 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurface-based parcellation and vertex-wise analysis of ultra high-resolution ex vivo 7 tesla MRI in neurodegenerative diseases
Mar 28, 2024



Magnetic resonance imaging (MRI) is the standard modality to understand human brain structure and function in vivo (antemortem). Decades of research in human neuroimaging has led to the widespread development of methods and tools to provide automated volume-based segmentations and surface-based parcellations which help localize brain functions to specialized anatomical regions. Recently ex vivo (postmortem) imaging of the brain has opened-up avenues to study brain structure at sub-millimeter ultra high-resolution revealing details not possible to observe with in vivo MRI. Unfortunately, there has been limited methodological development in ex vivo MRI primarily due to lack of datasets and limited centers with such imaging resources. Therefore, in this work, we present one-of-its-kind dataset of 82 ex vivo T2w whole brain hemispheres MRI at 0.3 mm isotropic resolution spanning Alzheimer's disease and related dementias. We adapted and developed a fast and easy-to-use automated surface-based pipeline to parcellate, for the first time, ultra high-resolution ex vivo brain tissue at the native subject space resolution using the Desikan-Killiany-Tourville (DKT) brain atlas. This allows us to perform vertex-wise analysis in the template space and thereby link morphometry measures with pathology measurements derived from histology. We will open-source our dataset docker container, Jupyter notebooks for ready-to-use out-of-the-box set of tools and command line options to advance ex vivo MRI clinical brain imaging research on the project webpage.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
AutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents
Jan 23, 2024Foundation models that incorporate language, vision, and more recently actions have revolutionized the ability to harness internet scale data to reason about useful tasks. However, one of the key challenges of training embodied foundation models is the lack of data grounded in the physical world. In this paper, we propose AutoRT, a system that leverages existing foundation models to scale up the deployment of operational robots in completely unseen scenarios with minimal human supervision. AutoRT leverages vision-language models (VLMs) for scene understanding and grounding, and further uses large language models (LLMs) for proposing diverse and novel instructions to be performed by a fleet of robots. Guiding data collection by tapping into the knowledge of foundation models enables AutoRT to effectively reason about autonomy tradeoffs and safety while significantly scaling up data collection for robot learning. We demonstrate AutoRT proposing instructions to over 20 robots across multiple buildings and collecting 77k real robot episodes via both teleoperation and autonomous robot policies. We experimentally show that such "in-the-wild" data collected by AutoRT is significantly more diverse, and that AutoRT's use of LLMs allows for instruction following data collection robots that can align to human preferences.
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023
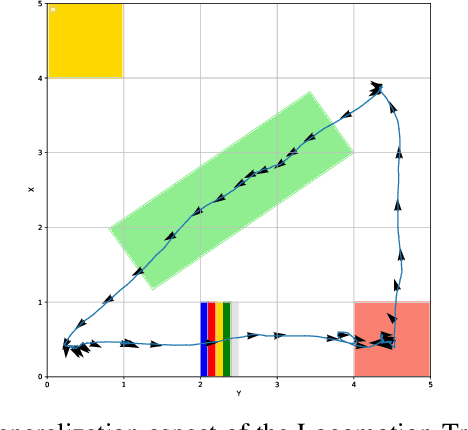
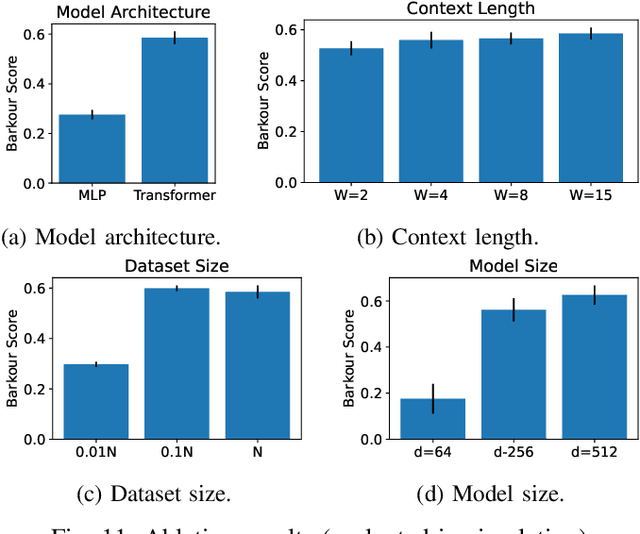

Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Learning Model Predictive Controllers with Real-Time Attention for Real-World Navigation
Sep 24, 2022
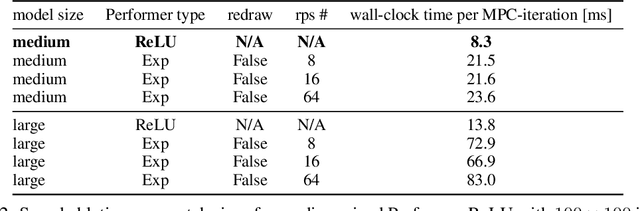


