 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD4C: Data-free Quantization for Contrastive Language-Image Pre-training Models
Nov 19, 2025Data-Free Quantization (DFQ) offers a practical solution for model compression without requiring access to real data, making it particularly attractive in privacy-sensitive scenarios. While DFQ has shown promise for unimodal models, its extension to Vision-Language Models such as Contrastive Language-Image Pre-training (CLIP) models remains underexplored. In this work, we reveal that directly applying existing DFQ techniques to CLIP results in substantial performance degradation due to two key limitations: insufficient semantic content and low intra-image diversity in synthesized samples. To tackle these challenges, we propose D4C, the first DFQ framework tailored for CLIP. D4C synthesizes semantically rich and structurally diverse pseudo images through three key components: (1) Prompt-Guided Semantic Injection aligns generated images with real-world semantics using text prompts; (2) Structural Contrastive Generation reproduces compositional structures of natural images by leveraging foreground-background contrastive synthesis; and (3) Perturbation-Aware Enhancement applies controlled perturbations to improve sample diversity and robustness. These components jointly empower D4C to synthesize images that are both semantically informative and structurally diverse, effectively bridging the performance gap of DFQ on CLIP. Extensive experiments validate the effectiveness of D4C, showing significant performance improvements on various bit-widths and models. For example, under the W4A8 setting with CLIP ResNet-50 and ViT-B/32, D4C achieves Top-1 accuracy improvement of 12.4% and 18.9% on CIFAR-10, 6.8% and 19.7% on CIFAR-100, and 1.4% and 5.7% on ImageNet-1K in zero-shot classification, respectively.
AHCPTQ: Accurate and Hardware-Compatible Post-Training Quantization for Segment Anything Model
Mar 05, 2025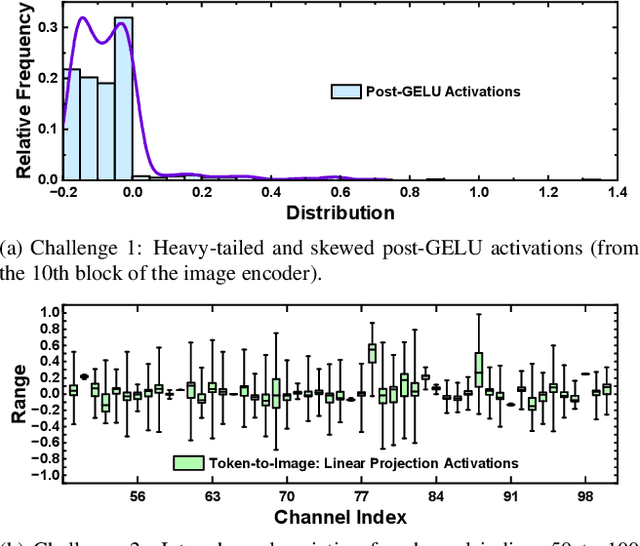



The Segment Anything Model (SAM) has demonstrated strong versatility across various visual tasks. However, its large storage requirements and high computational cost pose challenges for practical deployment. Post-training quantization (PTQ) has emerged as an effective strategy for efficient deployment, but we identify two key challenges in SAM that hinder the effectiveness of existing PTQ methods: the heavy-tailed and skewed distribution of post-GELU activations, and significant inter-channel variation in linear projection activations. To address these challenges, we propose AHCPTQ, an accurate and hardware-efficient PTQ method for SAM. AHCPTQ introduces hardware-compatible Hybrid Log-Uniform Quantization (HLUQ) to manage post-GELU activations, employing log2 quantization for dense small values and uniform quantization for sparse large values to enhance quantization resolution. Additionally, AHCPTQ incorporates Channel-Aware Grouping (CAG) to mitigate inter-channel variation by progressively clustering activation channels with similar distributions, enabling them to share quantization parameters and improving hardware efficiency. The combination of HLUQ and CAG not only enhances quantization effectiveness but also ensures compatibility with efficient hardware execution. For instance, under the W4A4 configuration on the SAM-L model, AHCPTQ achieves 36.6% mAP on instance segmentation with the DINO detector, while achieving a 7.89x speedup and 8.64x energy efficiency over its floating-point counterpart in FPGA implementation.
