 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Object Detection for 3-D Point Clouds
May 04, 2020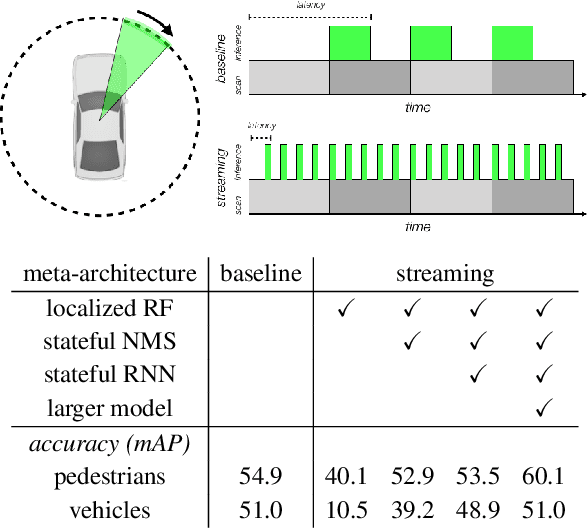
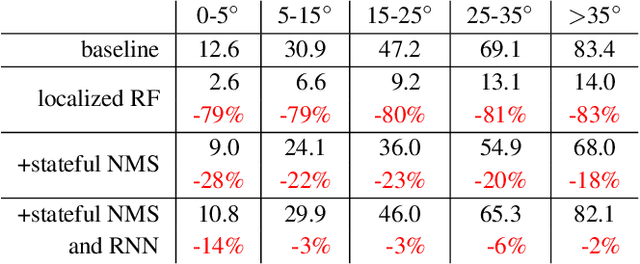
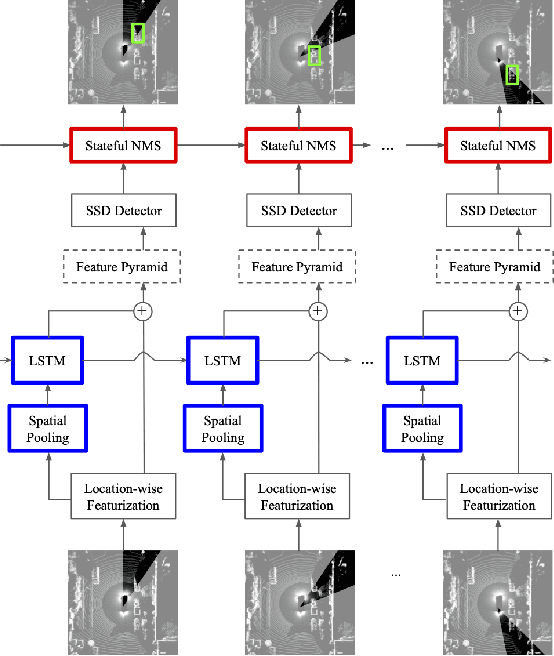
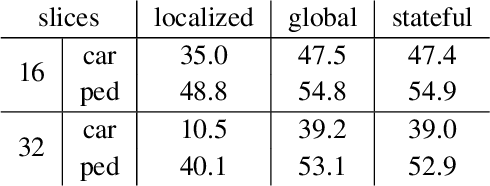
Autonomous vehicles operate in a dynamic environment, where the speed with which a vehicle can perceive and react impacts the safety and efficacy of the system. LiDAR provides a prominent sensory modality that informs many existing perceptual systems including object detection, segmentation, motion estimation, and action recognition. The latency for perceptual systems based on point cloud data can be dominated by the amount of time for a complete rotational scan (e.g. 100 ms). This built-in data capture latency is artificial, and based on treating the point cloud as a camera image in order to leverage camera-inspired architectures. However, unlike camera sensors, most LiDAR point cloud data is natively a streaming data source in which laser reflections are sequentially recorded based on the precession of the laser beam. In this work, we explore how to build an object detector that removes this artificial latency constraint, and instead operates on native streaming data in order to significantly reduce latency. This approach has the added benefit of reducing the peak computational burden on inference hardware by spreading the computation over the acquisition time for a scan. We demonstrate a family of streaming detection systems based on sequential modeling through a series of modifications to the traditional detection meta-architecture. We highlight how this model may achieve competitive if not superior predictive performance with state-of-the-art, traditional non-streaming detection systems while achieving significant latency gains (e.g. 1/15'th - 1/3'rd of peak latency). Our results show that operating on LiDAR data in its native streaming formulation offers several advantages for self driving object detection -- advantages that we hope will be useful for any LiDAR perception system where minimizing latency is critical for safe and efficient operation.
