 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes
Apr 20, 2023
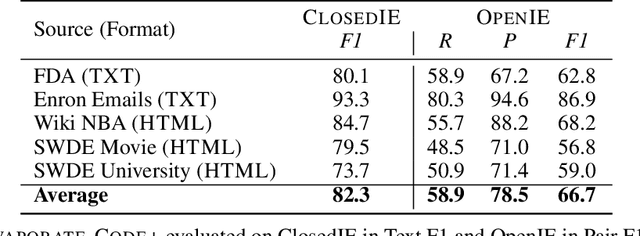

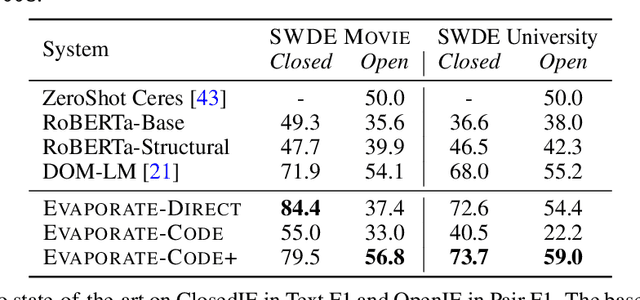
A long standing goal of the data management community is to develop general, automated systems that ingest semi-structured documents and output queryable tables without human effort or domain specific customization. Given the sheer variety of potential documents, state-of-the art systems make simplifying assumptions and use domain specific training. In this work, we ask whether we can maintain generality by using large language models (LLMs). LLMs, which are pretrained on broad data, can perform diverse downstream tasks simply conditioned on natural language task descriptions. We propose and evaluate EVAPORATE, a simple, prototype system powered by LLMs. We identify two fundamentally different strategies for implementing this system: prompt the LLM to directly extract values from documents or prompt the LLM to synthesize code that performs the extraction. Our evaluations show a cost-quality tradeoff between these two approaches. Code synthesis is cheap, but far less accurate than directly processing each document with the LLM. To improve quality while maintaining low cost, we propose an extended code synthesis implementation, EVAPORATE-CODE+, which achieves better quality than direct extraction. Our key insight is to generate many candidate functions and ensemble their extractions using weak supervision. EVAPORATE-CODE+ not only outperforms the state-of-the art systems, but does so using a sublinear pass over the documents with the LLM. This equates to a 110x reduction in the number of tokens the LLM needs to process, averaged across 16 real-world evaluation settings of 10k documents each.
Streaming Object Detection for 3-D Point Clouds
May 04, 2020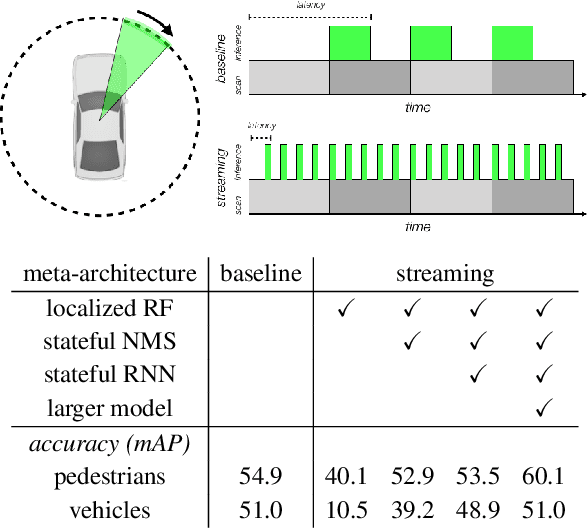
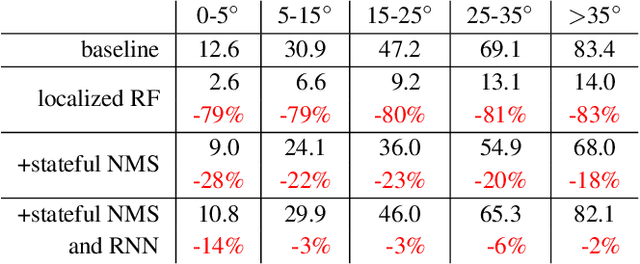
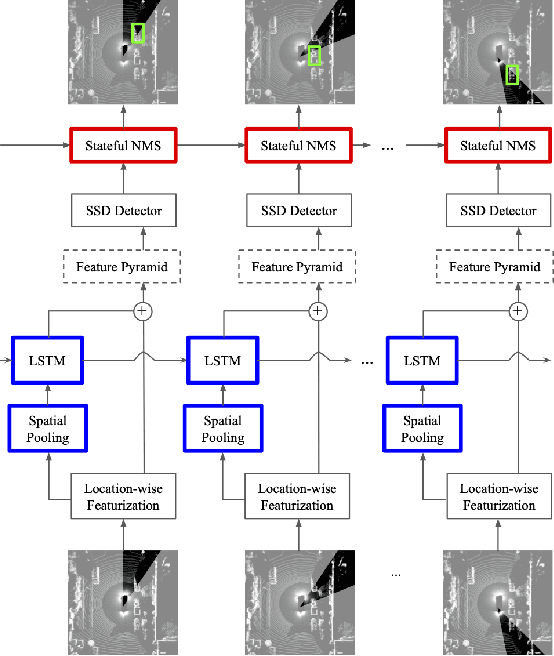