SLAMSpoof: Practical LiDAR Spoofing Attacks on Localization Systems Guided by Scan Matching Vulnerability Analysis
Feb 19, 2025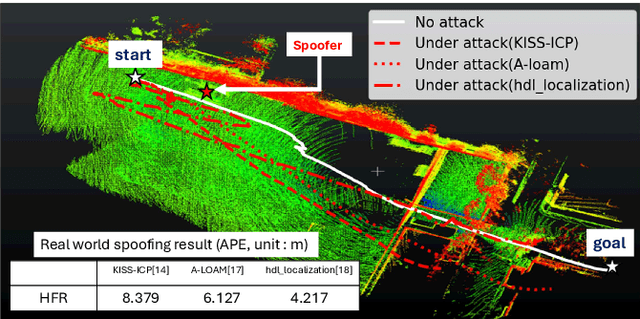

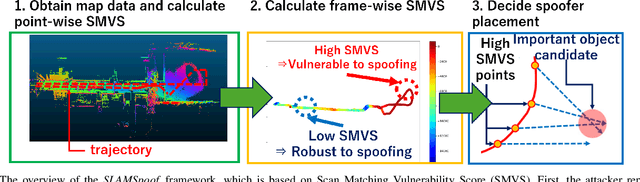
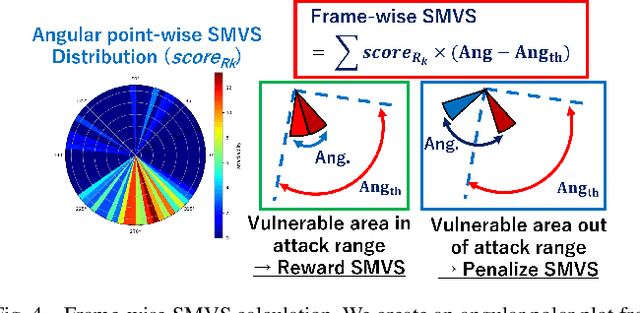
Accurate localization is essential for enabling modern full self-driving services. These services heavily rely on map-based traffic information to reduce uncertainties in recognizing lane shapes, traffic light locations, and traffic signs. Achieving this level of reliance on map information requires centimeter-level localization accuracy, which is currently only achievable with LiDAR sensors. However, LiDAR is known to be vulnerable to spoofing attacks that emit malicious lasers against LiDAR to overwrite its measurements. Once localization is compromised, the attack could lead the victim off roads or make them ignore traffic lights. Motivated by these serious safety implications, we design SLAMSpoof, the first practical LiDAR spoofing attack on localization systems for self-driving to assess the actual attack significance on autonomous vehicles. SLAMSpoof can effectively find the effective attack location based on our scan matching vulnerability score (SMVS), a point-wise metric representing the potential vulnerability to spoofing attacks. To evaluate the effectiveness of the attack, we conduct real-world experiments on ground vehicles and confirm its high capability in real-world scenarios, inducing position errors of $\geq$4.2 meters (more than typical lane width) for all 3 popular LiDAR-based localization algorithms. We finally discuss the potential countermeasures of this attack. Code is available at https://github.com/Keio-CSG/slamspoof
LiSA: Leveraging Link Recommender to Attack Graph Neural Networks via Subgraph Injection
Feb 13, 2025Graph Neural Networks (GNNs) have demonstrated remarkable proficiency in modeling data with graph structures, yet recent research reveals their susceptibility to adversarial attacks. Traditional attack methodologies, which rely on manipulating the original graph or adding links to artificially created nodes, often prove impractical in real-world settings. This paper introduces a novel adversarial scenario involving the injection of an isolated subgraph to deceive both the link recommender and the node classifier within a GNN system. Specifically, the link recommender is mislead to propose links between targeted victim nodes and the subgraph, encouraging users to unintentionally establish connections and that would degrade the node classification accuracy, thereby facilitating a successful attack. To address this, we present the LiSA framework, which employs a dual surrogate model and bi-level optimization to simultaneously meet two adversarial objectives. Extensive experiments on real-world datasets demonstrate the effectiveness of our method.
