 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreprocessing Methods for Memristive Reservoir Computing for Image Recognition
Jun 05, 2025Reservoir computing (RC) has attracted attention as an efficient recurrent neural network architecture due to its simplified training, requiring only its last perceptron readout layer to be trained. When implemented with memristors, RC systems benefit from their dynamic properties, which make them ideal for reservoir construction. However, achieving high performance in memristor-based RC remains challenging, as it critically depends on the input preprocessing method and reservoir size. Despite growing interest, a comprehensive evaluation that quantifies the impact of these factors is still lacking. This paper systematically compares various preprocessing methods for memristive RC systems, assessing their effects on accuracy and energy consumption. We also propose a parity-based preprocessing method that improves accuracy by 2-6% while requiring only a modest increase in device count compared to other methods. Our findings highlight the importance of informed preprocessing strategies to improve the efficiency and scalability of memristive RC systems.
IMPACT:InMemory ComPuting Architecture Based on Y-FlAsh Technology for Coalesced Tsetlin Machine Inference
Dec 04, 2024



The increasing demand for processing large volumes of data for machine learning models has pushed data bandwidth requirements beyond the capability of traditional von Neumann architecture. In-memory computing (IMC) has recently emerged as a promising solution to address this gap by enabling distributed data storage and processing at the micro-architectural level, significantly reducing both latency and energy. In this paper, we present the IMPACT: InMemory ComPuting Architecture Based on Y-FlAsh Technology for Coalesced Tsetlin Machine Inference, underpinned on a cutting-edge memory device, Y-Flash, fabricated on a 180 nm CMOS process. Y-Flash devices have recently been demonstrated for digital and analog memory applications, offering high yield, non-volatility, and low power consumption. The IMPACT leverages the Y-Flash array to implement the inference of a novel machine learning algorithm: coalesced Tsetlin machine (CoTM) based on propositional logic. CoTM utilizes Tsetlin automata (TA) to create Boolean feature selections stochastically across parallel clauses. The IMPACT is organized into two computational crossbars for storing the TA and weights. Through validation on the MNIST dataset, IMPACT achieved 96.3% accuracy. The IMPACT demonstrated improvements in energy efficiency, e.g., 2.23X over CNN-based ReRAM, 2.46X over Neuromorphic using NOR-Flash, and 2.06X over DNN-based PCM, suited for modern ML inference applications.
VVTEAM: A Compact Behavioral Model for Volatile Memristors