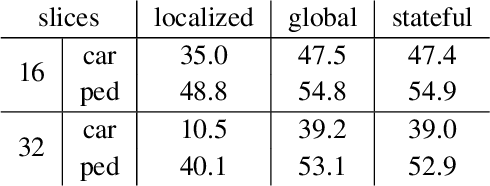
Autonomous vehicles operate in a dynamic environment, where the speed with which a vehicle can perceive and react impacts the safety and efficacy of the system. LiDAR provides a prominent sensory modality that informs many existing perceptual systems including object detection, segmentation, motion estimation, and action recognition. The latency for perceptual systems based on point cloud data can be dominated by the amount of time for a complete rotational scan (e.g. 100 ms). This built-in data capture latency is artificial, and based on treating the point cloud as a camera image in order to leverage camera-inspired architectures. However, unlike camera sensors, most LiDAR point cloud data is natively a streaming data source in which laser reflections are sequentially recorded based on the precession of the laser beam. In this work, we explore how to build an object detector that removes this artificial latency constraint, and instead operates on native streaming data in order to significantly reduce latency. This approach has the added benefit of reducing the peak computational burden on inference hardware by spreading the computation over the acquisition time for a scan. We demonstrate a family of streaming detection systems based on sequential modeling through a series of modifications to the traditional detection meta-architecture. We highlight how this model may achieve competitive if not superior predictive performance with state-of-the-art, traditional non-streaming detection systems while achieving significant latency gains (e.g. 1/15'th - 1/3'rd of peak latency). Our results show that operating on LiDAR data in its native streaming formulation offers several advantages for self driving object detection -- advantages that we hope will be useful for any LiDAR perception system where minimizing latency is critical for safe and efficient operation.