StarNet: Targeted Computation for Object Detection in Point Clouds
Aug 29, 2019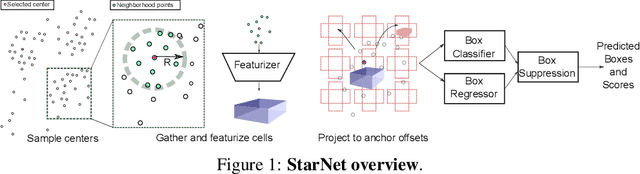
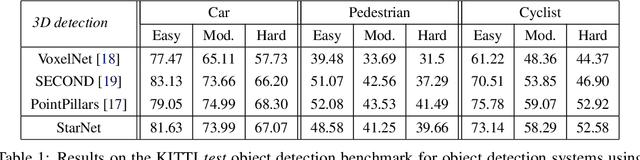
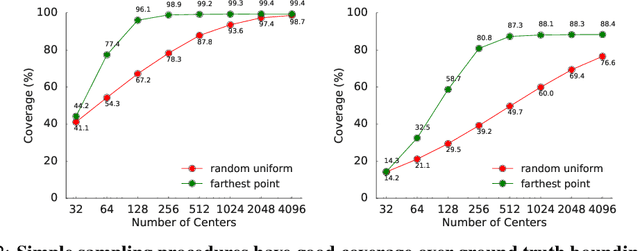
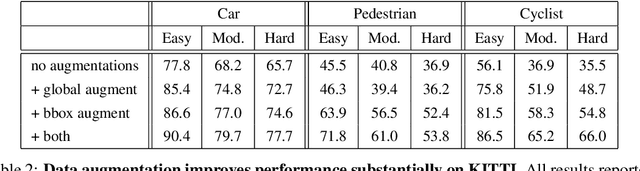
LiDAR sensor systems provide high resolution spatial information about the environment for self-driving cars. Therefore, detecting objects from point clouds derived from LiDAR represents a critical problem. Previous work on object detection from LiDAR has emphasized re-purposing convolutional approaches from traditional camera imagery. In this work, we present an object detection system designed specifically for point cloud data blending aspects of one-stage and two-stage systems. We observe that objects in point clouds are quite distinct from traditional camera images: objects are sparse and vary widely in location, but do not exhibit scale distortions observed in single camera perspective. These two observations suggest that simple and cheap data-driven object proposals to maximize spatial coverage or match the observed densities of point cloud data may suffice. This recognition paired with a local, non-convolutional, point-based network permits building an object detector for point clouds that may be trained only once, but adapted to different computational settings -- targeted to different predictive priorities or spatial regions. We demonstrate this flexibility and the targeted detection strategies on both the KITTI detection dataset as well as on the large-scale Waymo Open Dataset. Furthermore, we find that a single network is competitive with other point cloud detectors across a range of computational budgets, while being more flexible to adapt to contextual priorities.
On the Compression of Recurrent Neural Networks with an Application to LVCSR acoustic modeling for Embedded Speech Recognition
May 02, 2016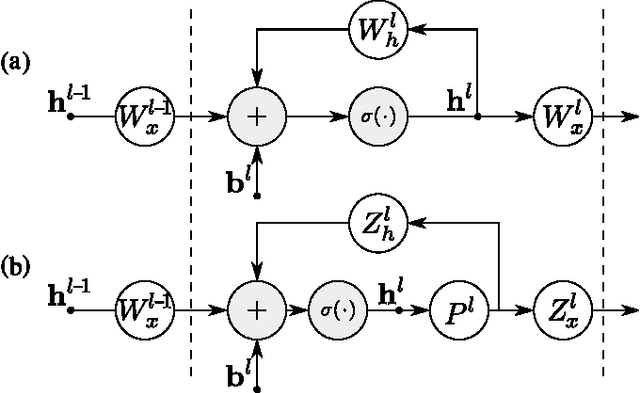
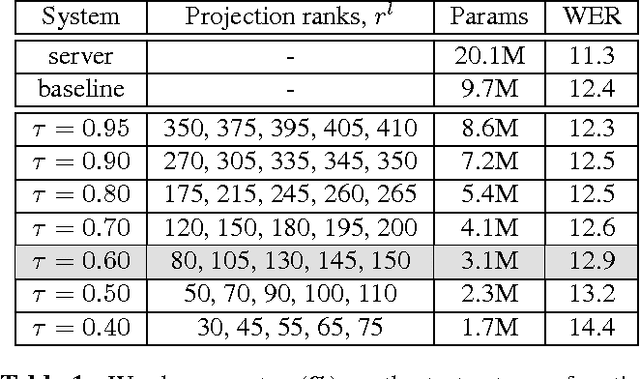
We study the problem of compressing recurrent neural networks (RNNs). In particular, we focus on the compression of RNN acoustic models, which are motivated by the goal of building compact and accurate speech recognition systems which can be run efficiently on mobile devices. In this work, we present a technique for general recurrent model compression that jointly compresses both recurrent and non-recurrent inter-layer weight matrices. We find that the proposed technique allows us to reduce the size of our Long Short-Term Memory (LSTM) acoustic model to a third of its original size with negligible loss in accuracy.
