic nose (E-nose) is difficult to reflect human feelings. Olfactory electroencephalogram (EEG) contains odor and individual features associated with human olfactory preference, which has unique advantages in odor sensory evaluation. However, the difficulty of cross-subject olfactory EEG recognition greatly limits its application. It is worth noting that E-nose and olfactory EEG are more advantageous in representing odor information and individual emotions, respectively. In this paper, an E-nose and olfactory EEG multimodal learning method is proposed for cross-subject olfactory preference recognition. Firstly, the olfactory EEG and E-nose multimodal data acquisition and preprocessing paradigms are established. Secondly, a complementary multimodal data mining strategy is proposed to effectively mine the common features of multimodal data representing odor information and the individual features in olfactory EEG representing individual emotional information. Finally, the cross-subject olfactory preference recognition is achieved in 24 subjects by fusing the extracted common and individual features, and the recognition effect is superior to the state-of-the-art recognition methods. Furthermore, the advantages of the proposed method in cross-subject olfactory preference recognition indicate its potential for practical odor evaluation applications.
Decoding Taste Information in Human Brain: A Temporal and Spatial Reconstruction Data Augmentation Method Coupled with Taste EEG
Jul 01, 2023For humans, taste is essential for perceiving food's nutrient content or harmful components. The current sensory evaluation of taste mainly relies on artificial sensory evaluation and electronic tongue, but the former has strong subjectivity and poor repeatability, and the latter is not flexible enough. This work proposed a strategy for acquiring and recognizing taste electroencephalogram (EEG), aiming to decode people's objective perception of taste through taste EEG. Firstly, according to the proposed experimental paradigm, the taste EEG of subjects under different taste stimulation was collected. Secondly, to avoid insufficient training of the model due to the small number of taste EEG samples, a Temporal and Spatial Reconstruction Data Augmentation (TSRDA) method was proposed, which effectively augmented the taste EEG by reconstructing the taste EEG's important features in temporal and spatial dimensions. Thirdly, a multi-view channel attention module was introduced