 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual Composition through Improved Semantic Guidance
Dec 19, 2024



Visual imagery does not consist of solitary objects, but instead reflects the composition of a multitude of fluid concepts. While there have been great advances in visual representation learning, such advances have focused on building better representations for a small number of discrete objects bereft of an understanding of how these objects are interacting. One can observe this limitation in representations learned through captions or contrastive learning -- where the learned model treats an image essentially as a bag of words. Several works have attempted to address this limitation through the development of bespoke learned architectures to directly address the shortcomings in compositional learning. In this work, we focus on simple, and scalable approaches. In particular, we demonstrate that by substantially improving weakly labeled data, i.e. captions, we can vastly improve the performance of standard contrastive learning approaches. Previous CLIP models achieved near chance rate on challenging tasks probing compositional learning. However, our simple approach boosts performance of CLIP substantially and surpasses all bespoke architectures. Furthermore, we showcase our results on a relatively new captioning benchmark derived from DOCCI. We demonstrate through a series of ablations that a standard CLIP model trained with enhanced data may demonstrate impressive performance on image retrieval tasks.
Towards flexible perception with visual memory
Aug 15, 2024



Training a neural network is a monolithic endeavor, akin to carving knowledge into stone: once the process is completed, editing the knowledge in a network is nearly impossible, since all information is distributed across the network's weights. We here explore a simple, compelling alternative by marrying the representational power of deep neural networks with the flexibility of a database. Decomposing the task of image classification into image similarity (from a pre-trained embedding) and search (via fast nearest neighbor retrieval from a knowledge database), we build a simple and flexible visual memory that has the following key capabilities: (1.) The ability to flexibly add data across scales: from individual samples all the way to entire classes and billion-scale data; (2.) The ability to remove data through unlearning and memory pruning; (3.) An interpretable decision-mechanism on which we can intervene to control its behavior. Taken together, these capabilities comprehensively demonstrate the benefits of an explicit visual memory. We hope that it might contribute to a conversation on how knowledge should be represented in deep vision models -- beyond carving it in ``stone'' weights.
StarNet: Targeted Computation for Object Detection in Point Clouds
Aug 29, 2019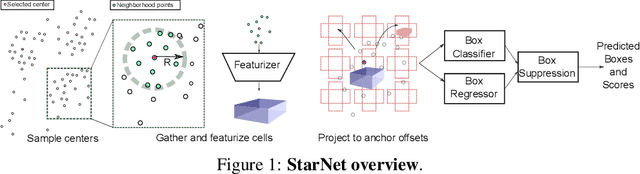
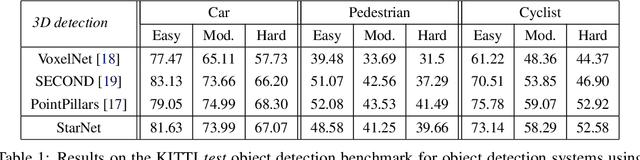
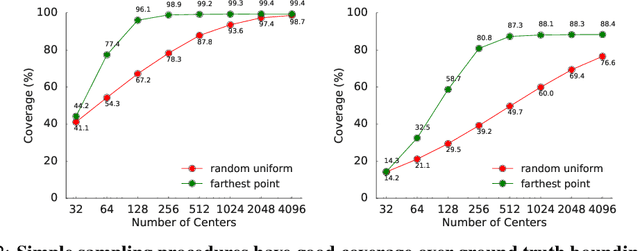
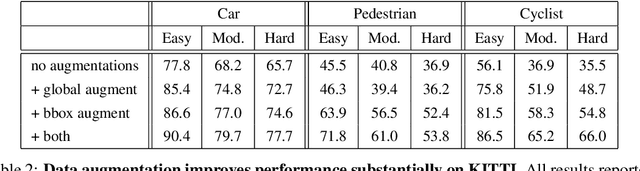
LiDAR sensor systems provide high resolution spatial information about the environment for self-driving cars. Therefore, detecting objects from point clouds derived from LiDAR represents a critical problem. Previous work on object detection from LiDAR has emphasized re-purposing convolutional approaches from traditional camera imagery. In this work, we present an object detection system designed specifically for point cloud data blending aspects of one-stage and two-stage systems. We observe that objects in point clouds are quite distinct from traditional camera images: objects are sparse and vary widely in location, but do not exhibit scale distortions observed in single camera perspective. These two observations suggest that simple and cheap data-driven object proposals to maximize spatial coverage or match the observed densities of point cloud data may suffice. This recognition paired with a local, non-convolutional, point-based network permits building an object detector for point clouds that may be trained only once, but adapted to different computational settings -- targeted to different predictive priorities or spatial regions. We demonstrate this flexibility and the targeted detection strategies on both the KITTI detection dataset as well as on the large-scale Waymo Open Dataset. Furthermore, we find that a single network is competitive with other point cloud detectors across a range of computational budgets, while being more flexible to adapt to contextual priorities.