Despite decades of research, existing navigation systems still face real-world challenges when deployed in the wild, e.g., in cluttered home environments or in human-occupied public spaces. To address this, we present a new class of implicit control policies combining the benefits of imitation learning with the robust handling of system constraints from Model Predictive Control (MPC). Our approach, called Performer-MPC, uses a learned cost function parameterized by vision context embeddings provided by Performers -- a low-rank implicit-attention Transformer. We jointly train the cost function and construct the controller relying on it, effectively solving end-to-end the corresponding bi-level optimization problem. We show that the resulting policy improves standard MPC performance by leveraging a few expert demonstrations of the desired navigation behavior in different challenging real-world scenarios. Compared with a standard MPC policy, Performer-MPC achieves >40% better goal reached in cluttered environments and >65% better on social metrics when navigating around humans.
Gesture2Path: Imitation Learning for Gesture-aware Navigation
Sep 19, 2022

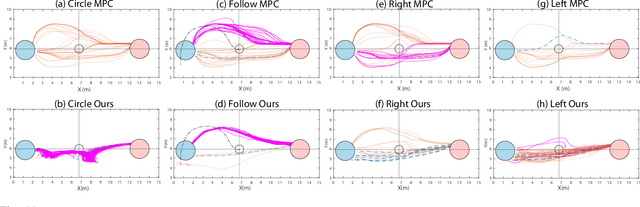

As robots increasingly enter human-centered environments, they must not only be able to navigate safely around humans, but also adhere to complex social norms. Humans often rely on non-verbal communication through gestures and facial expressions when navigating around other people, especially in densely occupied spaces. Consequently, robots also need to be able to interpret gestures as part of solving social navigation tasks. To this end, we present Gesture2Path, a novel social navigation approach that combines image-based imitation learning with model-predictive control. Gestures are interpreted based on a neural network that operates on streams of images, while we use a state-of-the-art model predictive control algorithm to solve point-to-point navigation tasks. We deploy our method on real robots and showcase the effectiveness of our approach for the four gestures-navigation scenarios: left/right, follow me, and make a circle. Our experiments indicate that our method is able to successfully interpret complex human gestures and to use them as a signal to generate socially compliant trajectories for navigation tasks. We validated our method based on in-situ ratings of participants interacting with the robots.
A Protocol for Validating Social Navigation Policies
Apr 11, 2022
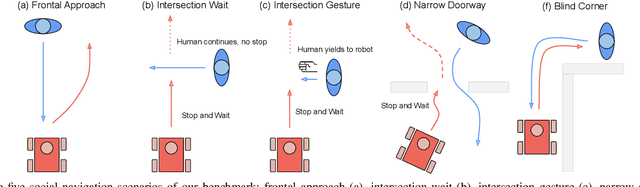
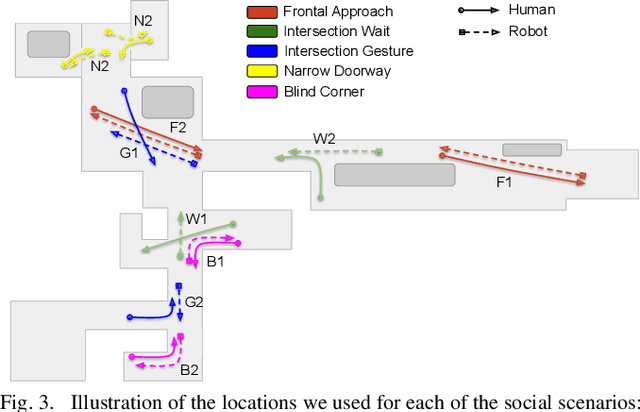

Enabling socially acceptable behavior for situated agents is a major goal of recent robotics research. Robots should not only operate safely around humans, but also abide by complex social norms. A key challenge for developing socially-compliant policies is measuring the quality of their behavior. Social behavior is enormously complex, making it difficult to create reliable metrics to gauge the performance of algorithms. In this paper, we propose a protocol for social navigation benchmarking that defines a set of canonical social navigation scenarios and an in-situ metric for evaluating performance on these scenarios using questionnaires. Our experiments show this protocol is realistic, scalable, and repeatable across runs and physical spaces. Our protocol can be replicated verbatim or it can be used to define a social navigation benchmark for novel scenarios. Our goal is to introduce a protocol for benchmarking social scenarios that is homogeneous and comparable.