into a designed convolutional neural network to extract the important features of the augmented taste EEG. The proposed method has accuracy of 99.56%, F1-score of 99.48%, and kappa of 99.38%, proving the method's ability to distinguish the taste EEG evoked by different taste stimuli successfully. In summary, combining TSRDA with taste EEG technology provides an objective and effective method for sensory evaluation of food taste.
Fast and Scalable Memristive In-Memory Sorting with Column-Skipping Algorithm
Feb 15, 2022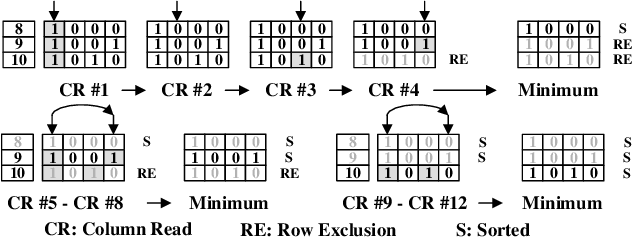
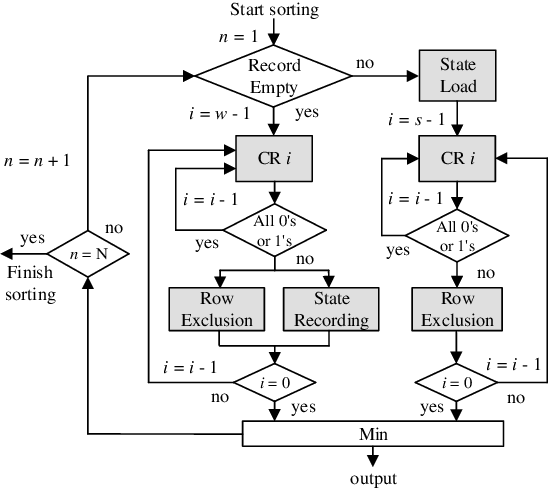
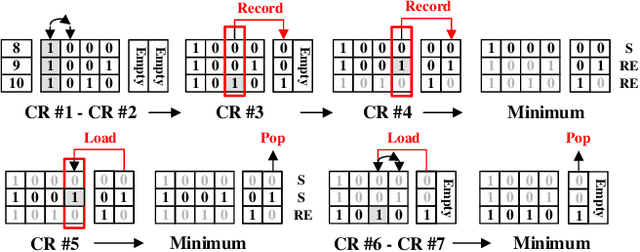
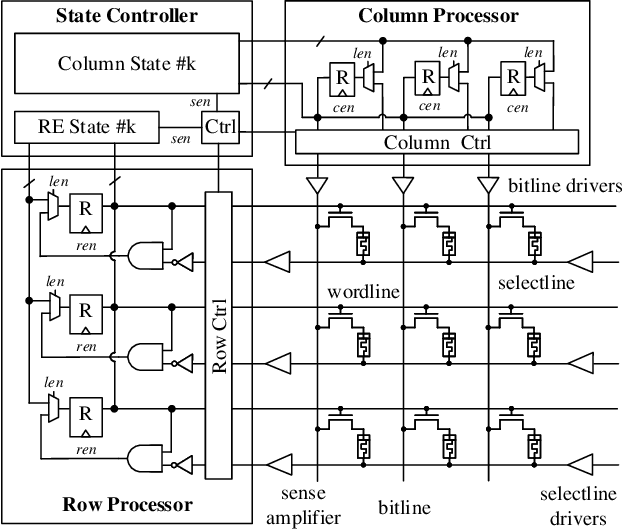
Memristive in-memory sorting has been proposed recently to improve hardware sorting efficiency. Using iterative in-memory min computations, data movements between memory and external processing units can be eliminated for improved latency and energy efficiency. However, the bit-traversal algorithm to search the min requires a large number of column reads on memristive memory. In this work, we propose a column-skipping algorithm with help of a near-memory circuit. Redundant column reads can be skipped based on recorded states for improved latency and hardware efficiency. To enhance the scalability, we develop a multi-bank management that enables column-skipping for dataset stored in different memristive memory banks. Prototype column-skipping sorters are implemented with a 1T1R memristive memory in 40nm CMOS technology. Experimented on a variety of sorting datasets, the length-1024 32-bit column-skipping sorter with state recording of 2 demonstrates up to 4.08x speedup, 3.14x area efficiency and 3.39x energy efficiency, respectively, over the latest memristive in-memory sorting.
SSPNet: Scale Selection Pyramid Network for Tiny Person Detection from UAV Images
Jul 04, 2021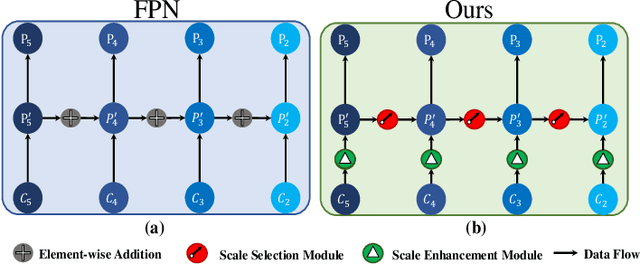
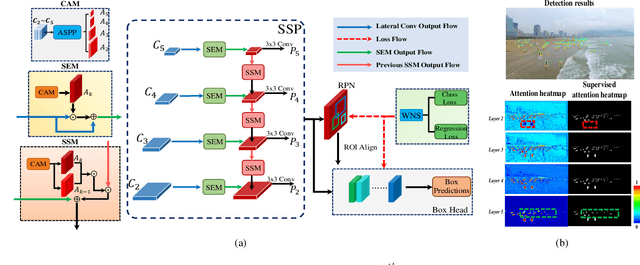

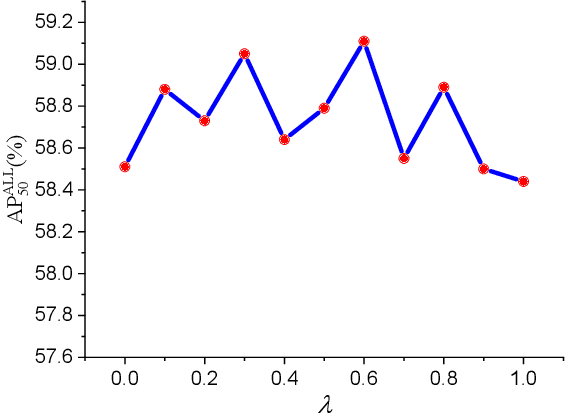
With the increasing demand for search and rescue, it is highly demanded to detect objects of interest in large-scale images captured by Unmanned Aerial Vehicles (UAVs), which is quite challenging due to extremely small scales of objects. Most existing methods employed Feature Pyramid Network (FPN) to enrich shallow layers' features by combing deep layers' contextual features. However, under the limitation of the inconsistency in gradient computation across different layers, the