Sep 26, 2024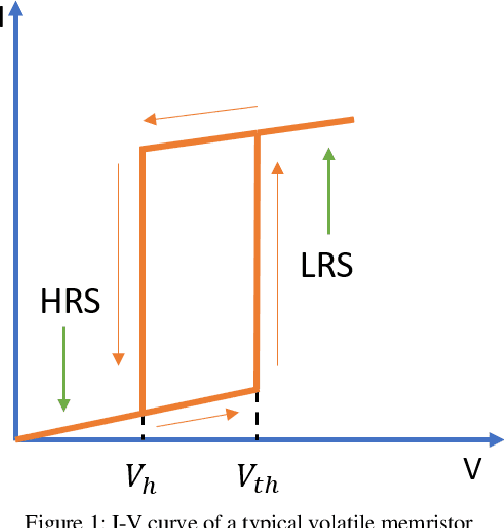
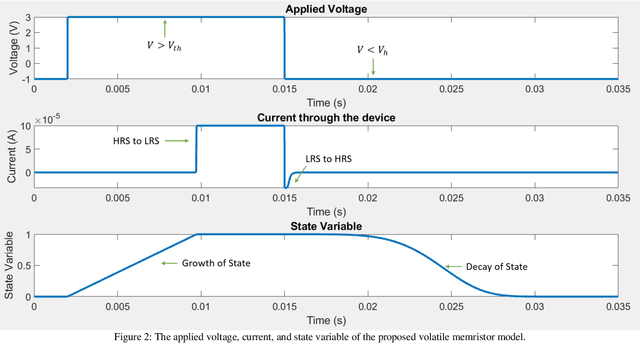
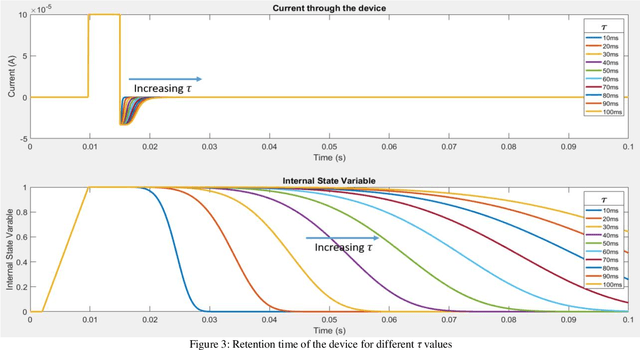
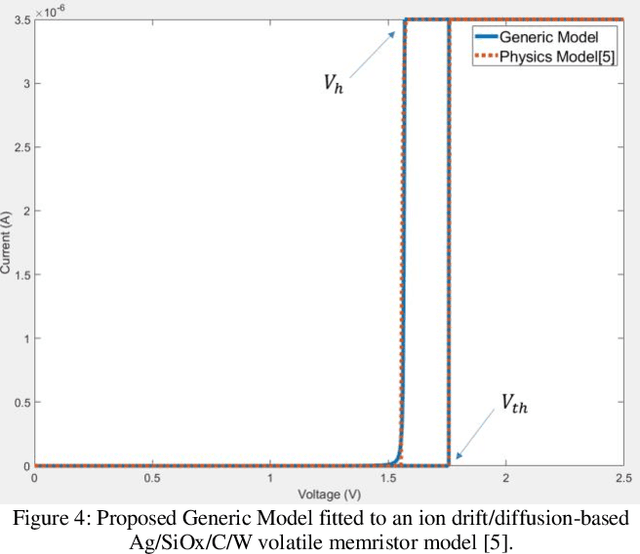
Volatile memristors have recently gained popularity as promising devices for neuromorphic circuits, capable of mimicking the leaky function of neurons and offering advantages over capacitor-based circuits in terms of power dissipation and area. Additionally, volatile memristors are useful as selector devices and for hardware security circuits such as physical unclonable functions. To facilitate the design and simulation of circuits, a compact behavioral model is essential. This paper proposes V-VTEAM, a compact, simple, general, and flexible behavioral model for volatile memristors, inspired by the VTEAM nonvolatile memristor model and developed in MATLAB. The validity of the model is demonstrated by fitting it to an ion drift/diffusion-based Ag/SiOx/C/W volatile memristor, achieving a relative root mean error square of 4.5%.
Roadmap to Neuromorphic Computing with Emerging Technologies
Jul 02, 2024



The roadmap is organized into several thematic sections, outlining current computing challenges, discussing the neuromorphic computing approach, analyzing mature and currently utilized technologies, providing an overview of emerging technologies, addressing material challenges, exploring novel computing concepts, and finally examining the maturity level of emerging technologies while determining the next essential steps for their advancement.
A Pipelined Memristive Neural Network Analog-to-Digital Converter
Jun 04, 2024



With the advent of high-speed, high-precision, and low-power mixed-signal systems, there is an ever-growing demand for accurate, fast, and energy-efficient analog-to-digital (ADCs) and digital-to-analog converters (DACs). Unfortunately, with the downscaling of CMOS technology, modern ADCs trade off speed, power and accuracy. Recently, memristive neuromorphic architectures of four-bit ADC/DAC have been proposed. Such converters can be trained in real-time using machine learning algorithms, to break through the speedpower-accuracy trade-off while optimizing the conversion performance for different applications. However, scaling such architectures above four bits is challenging. This paper proposes a scalable and modular neural network ADC architecture based on a pipeline of four-bit converters, preserving their inherent advantages in application reconfiguration, mismatch selfcalibration, noise tolerance, and power optimization, while approaching higher resolution and throughput in penalty of latency. SPICE evaluation shows that an 8-bit pipelined ADC achieves 0.18 LSB INL, 0.20 LSB DNL, 7.6 ENOB, and 0.97 fJ/conv FOM. This work presents a significant step towards the realization of large-scale neuromorphic data converters.
