 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling and Accelerating Dynamic Vision Transformer Inference for Real-Time Applications
Dec 06, 2022Many state-of-the-art deep learning models for computer vision tasks are based on the transformer architecture. Such models can be computationally expensive and are typically statically set to meet the deployment scenario. However, in real-time applications, the resources available for every inference can vary considerably and be smaller than what state-of-the-art models use. We can use dynamic models to adapt the model execution to meet real-time application resource constraints. While prior dynamic work has primarily minimized resource utilization for less complex input images while maintaining accuracy and focused on CNNs and early transformer models such as BERT, we adapt vision transformers to meet system dynamic resource constraints, independent of the input image. We find that unlike early transformer models, recent state-of-the-art vision transformers heavily rely on convolution layers. We show that pretrained models are fairly resilient to skipping computation in the convolution and self-attention layers, enabling us to create a low-overhead system for dynamic real-time inference without additional training. Finally, we create a optimized accelerator for these dynamic vision transformers in a 5nm technology. The PE array occupies 2.26mm$^2$ and is 17 times faster than a NVIDIA TITAN V GPU for state-of-the-art transformer-based models for semantic segmentation.
Dataset Culling: Towards Efficient Training Of Distillation-Based Domain Specific Models
Feb 10, 2019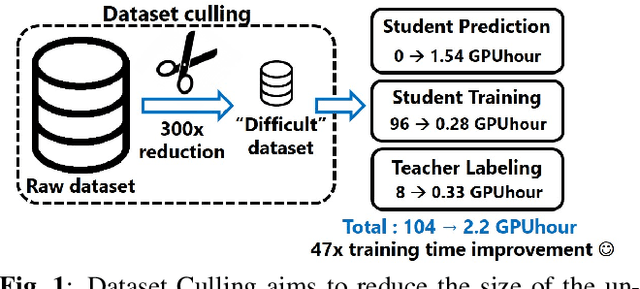
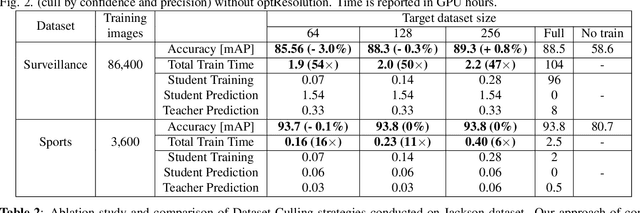
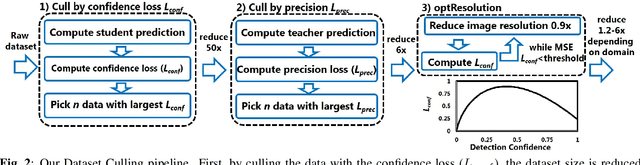
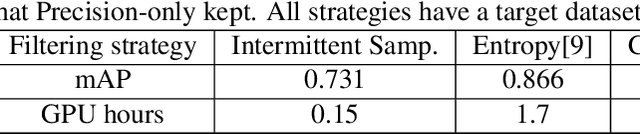
Real-time CNN-based object detection models for applications like surveillance can achieve high accuracy but are computationally expensive. Recent works have shown 10 to 100x reduction in computation cost for inference by using domain-specific networks. However, prior works have focused on inference only. If the domain model requires frequent retraining, training costs can pose a significant bottleneck. To address this, we propose Dataset Culling: a pipeline to reduce the size of the dataset for training, based on the prediction difficulty. Images that are easy to classify are filtered out since they contribute little to improving the accuracy. The difficulty is measured using our proposed confidence loss metric with little computational overhead. Dataset Culling is extended to optimize the image resolution to further improve training and inference costs. We develop fixed-angle, long-duration video datasets across several domains, and we show that Dataset Culling can reduce the training costs by 47x with no accuracy loss or even with slight improvement. Codes are available: https://github.com/kentaroy47/DatasetCulling
Training Domain Specific Models for Energy-Efficient Object Detection
Nov 18, 2018