StarNet: Targeted Computation for Object Detection in Point Clouds
Aug 29, 2019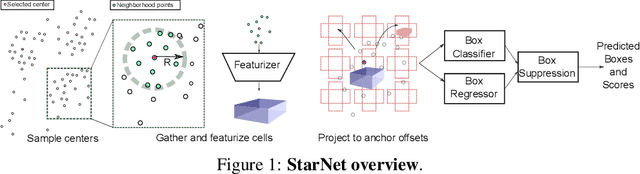
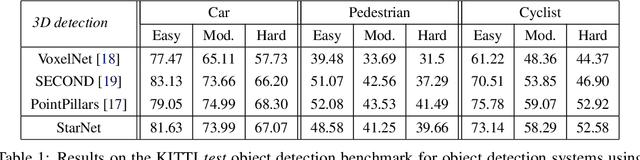
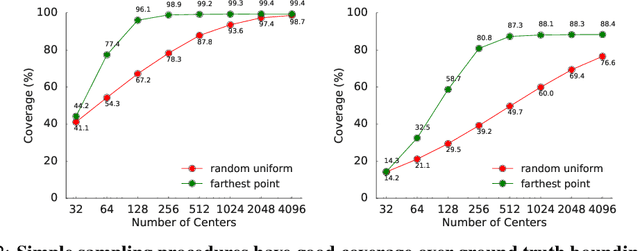
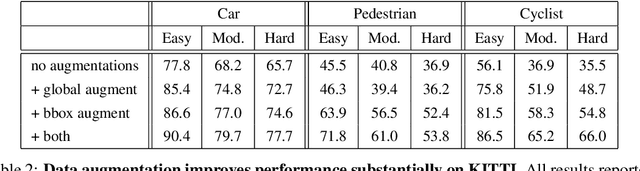
LiDAR sensor systems provide high resolution spatial information about the environment for self-driving cars. Therefore, detecting objects from point clouds derived from LiDAR represents a critical problem. Previous work on object detection from LiDAR has emphasized re-purposing convolutional approaches from traditional camera imagery. In this work, we present an object detection system designed specifically for point cloud data blending aspects of one-stage and two-stage systems. We observe that objects in point clouds are quite distinct from traditional camera images: objects are sparse and vary widely in location, but do not exhibit scale distortions observed in single camera perspective. These two observations suggest that simple and cheap data-driven object proposals to maximize spatial coverage or match the observed densities of point cloud data may suffice. This recognition paired with a local, non-convolutional, point-based network permits building an object detector for point clouds that may be trained only once, but adapted to different computational settings -- targeted to different predictive priorities or spatial regions. We demonstrate this flexibility and the targeted detection strategies on both the KITTI detection dataset as well as on the large-scale Waymo Open Dataset. Furthermore, we find that a single network is competitive with other point cloud detectors across a range of computational budgets, while being more flexible to adapt to contextual priorities.
Using Videos to Evaluate Image Model Robustness
Apr 24, 2019
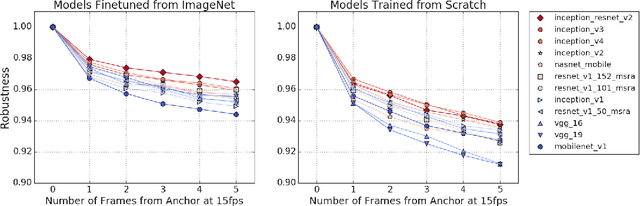
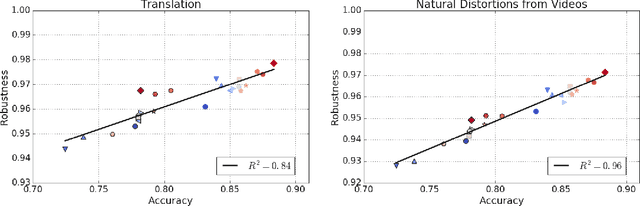
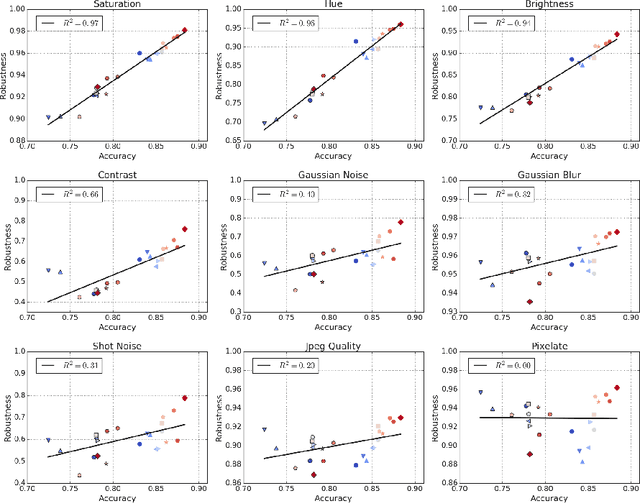
Human visual systems are robust to a wide range of image transformations that are challenging for artificial networks. We present the first study of image model robustness to the minute transformations found across video frames, which we term "natural robustness". Compared to previous studies on adversarial examples and synthetic distortions, natural robustness captures a more diverse set of common image transformations that occur in the natural environment. Our study across a dozen model architectures shows that more accurate models are more robust to natural transformations, and that robustness to synthetic color distortions is a good proxy for natural robustness. In examining brittleness in videos, we find that majority of the brittleness found in videos lies outside the typical definition of adversarial examples (99.9\%). Finally, we investigate training techniques to reduce brittleness and find that no single technique systematically improves natural robustness across twelve tested architectures.