ClaPIM: Scalable Sequence CLAssification using Processing-In-Memory
Feb 16, 2023DNA sequence classification is a fundamental task in computational biology with vast implications for applications such as disease prevention and drug design. Therefore, fast high-quality sequence classifiers are significantly important. This paper introduces ClaPIM, a scalable DNA sequence classification architecture based on the emerging concept of hybrid in-crossbar and near-crossbar memristive processing-in-memory (PIM). We enable efficient and high-quality classification by uniting the filter and search stages within a single algorithm. Specifically, we propose a custom filtering technique that drastically narrows the search space and a search approach that facilitates approximate string matching through a distance function. ClaPIM is the first PIM architecture for scalable approximate string matching that benefits from the high density of memristive crossbar arrays and the massive computational parallelism of PIM. Compared with Kraken2, a state-of-the-art software classifier, ClaPIM provides significantly higher classification quality (up to 20x improvement in F1 score) and also demonstrates a 1.8x throughput improvement. Compared with EDAM, a recently-proposed SRAM-based accelerator that is restricted to small datasets, we observe both a 30.4x improvement in normalized throughput per area and a 7% increase in classification precision.
Efficient Training of the Memristive Deep Belief Net Immune to Non-Idealities of the Synaptic Devices
Mar 15, 2022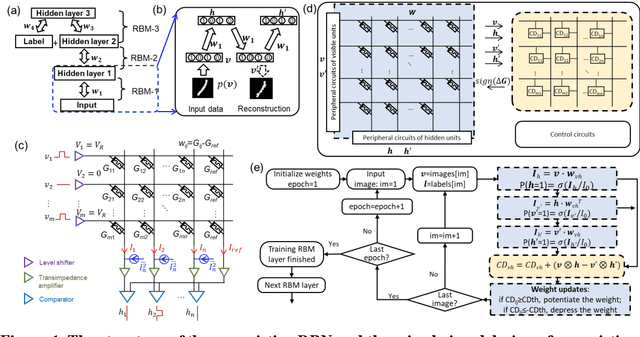
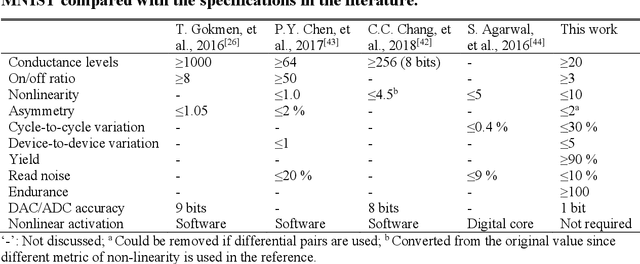
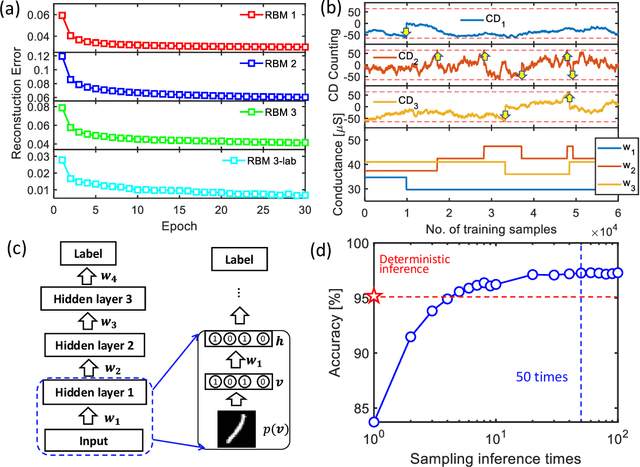
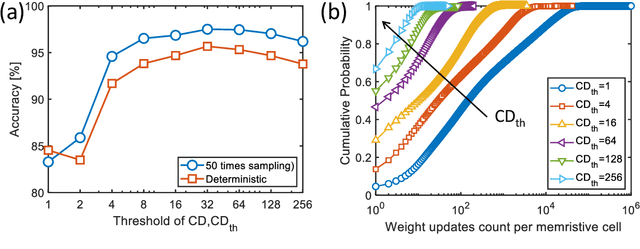
The tunability of conductance states of various emerging non-volatile memristive devices emulates the plasticity of biological synapses, making it promising in the hardware realization of large-scale neuromorphic systems. The inference of the neural network can be greatly accelerated by the vector-matrix multiplication (VMM) performed within a crossbar array of