shallow layers in FPN are not fully exploited to detect tiny objects. In this paper, we propose a Scale Selection Pyramid network (SSPNet) for tiny person detection, which consists of three components: Context Attention Module (CAM), Scale Enhancement Module (SEM), and Scale Selection Module (SSM). CAM takes account of context information to produce hierarchical attention heatmaps. SEM highlights features of specific scales at different layers, leading the detector to focus on objects of specific scales instead of vast backgrounds. SSM exploits adjacent layers' relationships to fulfill suitable feature sharing between deep layers and shallow layers, thereby avoiding the inconsistency in gradient computation across different layers. Besides, we propose a Weighted Negative Sampling (WNS) strategy to guide the detector to select more representative samples. Experiments on the TinyPerson benchmark show that our method outperforms other state-of-the-art (SOTA) detectors.
Coherent Integration for Targets with Constant Cartesian Velocities Based on Accurate Range Model
Feb 19, 2021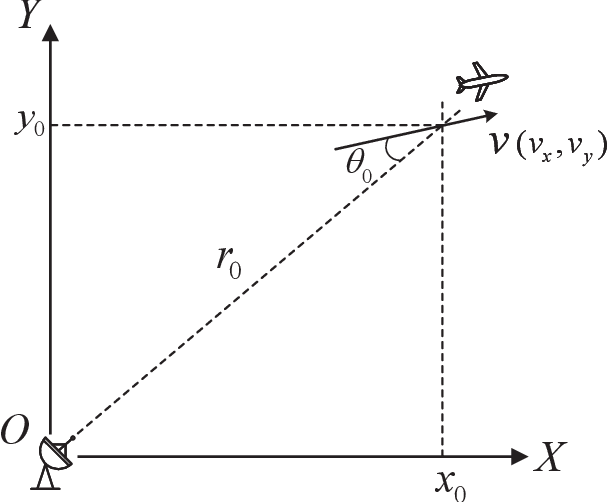

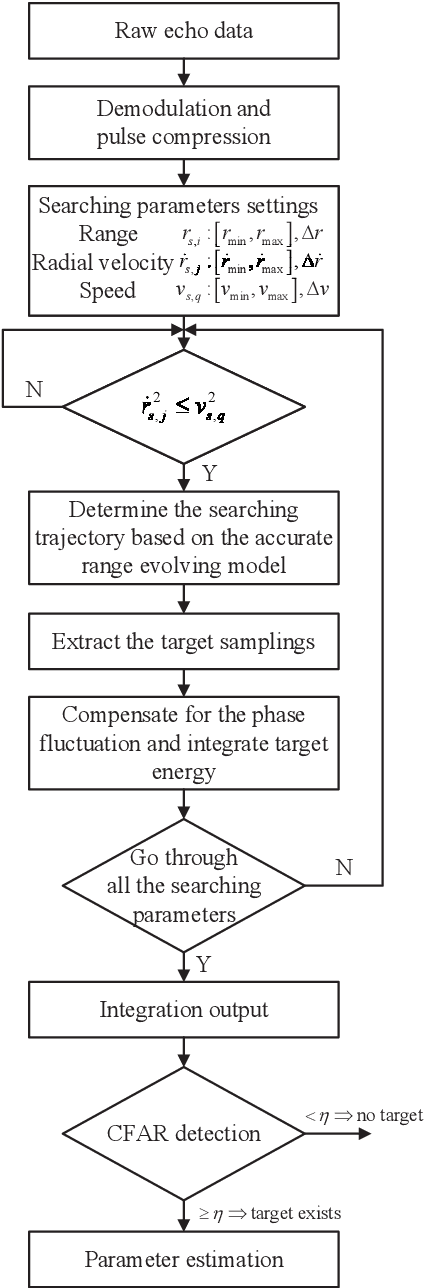

Long-time coherent integration (LTCI) is one of the most important techniques to improve radar detection performance of weak targets. However, for the targets moving with constant Cartesian velocities (CCV), the existing LTCI methods based on polynomial motion models suffer from limited integration time and coverage of target speed due to model mismatch. Here, a novel generalized Radon Fourier transform method for CCV targets is presented, based on the accurate range evolving model, which is a square root of a polynomial with terms up to the second order with target speed as the factor. The accurate model instead of approximate polynomial models used in the proposed method enables effective energy integration on characteristic invariant with feasible computational complexity. The target samplings are collected and the phase fluctuation among pulses is compensated according to the accurate range model. The high order range migration and complex Doppler frequency migration caused by the highly nonlinear signal are eliminated simultaneously. Integration results demonstrate that the proposed method can not only achieve effective coherent integration of CCV targets regardless of target speed and coherent processing interval, but also provide additional observation and resolution in speed domain.