Soft Conditional Computation
Apr 10, 2019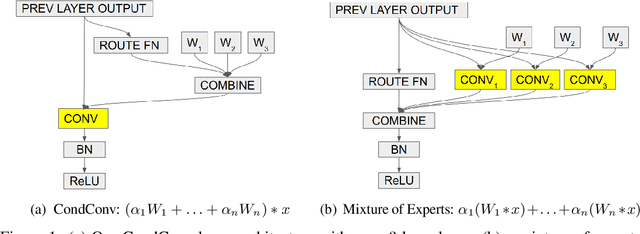
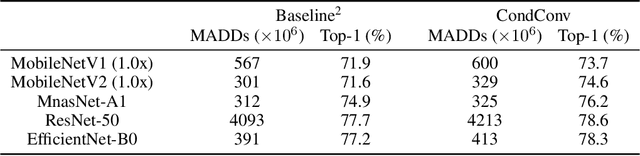
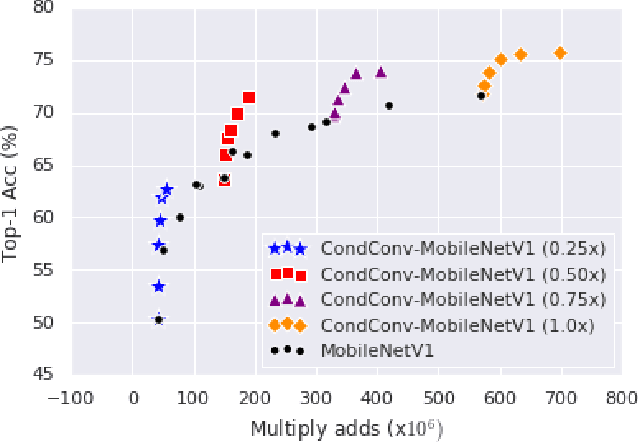

Conditional computation aims to increase the size and accuracy of a network, at a small increase in inference cost. Previous hard-routing models explicitly route the input to a subset of experts. We propose soft conditional computation, which, in contrast, utilizes all experts while still permitting efficient inference through parameter routing. Concretely, for a given convolutional layer, we wish to compute a linear combination of $n$ experts $\alpha_1 \cdot (W_1 * x) + \ldots + \alpha_n \cdot (W_n * x)$, where $\alpha_1, \ldots, \alpha_n$ are functions of the input learned through gradient descent. A straightforward evaluation requires $n$ convolutions. We propose an equivalent form of the above computation, $(\alpha_1 W_1 + \ldots + \alpha_n W_n) * x$, which requires only a single convolution. We demonstrate the efficacy of our method, named CondConv, by scaling up the MobileNetV1, MobileNetV2, and ResNet-50 model architectures to achieve higher accuracy while retaining efficient inference. On the ImageNet classification dataset, CondConv improves the top-1 validation accuracy of the MobileNetV1(0.5x) model from 63.8% to 71.6% while only increasing inference cost by 27%. On COCO object detection, CondConv improves the minival mAP of a MobileNetV1(1.0x) SSD model from 20.3 to 22.4 with just a 4% increase in inference cost.
