 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Look Around: Learning Illumination Invariant Feature for Low-light Object Detection
Oct 24, 2024In this paper, we introduce YOLA, a novel framework for object detection in low-light scenarios. Unlike previous works, we propose to tackle this challenging problem from the perspective of feature learning. Specifically, we propose to learn illumination-invariant features through the Lambertian image formation model. We observe that, under the Lambertian assumption, it is feasible to approximate illumination-invariant feature maps by exploiting the interrelationships between neighboring color channels and spatially adjacent pixels. By incorporating additional constraints, these relationships can be characterized in the form of convolutional kernels, which can be trained in a detection-driven manner within a network. Towards this end, we introduce a novel module dedicated to the extraction of illumination-invariant features from low-light images, which can be easily integrated into existing object detection frameworks. Our empirical findings reveal significant improvements in low-light object detection tasks, as well as promising results in both well-lit and over-lit scenarios. Code is available at \url{https://github.com/MingboHong/YOLA}.
Neural Spectral Decomposition for Dataset Distillation
Aug 29, 2024
In this paper, we propose Neural Spectrum Decomposition, a generic decomposition framework for dataset distillation. Unlike previous methods, we consider the entire dataset as a high-dimensional observation that is low-rank across all dimensions. We aim to discover the low-rank representation of the entire dataset and perform distillation efficiently. Toward this end, we learn a set of spectrum tensors and transformation matrices, which, through simple matrix multiplication, reconstruct the data distribution. Specifically, a spectrum tensor can be mapped back to the image space by a transformation matrix, and efficient information sharing during the distillation learning process is achieved through pairwise combinations of different spectrum vectors and transformation matrices. Furthermore, we integrate a trajectory matching optimization method guided by a real distribution. Our experimental results demonstrate that our approach achieves state-of-the-art performance on benchmarks, including CIFAR10, CIFAR100, Tiny Imagenet, and ImageNet Subset. Our code are available at \url{https://github.com/slyang2021/NSD}.
Single Image Rolling Shutter Removal with Diffusion Models
Jul 03, 2024


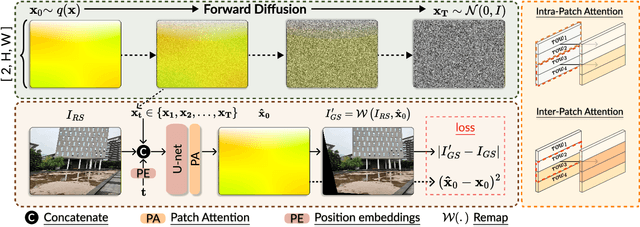
We present RS-Diffusion, the first Diffusion Models-based method for single-frame Rolling Shutter (RS) correction. RS artifacts compromise visual quality of frames due to the row wise exposure of CMOS sensors. Most previous methods have focused on multi-frame approaches, using temporal information from consecutive frames for the motion rectification. However, few approaches address the more challenging but important single frame RS correction. In this work, we present an ``image-to-motion'' framework via diffusion techniques, with a designed patch-attention module. In addition, we present the RS-Real dataset, comprised of captured RS frames alongside their corresponding Global Shutter (GS) ground-truth pairs. The GS frames are corrected from the RS ones, guided by the corresponding Inertial Measurement Unit (IMU) gyroscope data acquired during capture. Experiments show that our RS-Diffusion surpasses previous single RS correction methods. Our method and proposed RS-Real dataset lay a solid foundation for advancing the field of RS correction.
Unsupervised Homography Estimation with Coplanarity-Aware GAN
May 08, 2022