PACiM: A Sparsity-Centric Hybrid Compute-in-Memory Architecture via Probabilistic Approximation
Aug 29, 2024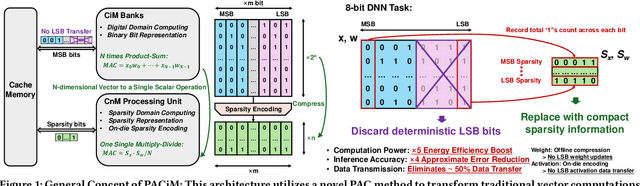
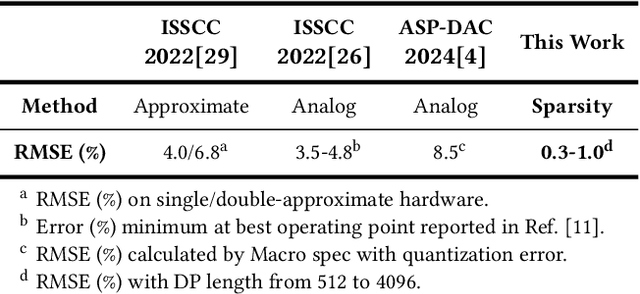
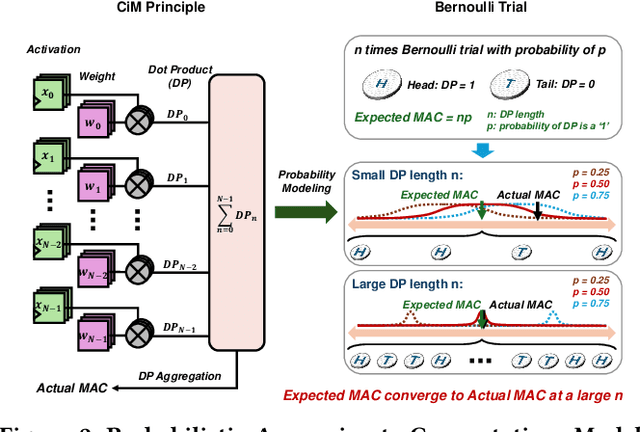
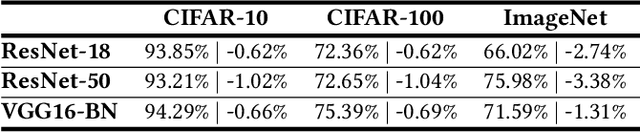
Approximate computing emerges as a promising approach to enhance the efficiency of compute-in-memory (CiM) systems in deep neural network processing. However, traditional approximate techniques often significantly trade off accuracy for power efficiency, and fail to reduce data transfer between main memory and CiM banks, which dominates power consumption. This paper introduces a novel probabilistic approximate computation (PAC) method that leverages statistical techniques to approximate multiply-and-accumulation (MAC) operations, reducing approximation error by 4X compared to existing approaches. PAC enables efficient sparsity-based computation in CiM systems by simplifying complex MAC vector computations into scalar calculations. Moreover, PAC enables sparsity encoding and eliminates the LSB activations transmission, significantly reducing data reads and writes. This sets PAC apart from traditional approximate computing techniques, minimizing not only computation power but also memory accesses by 50%, thereby boosting system-level efficiency. We developed PACiM, a sparsity-centric architecture that fully exploits sparsity to reduce bit-serial cycles by 81% and achieves a peak 8b/8b efficiency of 14.63 TOPS/W in 65 nm CMOS while maintaining high accuracy of 93.85/72.36/66.02% on CIFAR-10/CIFAR-100/ImageNet benchmarks using a ResNet-18 model, demonstrating the effectiveness of our PAC methodology.