Personalized Speech recognition on mobile devices
Mar 11, 2016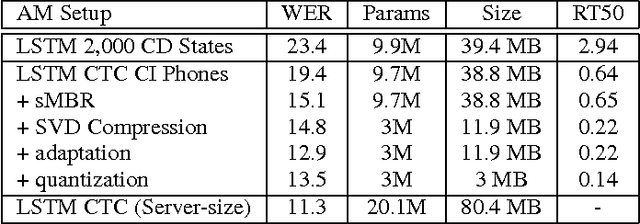

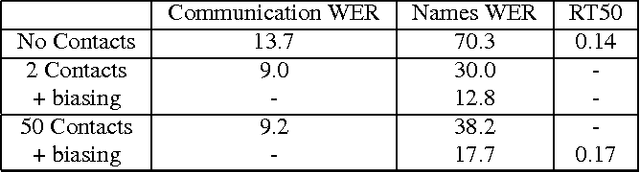
We describe a large vocabulary speech recognition system that is accurate, has low latency, and yet has a small enough memory and computational footprint to run faster than real-time on a Nexus 5 Android smartphone. We employ a quantized Long Short-Term Memory (LSTM) acoustic model trained with connectionist temporal classification (CTC) to directly predict phoneme targets, and further reduce its memory footprint using an SVD-based compression scheme. Additionally, we minimize our memory footprint by using a single language model for both dictation and voice command domains, constructed using Bayesian interpolation. Finally, in order to properly handle device-specific information, such as proper names and other context-dependent information, we inject vocabulary items into the decoder graph and bias the language model on-the-fly. Our system achieves 13.5% word error rate on an open-ended dictation task, running with a median speed that is seven times faster than real-time.
Learning with Pseudo-Ensembles
Dec 16, 2014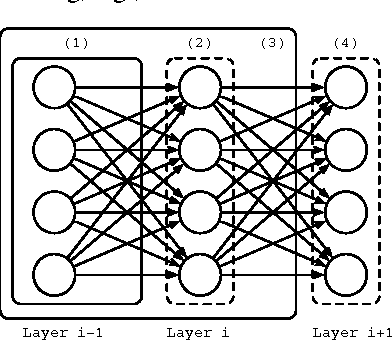

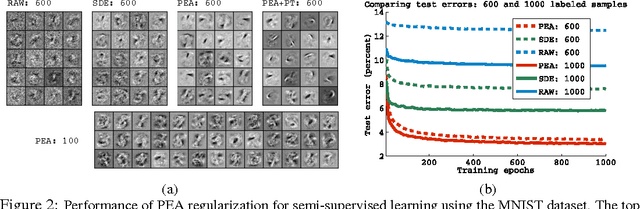

We formalize the notion of a pseudo-ensemble, a (possibly infinite) collection of child models spawned from a parent model by perturbing it according to some noise process. E.g., dropout (Hinton et. al, 2012) in a deep neural network trains a pseudo-ensemble of child subnetworks generated by randomly masking nodes in the parent network. We present a novel regularizer based on making the behavior of a pseudo-ensemble robust with respect to the noise process generating it. In the fully-supervised setting, our regularizer matches the performance of dropout. But, unlike dropout, our regularizer naturally extends to the semi-supervised setting, where it produces state-of-the-art results. We provide a case study in which we transform the Recursive Neural Tensor Network of (Socher et. al, 2013) into a pseudo-ensemble, which significantly improves its performance on a real-world sentiment analysis benchmark.