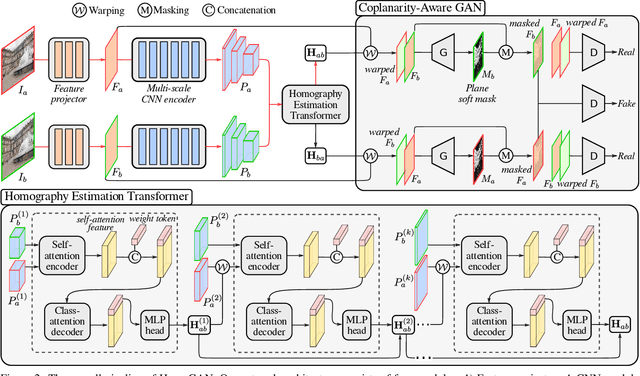

Estimating homography from an image pair is a fundamental problem in image alignment. Unsupervised learning methods have received increasing attention in this field due to their promising performance and label-free training. However, existing methods do not explicitly consider the problem of plane-induced parallax, which will make the predicted homography compromised on multiple planes. In this work, we propose a novel method HomoGAN to guide unsupervised homography estimation to focus on the dominant plane. First, a multi-scale transformer network is designed to predict homography from the feature pyramids of input images in a coarse-to-fine fashion. Moreover, we propose an unsupervised GAN to impose coplanarity constraint on the predicted homography, which is realized by using a generator to predict a mask of aligned regions, and then a discriminator to check if two masked feature maps are induced by a single homography. To validate the effectiveness of HomoGAN and its components, we conduct extensive experiments on a large-scale dataset, and the results show that our matching error is 22% lower than the previous SOTA method. Code is available at https://github.com/megvii-research/HomoGAN.
SSPNet: Scale Selection Pyramid Network for Tiny Person Detection from UAV Images
Jul 04, 2021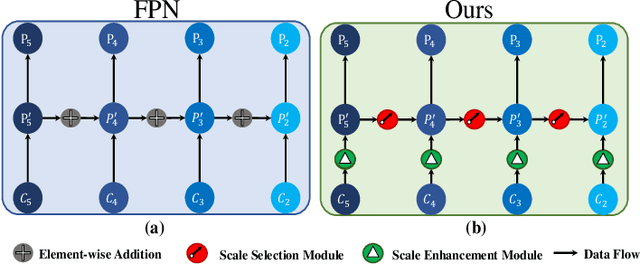
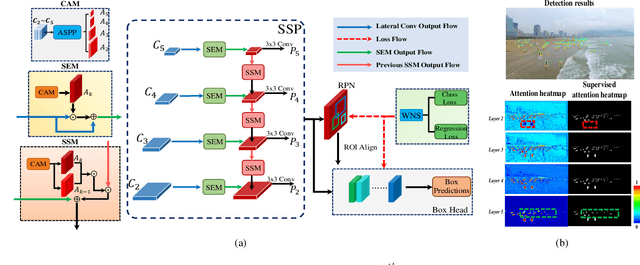