Revisiting LiDAR Spoofing Attack Capabilities against Object Detection: Improvements, Measurement, and New Attack
Mar 19, 2023



LiDAR (Light Detection And Ranging) is an indispensable sensor for precise long- and wide-range 3D sensing, which directly benefited the recent rapid deployment of autonomous driving (AD). Meanwhile, such a safety-critical application strongly motivates its security research. A recent line of research demonstrates that one can manipulate the LiDAR point cloud and fool object detection by firing malicious lasers against LiDAR. However, these efforts face 3 critical research gaps: (1) evaluating only on a specific LiDAR (VLP-16); (2) assuming unvalidated attack capabilities; and (3) evaluating with models trained on limited datasets. To fill these critical research gaps, we conduct the first large-scale measurement study on LiDAR spoofing attack capabilities on object detectors with 9 popular LiDARs in total and 3 major types of object detectors. To perform this measurement, we significantly improved the LiDAR spoofing capability with more careful optics and functional electronics, which allows us to be the first to clearly demonstrate and quantify key attack capabilities assumed in prior works. However, we further find that such key assumptions actually can no longer hold for all the other (8 out of 9) LiDARs that are more recent than VLP-16 due to various recent LiDAR features. To this end, we further identify a new type of LiDAR spoofing attack that can improve on this and be applicable to a much more general and recent set of LiDARs. We find that its attack capability is enough to (1) cause end-to-end safety hazards in simulated AD scenarios, and (2) remove real vehicles in the physical world. We also discuss the defense side.