Sample-Efficient Deep RL with Generative Adversarial Tree Search
Jun 15, 2018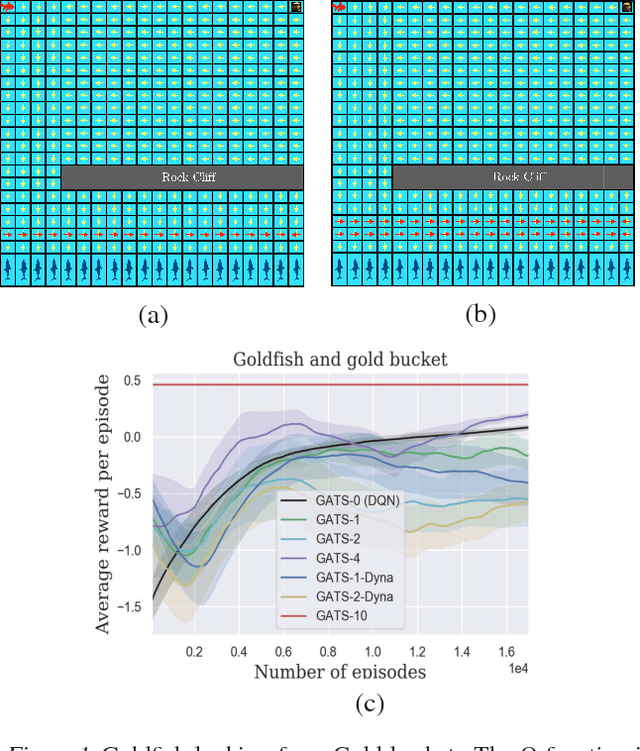



We propose Generative Adversarial Tree Search (GATS), a sample-efficient Deep Reinforcement Learning (DRL) algorithm. While Monte Carlo Tree Search (MCTS) is known to be effective for search and planning in RL, it is often sample-inefficient and therefore expensive to apply in practice. In this work, we develop a Generative Adversarial Network (GAN) architecture to model an environment's dynamics and a predictor model for the reward function. We exploit collected data from interaction with the environment to learn these models, which we then use for model-based planning. During planning, we deploy a finite depth MCTS, using the learned model for tree search and a learned Q-value for the leaves, to find the best action. We theoretically show that GATS improves the bias-variance trade-off in value-based DRL. Moreover, we show that the generative model learns the model dynamics using orders of magnitude fewer samples than the Q-learner. In non-stationary settings where the environment model changes, we find the generative model adapts significantly faster than the Q-learner to the new environment.
MURA: Large Dataset for Abnormality Detection in Musculoskeletal Radiographs
May 22, 2018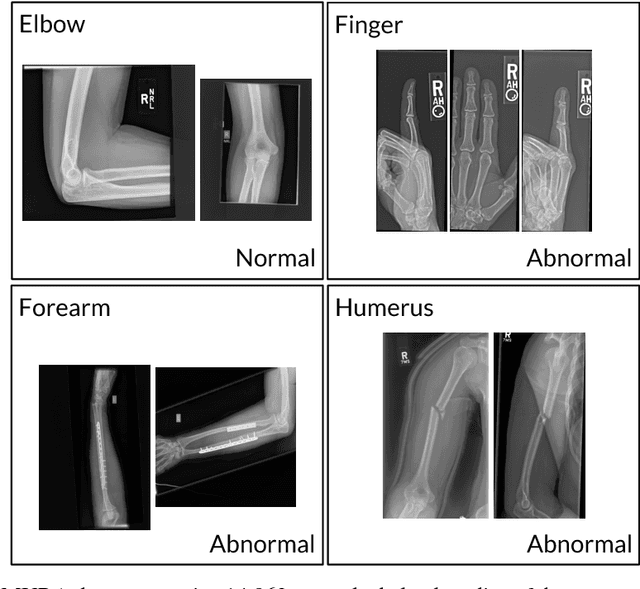
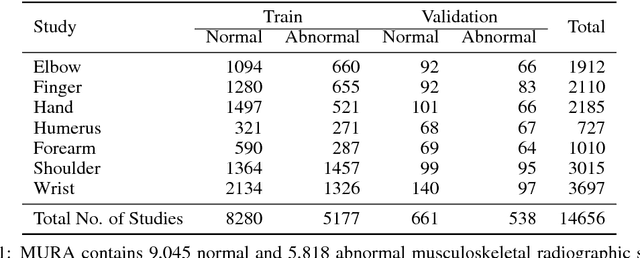

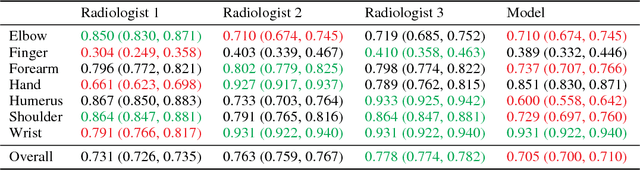
We introduce MURA, a large dataset of musculoskeletal radiographs containing 40,561 images from 14,863 studies, where each study is manually labeled by radiologists as either normal or abnormal. To evaluate models robustly and to get an estimate of radiologist performance, we collect additional labels from six board-certified Stanford radiologists on the test