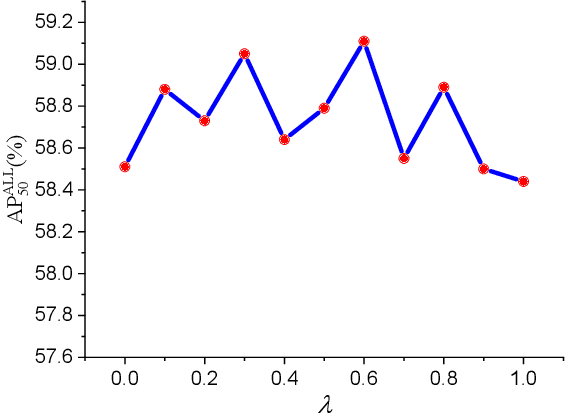
With the increasing demand for search and rescue, it is highly demanded to detect objects of interest in large-scale images captured by Unmanned Aerial Vehicles (UAVs), which is quite challenging due to extremely small scales of objects. Most existing methods employed Feature Pyramid Network (FPN) to enrich shallow layers' features by combing deep layers' contextual features. However, under the limitation of the inconsistency in gradient computation across different layers, the shallow layers in FPN are not fully exploited to detect tiny objects. In this paper, we propose a Scale Selection Pyramid network (SSPNet) for tiny person detection, which consists of three components: Context Attention Module (CAM), Scale Enhancement Module (SEM), and Scale Selection Module (SSM). CAM takes account of context information to produce hierarchical attention heatmaps. SEM highlights features of specific scales at different layers, leading the detector to focus on objects of specific scales instead of vast backgrounds. SSM exploits adjacent layers' relationships to fulfill suitable feature sharing between deep layers and shallow layers, thereby avoiding the inconsistency in gradient computation across different layers. Besides, we propose a Weighted Negative Sampling (WNS) strategy to guide the detector to select more representative samples. Experiments on the TinyPerson benchmark show that our method outperforms other state-of-the-art (SOTA) detectors.
The 1st Tiny Object Detection Challenge:Methods and Results
Oct 06, 2020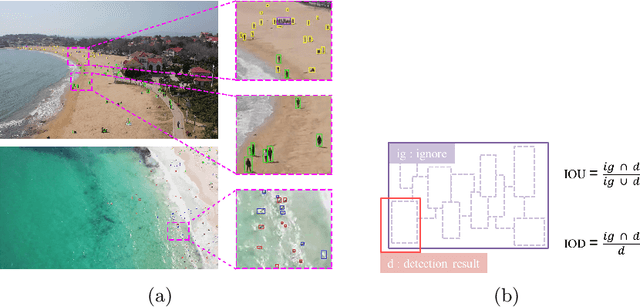
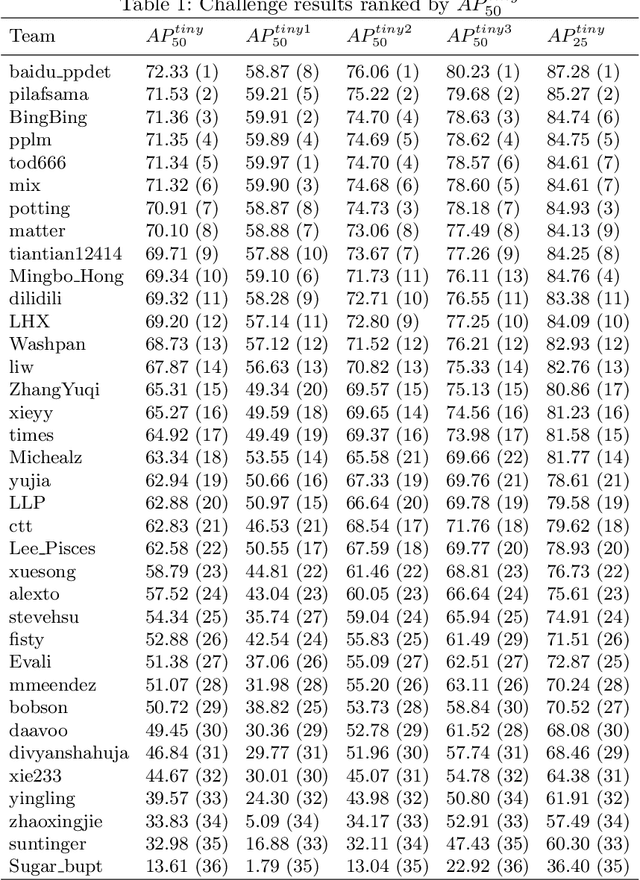
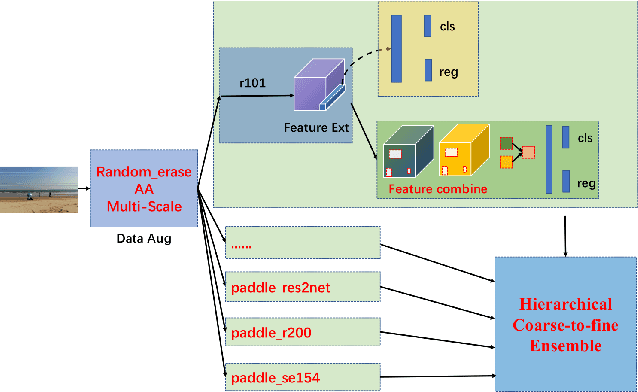

The 1st Tiny Object Detection (TOD) Challenge aims to encourage research in developing novel and accurate methods for tiny object detection in images which have wide views, with a current focus on tiny person detection. The TinyPerson dataset was used for the TOD Challenge and is publicly released. It has 1610 images and 72651 box-levelannotations. Around 36 participating teams from the globe competed inthe 1st TOD Challenge. In this paper, we provide a brief summary of the1st TOD Challenge including brief introductions to the top three methods.The submission leaderboard will be reopened for researchers that areinterested in the TOD challenge. The benchmark dataset and other information can be found at: https://github.com/ucas-vg/TinyBenchmark.