memristive devices in one step. Nevertheless, the implementation of the VMM needs complex peripheral circuits and the complexity further increases since non-idealities of memristive devices prevent precise conductance tuning (especially for the online training) and largely degrade the performance of the deep neural networks (DNNs). Here, we present an efficient online training method of the memristive deep belief net (DBN). The proposed memristive DBN uses stochastically binarized activations, reducing the complexity of peripheral circuits, and uses the contrastive divergence (CD) based gradient descent learning algorithm. The analog VMM and digital CD are performed separately in a mixed-signal hardware arrangement, making the memristive DBN high immune to non-idealities of synaptic devices. The number of write operations on memristive devices is reduced by two orders of magnitude. The recognition accuracy of 95%~97% can be achieved for the MNIST dataset using pulsed synaptic behaviors of various memristive synaptic devices.
MTJ-Based Hardware Synapse Design for Quantized Deep Neural Networks
Dec 29, 2019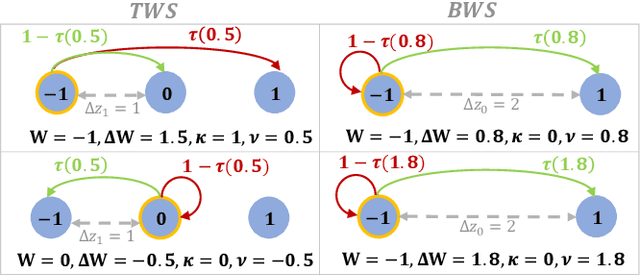

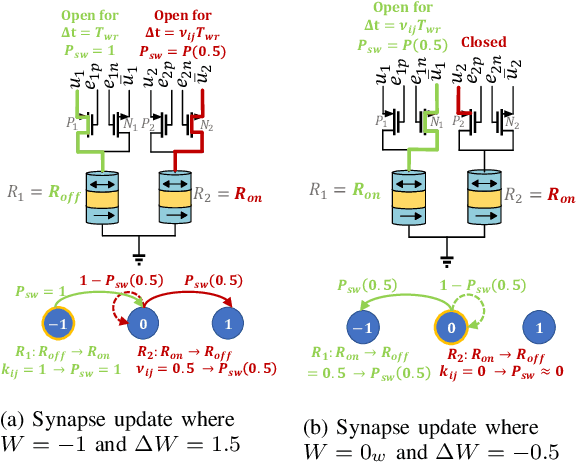
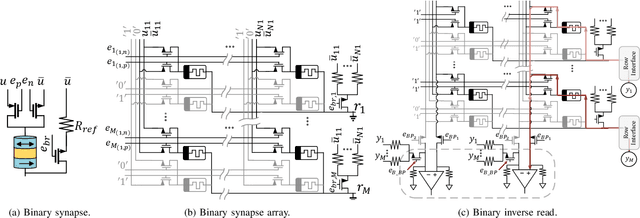
Quantized neural networks (QNNs) are being actively researched as a solution for the computational complexity and memory intensity of deep neural networks. This has sparked efforts to develop algorithms that support both inference and training with quantized weight and activation values without sacrificing accuracy. A recent example is the GXNOR framework for stochastic training of ternary and binary neural networks. In this paper, we introduce a novel hardware synapse circuit that uses magnetic tunnel junction (MTJ) devices to support the GXNOR training. Our solution enables processing near memory (PNM) of QNNs, therefore can further reduce the data movements from and into the memory. We simulated MTJ-based stochastic training of a TNN over the MNIST and SVHN datasets and achieved an accuracy of 98.61% and 93.99%, respectively.