Representation as a Service
Jul 09, 2014
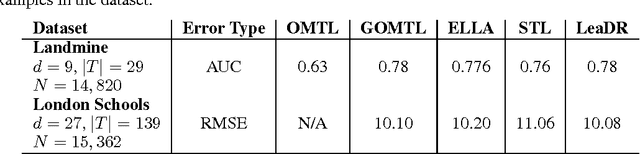
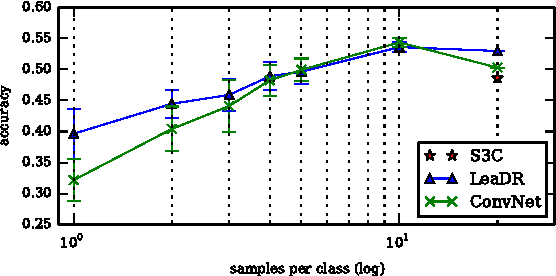

Consider a Machine Learning Service Provider (MLSP) designed to rapidly create highly accurate learners for a never-ending stream of new tasks. The challenge is to produce task-specific learners that can be trained from few labeled samples, even if tasks are not uniquely identified, and the number of tasks and input dimensionality are large. In this paper, we argue that the MLSP should exploit knowledge from previous tasks to build a good representation of the environment it is in, and more precisely, that useful representations for such a service are ones that minimize generalization error for a new hypothesis trained on a new task. We formalize this intuition with a novel method that minimizes an empirical proxy of the intra-task small-sample generalization error. We present several empirical results showing state-of-the art performance on single-task transfer, multitask learning, and the full lifelong learning problem.
End-to-End Text Recognition with Hybrid HMM Maxout Models
Oct 07, 2013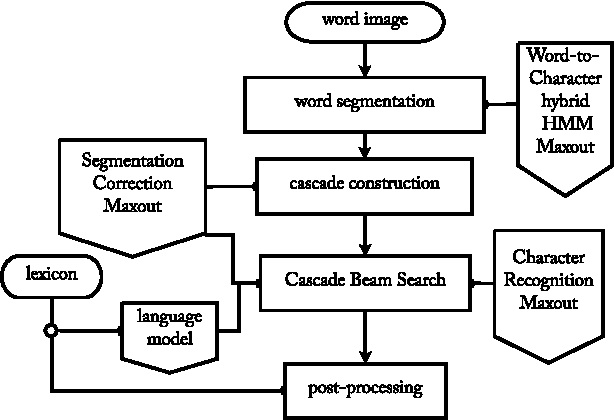
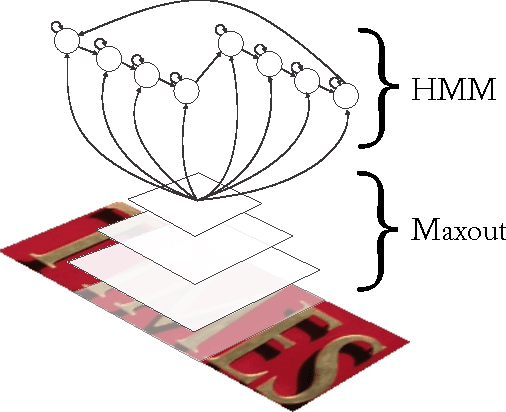
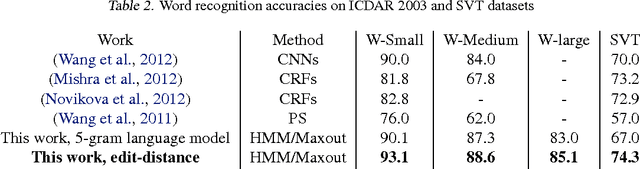

The problem of detecting and recognizing text in natural scenes has proved to be more challenging than its counterpart in documents, with most of the previous work focusing on a single part of the problem. In this work, we propose new solutions to the character and word recognition problems and then show how to combine these solutions in an end-to-end text-recognition system. We do so by leveraging the recently introduced Maxout networks along with hybrid HMM models that have proven useful for voice recognition. Using these elements, we build a tunable and highly accurate recognition system that beats state-of-the-art results on all the sub-problems for both the ICDAR 2003 and SVT benchmark datasets.