Blind source separation of baseband RF communication signals using mixed-signal matrix multiplication circuit
Feb 06, 2022An 8 x 8 mixed-signal matrix multiplier architecture based on 64 hybrid capacitor-resistor multiplying digital to analogue converters implemented in a 65 nm CMOS technology was developed for the application of blind source separation of baseband RF signals. The integrated circuit has 13-bit resolution for each matrix weight and achieves a measured dynamic range of > 62 dB with a bandwidth of > 15 MHz and typical power dissipation of < 30 mW per matrix row. Separation of single-tone signal is measured to be better than 57 dBc.
Gray Matter Segmentation in Ultra High Resolution 7 Tesla ex vivo T2w MRI of Human Brain Hemispheres
Oct 14, 2021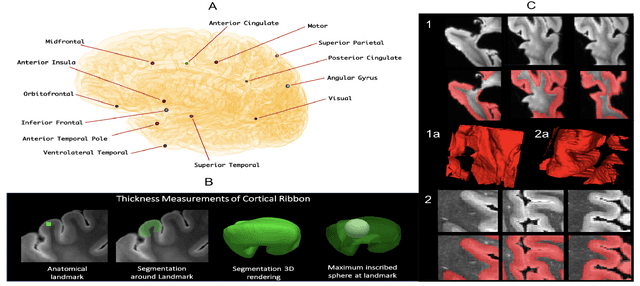
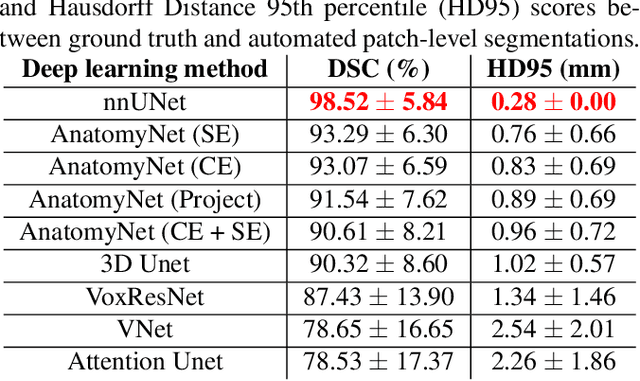
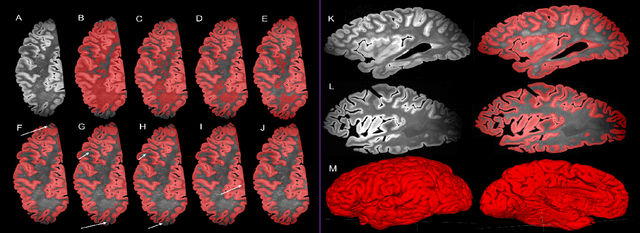
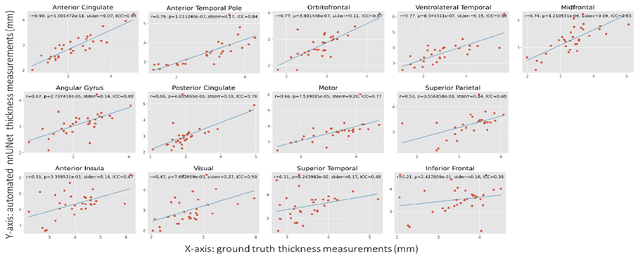
Ex vivo MRI of the brain provides remarkable advantages over in vivo MRI for visualizing and characterizing detailed neuroanatomy. However, automated cortical segmentation methods in ex vivo MRI are not well developed, primarily due to limited availability of labeled datasets, and heterogeneity in scanner hardware and acquisition protocols. In this work, we present a high resolution 7 Tesla dataset of 32 ex vivo human brain specimens. We benchmark the cortical mantle segmentation performance of nine neural network architectures, trained and evaluated using manually-segmented 3D patches sampled from specific cortical regions, and show excellent generalizing capabilities across whole brain hemispheres in different specimens, and also on unseen images acquired at different magnetic field strength and imaging sequences. Finally, we provide cortical thickness measurements across key regions in 3D ex vivo human brain images. Our code and processed datasets are publicly available at https://github.com/Pulkit-Khandelwal/picsl-ex-vivo-segmentation.
