 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents
Jan 23, 2024Foundation models that incorporate language, vision, and more recently actions have revolutionized the ability to harness internet scale data to reason about useful tasks. However, one of the key challenges of training embodied foundation models is the lack of data grounded in the physical world. In this paper, we propose AutoRT, a system that leverages existing foundation models to scale up the deployment of operational robots in completely unseen scenarios with minimal human supervision. AutoRT leverages vision-language models (VLMs) for scene understanding and grounding, and further uses large language models (LLMs) for proposing diverse and novel instructions to be performed by a fleet of robots. Guiding data collection by tapping into the knowledge of foundation models enables AutoRT to effectively reason about autonomy tradeoffs and safety while significantly scaling up data collection for robot learning. We demonstrate AutoRT proposing instructions to over 20 robots across multiple buildings and collecting 77k real robot episodes via both teleoperation and autonomous robot policies. We experimentally show that such "in-the-wild" data collected by AutoRT is significantly more diverse, and that AutoRT's use of LLMs allows for instruction following data collection robots that can align to human preferences.
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Jul 28, 2023We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. Our goal is to enable a single end-to-end trained model to both learn to map robot observations to actions and enjoy the benefits of large-scale pretraining on language and vision-language data from the web. To this end, we propose to co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering. In contrast to other approaches, we propose a simple, general recipe to achieve this goal: in order to fit both natural language responses and robotic actions into the same format, we express the actions as text tokens and incorporate them directly into the training set of the model in the same way as natural language tokens. We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).
Language to Rewards for Robotic Skill Synthesis
Jun 16, 2023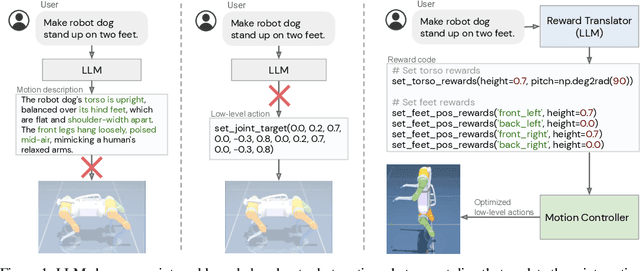
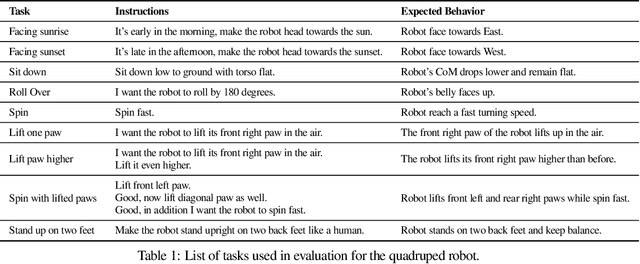

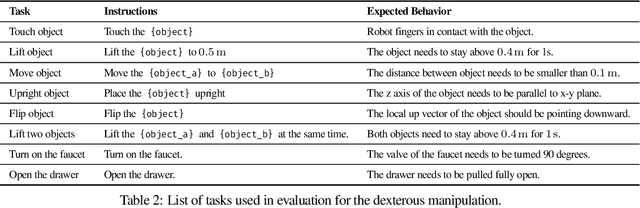
Large language models (LLMs) have demonstrated exciting progress in acquiring diverse new capabilities through in-context learning, ranging from logical reasoning to code-writing. Robotics researchers have also explored using LLMs to advance the capabilities of robotic control. However, since low-level robot actions are hardware-dependent and underrepresented in LLM training corpora, existing efforts in applying LLMs to robotics have largely treated LLMs as semantic planners or relied on human-engineered control primitives to interface with the robot. On the other hand, reward functions are shown to be flexible representations that can be optimized for control policies to achieve diverse tasks, while their semantic richness makes them suitable to be specified by LLMs. In this work, we introduce a new paradigm that harnesses this realization by utilizing LLMs to define reward parameters that can be optimized and accomplish variety of robotic tasks. Using reward as the intermediate interface generated by LLMs, we can effectively bridge the gap between high-level language instructions or corrections to low-level robot actions. Meanwhile, combining this with a real-time optimizer, MuJoCo MPC, empowers an interactive behavior creation experience where users can immediately observe the results and provide feedback to the system. To systematically evaluate the performance of our proposed method, we designed a total of 17 tasks for a simulated quadruped robot and a dexterous manipulator robot. We demonstrate that our proposed method reliably tackles 90% of the designed tasks, while a baseline using primitive skills as the interface with Code-as-policies achieves 50% of the tasks. We further validated our method on a real robot arm where complex manipulation skills such as non-prehensile pushing emerge through our interactive system.
Personalized Speech recognition on mobile devices
Mar 11, 2016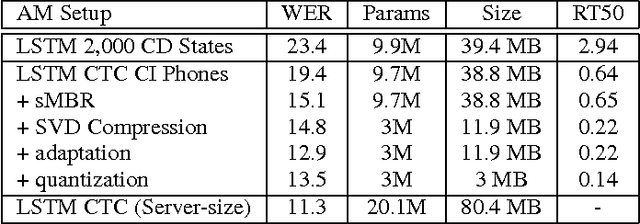
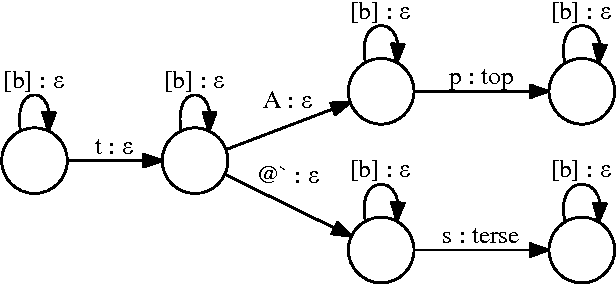

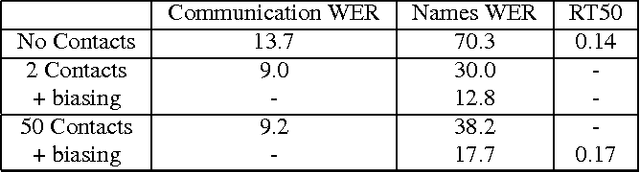
We describe a large vocabulary speech recognition system that is accurate, has low latency, and yet has a small enough memory and computational footprint to run faster than real-time on a Nexus 5 Android smartphone. We employ a quantized Long Short-Term Memory (LSTM) acoustic model trained with connectionist temporal classification (CTC) to directly predict phoneme targets, and further reduce its memory footprint using an SVD-based compression scheme. Additionally, we minimize our memory footprint by using a single language model for both dictation and voice command domains, constructed using Bayesian interpolation. Finally, in order to properly handle device-specific information, such as proper names and other context-dependent information, we inject vocabulary items into the decoder graph and bias the language model on-the-fly. Our system achieves 13.5% word error rate on an open-ended dictation task, running with a median speed that is seven times faster than real-time.