S3-Net: A Fast and Lightweight Video Scene Understanding Network by Single-shot Segmentation
Nov 04, 2020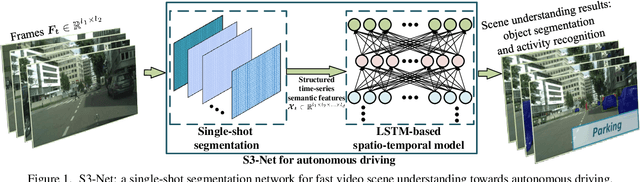
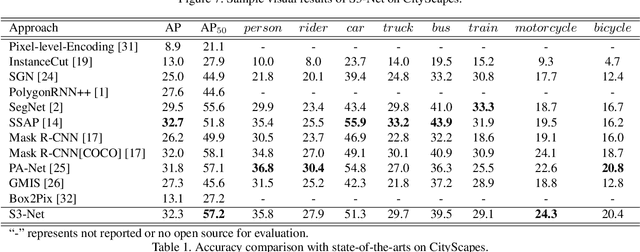
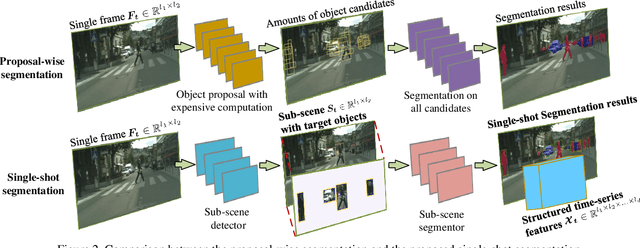
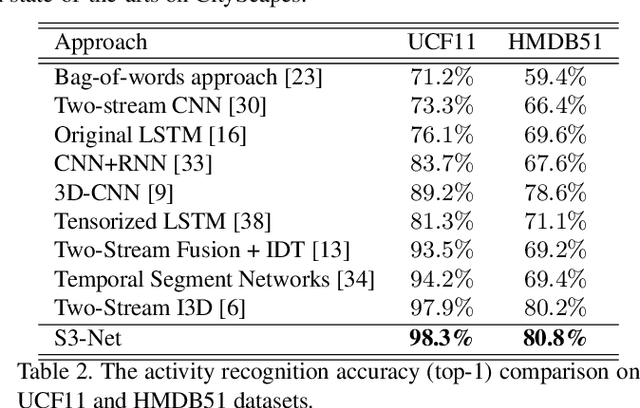
Real-time understanding in video is crucial in various AI applications such as autonomous driving. This work presents a fast single-shot segmentation strategy for video scene understanding. The proposed net, called S3-Net, quickly locates and segments target sub-scenes, meanwhile extracts structured time-series semantic features as inputs to an LSTM-based spatio-temporal model. Utilizing tensorization and quantization techniques, S3-Net is intended to be lightweight for edge computing. Experiments using CityScapes, UCF11, HMDB51 and MOMENTS datasets demonstrate that the proposed S3-Net achieves an accuracy improvement of 8.1% versus the 3D-CNN based approach on UCF11, a storage reduction of 6.9x and an inference speed of 22.8 FPS on CityScapes with a GTX1080Ti GPU.