set, consisting of 207 musculoskeletal studies. On this test set, the majority vote of a group of three radiologists serves as gold standard. We train a 169-layer DenseNet baseline model to detect and localize abnormalities. Our model achieves an AUROC of 0.929, with an operating point of 0.815 sensitivity and 0.887 specificity. We compare our model and radiologists on the Cohen's kappa statistic, which expresses the agreement of our model and of each radiologist with the gold standard. Model performance is comparable to the best radiologist performance in detecting abnormalities on finger and wrist studies. However, model performance is lower than best radiologist performance in detecting abnormalities on elbow, forearm, hand, humerus, and shoulder studies. We believe that the task is a good challenge for future research. To encourage advances, we have made our dataset freely available at https://stanfordmlgroup.github.io/competitions/mura .
CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning
Dec 25, 2017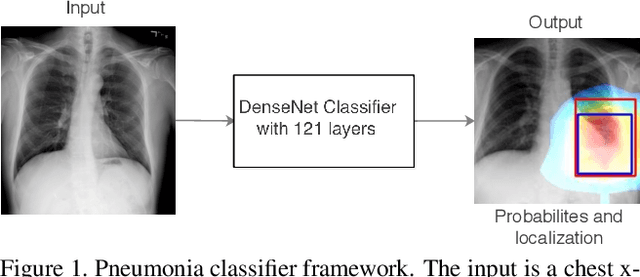

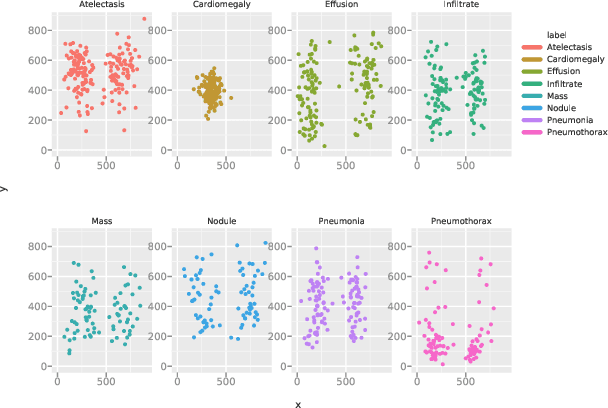
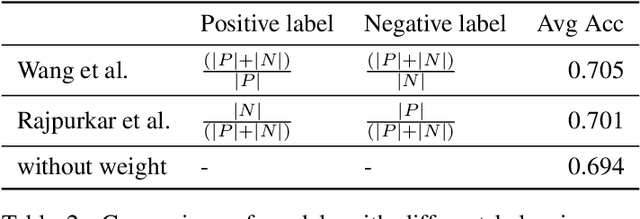
We develop an algorithm that can detect pneumonia from chest X-rays at a level exceeding practicing radiologists. Our algorithm, CheXNet, is a 121-layer convolutional neural network trained on ChestX-ray14, currently the largest publicly available chest X-ray dataset, containing over 100,000 frontal-view X-ray images with 14 diseases. Four practicing academic radiologists annotate a test set, on which we compare the performance of CheXNet to that of radiologists. We find that CheXNet exceeds average radiologist performance on the F1 metric. We extend CheXNet to detect all 14 diseases in ChestX-ray14 and achieve state of the art results on all 14 diseases.