Through the Looking Glass: Diminishing Occlusions in Robot Vision Systems with Mirror Reflections
Aug 31, 2021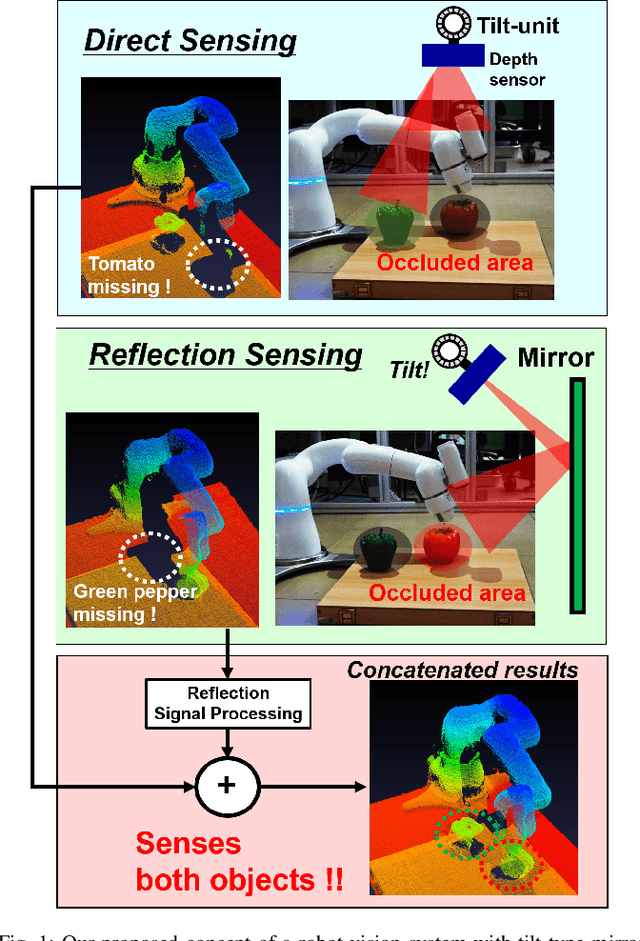
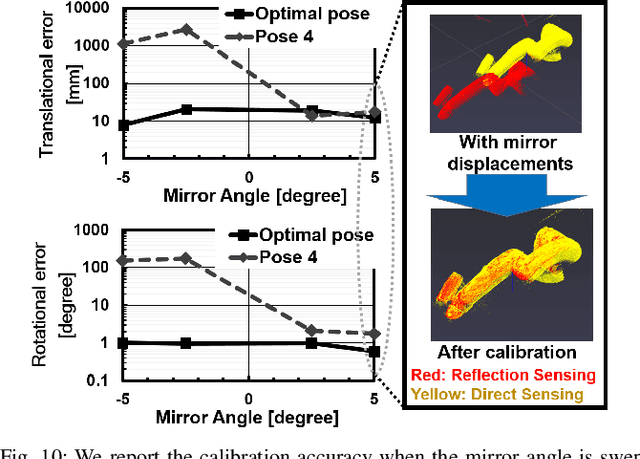
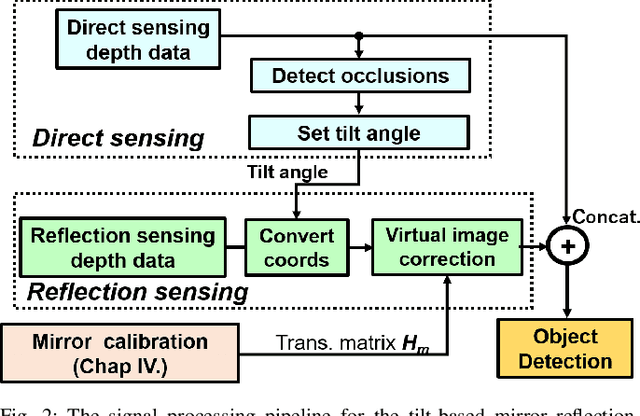
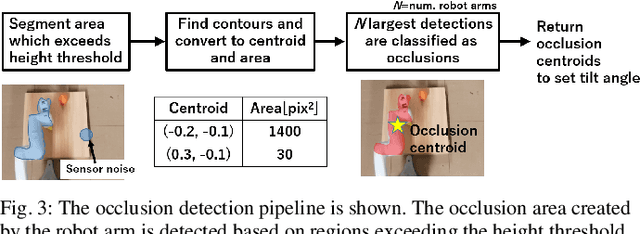
The quality of robot vision greatly affects the performance of automation systems, where occlusions stand as one of the biggest challenges. If the target is occluded from the sensor, detecting and grasping such objects become very challenging. For example, when multiple robot arms cooperate in a single workplace, occlusions will be created under the robot arm itself and hide objects underneath. While occlusions can be greatly reduced by installing multiple sensors, the increase in sensor costs cannot be ignored. Moreover, the sensor placements must be rearranged every time the robot operation routine and layout change. To diminish occlusions, we propose the first robot vision system with tilt-type mirror reflection sensing. By instantly tilting the sensor itself, we obtain two sensing results with different views: conventional direct line-of-sight sensing and non-line-of-sight sensing via mirror reflections. Our proposed system removes occlusions adaptively by detecting the occlusions in the scene and dynamically configuring the sensor tilt angle to sense the detected occluded area. Thus, sensor rearrangements are not required even after changes in robot operation or layout. Since the required hardware is the tilt-unit and a commercially available mirror, the cost increase is marginal. Through experiments, we show that our system can achieve a similar detection accuracy as systems with multiple sensors, regardless of the single-sensor implementation.