A Systematic Approach to Blocking Convolutional Neural Networks
Jun 14, 2016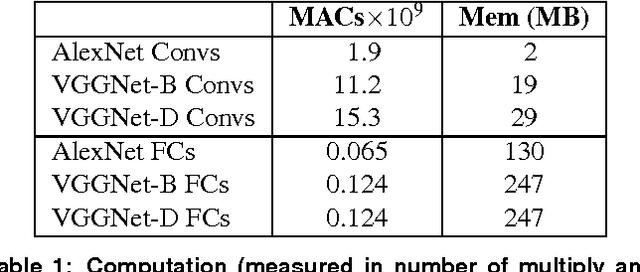
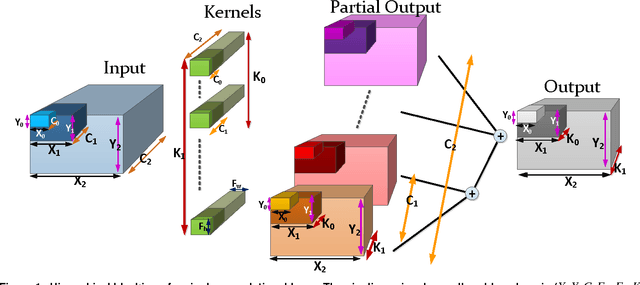
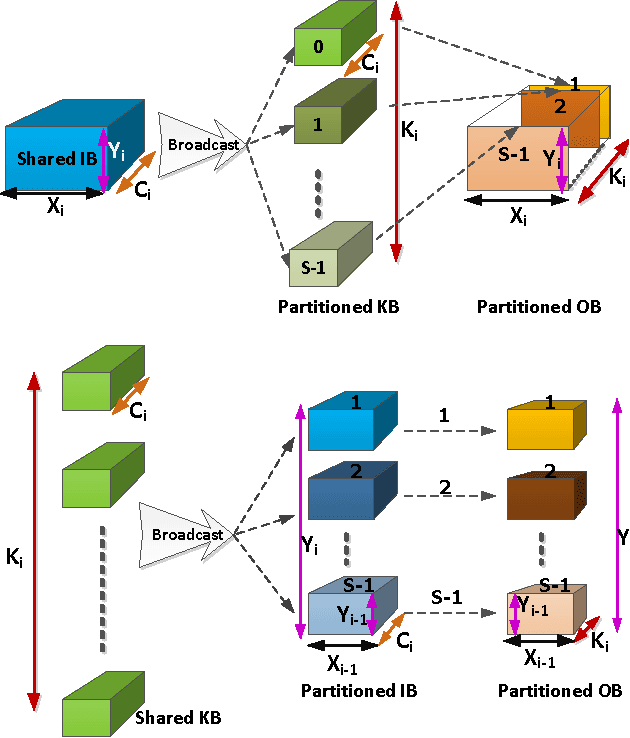

Convolutional Neural Networks (CNNs) are the state of the art solution for many computer vision problems, and many researchers have explored optimized implementations. Most implementations heuristically block the computation to deal with the large data sizes and high data reuse of CNNs. This paper explores how to block CNN computations for memory locality by creating an analytical model for CNN-like loop nests. Using this model we automatically derive optimized blockings for common networks that improve the energy efficiency of custom hardware implementations by up to an order of magnitude. Compared to traditional CNN CPU implementations based on highly-tuned, hand-optimized BLAS libraries,our x86 programs implementing the optimal blocking reduce the number of memory accesses by up to 90%.