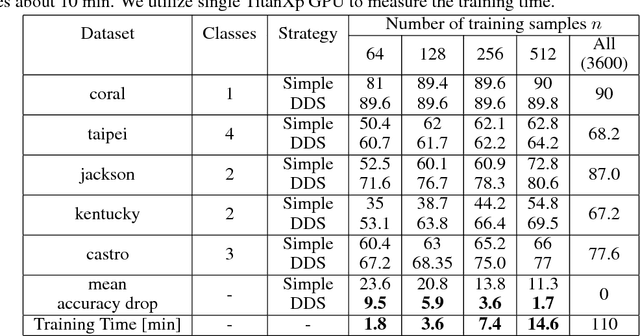

We propose an end-to-end framework for training domain specific models (DSMs) to obtain both high accuracy and computational efficiency for object detection tasks. DSMs are trained with distillation \cite{hinton2015distilling} and focus on achieving high accuracy at a limited domain (e.g. fixed view of an intersection). We argue that DSMs can capture essential features well even with a small model size, enabling higher accuracy and efficiency than traditional techniques. In addition, we improve the training efficiency by reducing the dataset size by culling easy to classify images from the training set. For the limited domain, we observed that compact DSMs significantly surpass the accuracy of COCO trained models of the same size. By training on a compact dataset, we show that with an accuracy drop of only 3.6\%, the training time can be reduced by 93\%. The codes are uploaded in https://github.com/kentaroy47/training-domain-specific-models.
A Systematic Approach to Blocking Convolutional Neural Networks
Jun 14, 2016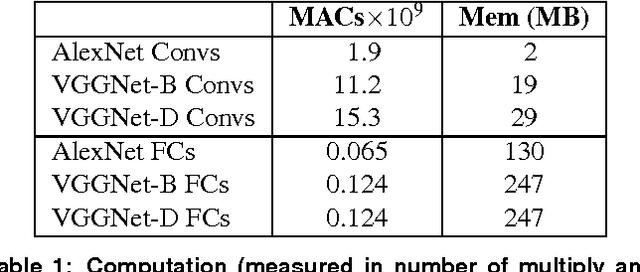
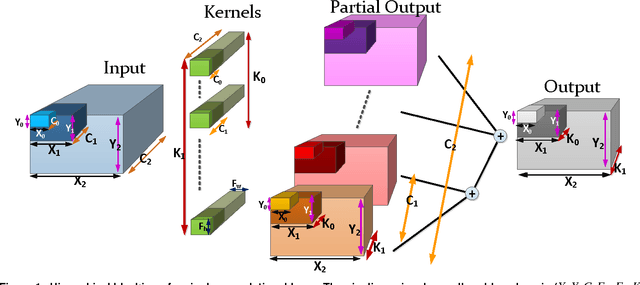
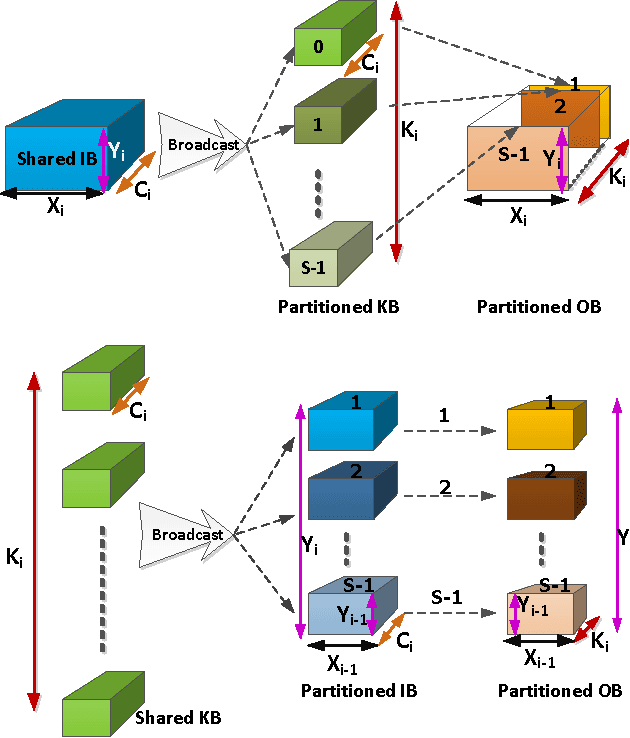

Convolutional Neural Networks (CNNs) are the state of the art solution for many computer vision problems, and many researchers have explored optimized implementations. Most implementations heuristically block the computation to deal with the large data sizes and high data reuse of CNNs. This paper explores how to block CNN computations for memory locality by creating an analytical model for CNN-like loop nests. Using this model we automatically derive optimized blockings for common networks that improve the energy efficiency of custom hardware implementations by up to an order of magnitude. Compared to traditional CNN CPU implementations based on highly-tuned, hand-optimized BLAS libraries,our x86 programs implementing the optimal blocking reduce the number of memory accesses by up to 90%.