Dataset Culling: Towards Efficient Training Of Distillation-Based Domain Specific Models
Feb 10, 2019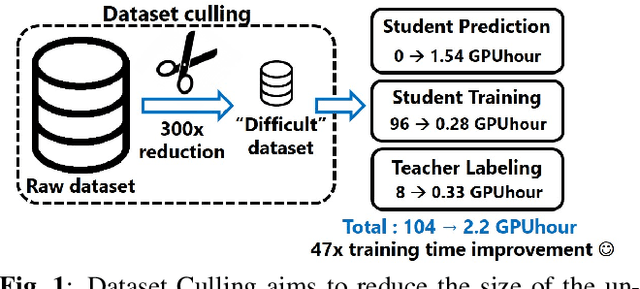
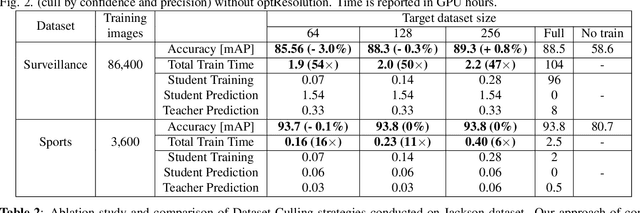
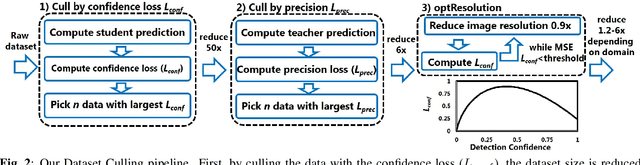
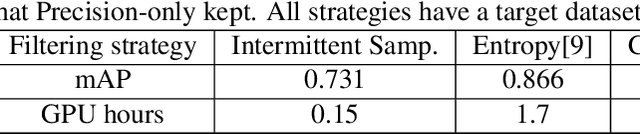
Real-time CNN-based object detection models for applications like surveillance can achieve high accuracy but are computationally expensive. Recent works have shown 10 to 100x reduction in computation cost for inference by using domain-specific networks. However, prior works have focused on inference only. If the domain model requires frequent retraining, training costs can pose a significant bottleneck. To address this, we propose Dataset Culling: a pipeline to reduce the size of the dataset for training, based on the prediction difficulty. Images that are easy to classify are filtered out since they contribute little to improving the accuracy. The difficulty is measured using our proposed confidence loss metric with little computational overhead. Dataset Culling is extended to optimize the image resolution to further improve training and inference costs. We develop fixed-angle, long-duration video datasets across several domains, and we show that Dataset Culling can reduce the training costs by 47x with no accuracy loss or even with slight improvement. Codes are available: https://github.com/kentaroy47/DatasetCulling
Training Domain Specific Models for Energy-Efficient Object Detection
Nov 18, 2018

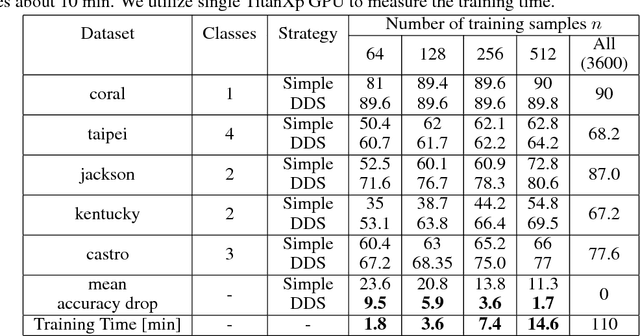

We propose an end-to-end framework for training domain specific models (DSMs) to obtain both high accuracy and computational efficiency for object detection tasks. DSMs are trained with distillation \cite{hinton2015distilling} and focus on achieving high accuracy at a limited domain (e.g. fixed view of an intersection). We argue that DSMs can capture essential features well even with a small model size, enabling higher accuracy and efficiency than traditional techniques. In addition, we improve the training efficiency by reducing the dataset size by culling easy to classify images from the training set. For the limited domain, we observed that compact DSMs significantly surpass the accuracy of COCO trained models of the same size. By training on a compact dataset, we show that with an accuracy drop of only 3.6\%, the training time can be reduced by 93\%. The codes are uploaded in https://github.com/kentaroy47/training-domain-specific-models.