 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation as a Service
Paper and Code
Jul 09, 2014
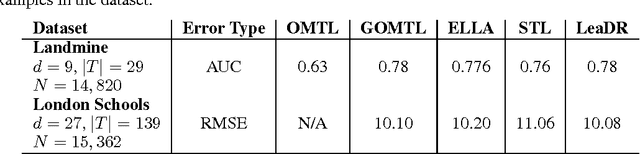
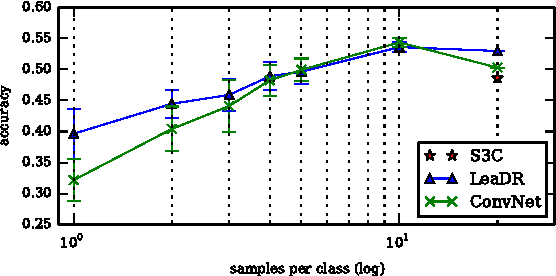

Consider a Machine Learning Service Provider (MLSP) designed to rapidly create highly accurate learners for a never-ending stream of new tasks. The challenge is to produce task-specific learners that can be trained from few labeled samples, even if tasks are not uniquely identified, and the number of tasks and input dimensionality are large. In this paper, we argue that the MLSP should exploit knowledge from previous tasks to build a good representation of the environment it is in, and more precisely, that useful representations for such a service are ones that minimize generalization error for a new hypothesis trained on a new task. We formalize this intuition with a novel method that minimizes an empirical proxy of the intra-task small-sample generalization error. We present several empirical results showing state-of-the art performance on single-task transfer, multitask learning, and the full lifelong learning problem.