Learning Branching Heuristics for Propositional Model Counting
Jul 07, 2020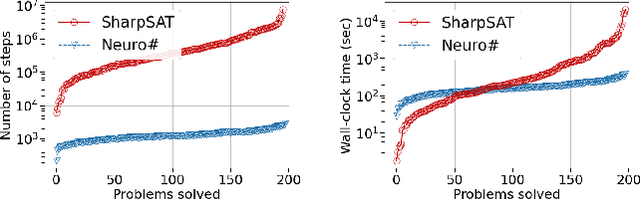
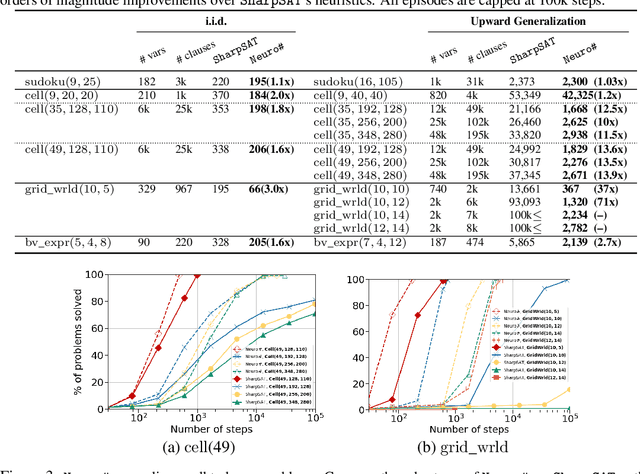
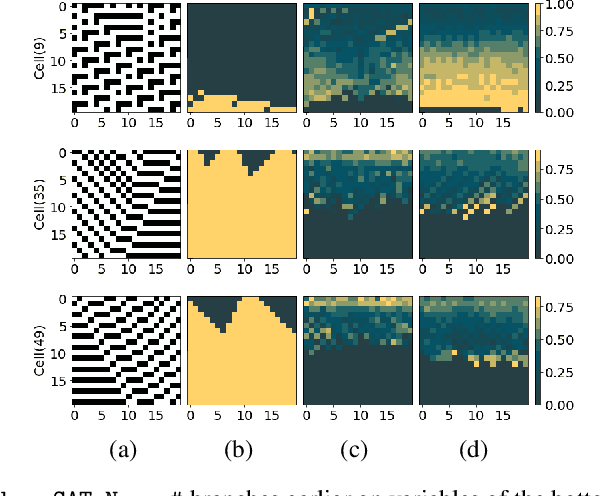
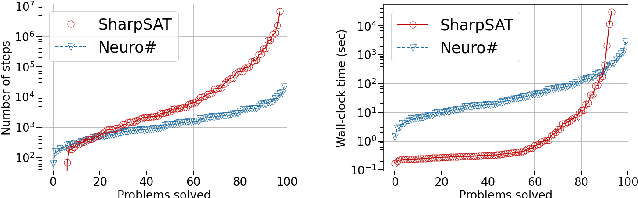
Propositional model counting or #SAT is the problem of computing the number of satisfying assignments of a Boolean formula and many discrete probabilistic inference problems can be translated into a model counting problem to be solved by #SAT solvers. Generic ``exact'' #SAT solvers, however, are often not scalable to industrial-level instances. In this paper, we present Neuro#, an approach for learning branching heuristics for exact #SAT solvers via evolution strategies (ES) to reduce the number of branching steps the solver takes to solve an instance. We experimentally show that our approach not only reduces the step count on similarly distributed held-out instances but it also generalizes to much larger instances from the same problem family. The gap between the learned and the vanilla solver on larger instances is sometimes so wide that the learned solver can even overcome the run time overhead of querying the model and beat the vanilla in wall-clock time by orders of magnitude.