 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jun 22, 2022


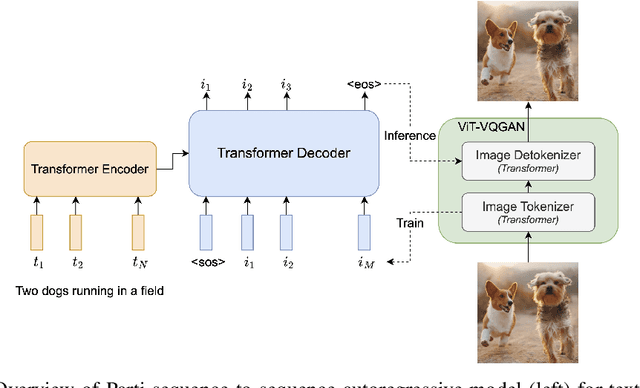
We present the Pathways Autoregressive Text-to-Image (Parti) model, which generates high-fidelity photorealistic images and supports content-rich synthesis involving complex compositions and world knowledge. Parti treats text-to-image generation as a sequence-to-sequence modeling problem, akin to machine translation, with sequences of image tokens as the target outputs rather than text tokens in another language. This strategy can naturally tap into the rich body of prior work on large language models, which have seen continued advances in capabilities and performance through scaling data and model sizes. Our approach is simple: First, Parti uses a Transformer-based image tokenizer, ViT-VQGAN, to encode images as sequences of discrete tokens. Second, we achieve consistent quality improvements by scaling the encoder-decoder Transformer model up to 20B parameters, with a new state-of-the-art zero-shot FID score of 7.23 and finetuned FID score of 3.22 on MS-COCO. Our detailed analysis on Localized Narratives as well as PartiPrompts (P2), a new holistic benchmark of over 1600 English prompts, demonstrate the effectiveness of Parti across a wide variety of categories and difficulty aspects. We also explore and highlight limitations of our models in order to define and exemplify key areas of focus for further improvements. See https://parti.research.google/ for high-resolution images.
When does dough become a bagel? Analyzing the remaining mistakes on ImageNet
May 09, 2022



Image classification accuracy on the ImageNet dataset has been a barometer for progress in computer vision over the last decade. Several recent papers have questioned the degree to which the benchmark remains useful to the community, yet innovations continue to contribute gains to performance, with today's largest models achieving 90%+ top-1 accuracy. To help contextualize progress on ImageNet and provide a more meaningful evaluation for today's state-of-the-art models, we manually review and categorize every remaining mistake that a few top models make in order to provide insight into the long-tail of errors on one of the most benchmarked datasets in computer vision. We focus on the multi-label subset evaluation of ImageNet, where today's best models achieve upwards of 97% top-1 accuracy. Our analysis reveals that nearly half of the supposed mistakes are not mistakes at all, and we uncover new valid multi-labels, demonstrating that, without careful review, we are significantly underestimating the performance of these models. On the other hand, we also find that today's best models still make a significant number of mistakes (40%) that are obviously wrong to human reviewers. To calibrate future progress on ImageNet, we provide an updated multi-label evaluation set, and we curate ImageNet-Major: a 68-example "major error" slice of the obvious mistakes made by today's top models -- a slice where models should achieve near perfection, but today are far from doing so.
CoCa: Contrastive Captioners are Image-Text Foundation Models
May 04, 2022

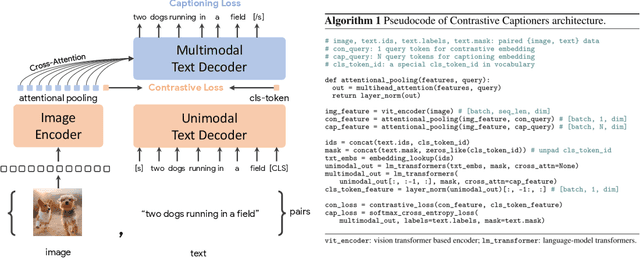
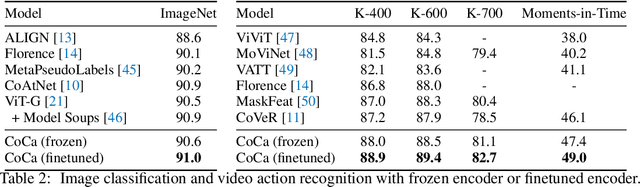
Exploring large-scale pretrained foundation models is of significant interest in computer vision because these models can be quickly transferred to many downstream tasks. This paper presents Contrastive Captioner (CoCa), a minimalist design to pretrain an image-text encoder-decoder foundation model jointly with contrastive loss and captioning loss, thereby subsuming model capabilities from contrastive approaches like CLIP and generative methods like SimVLM. In contrast to standard encoder-decoder transformers where all decoder layers attend to encoder outputs, CoCa omits cross-attention in the first half of decoder layers to encode unimodal text representations, and cascades the remaining decoder layers which cross-attend to the image encoder for multimodal image-text representations. We apply a contrastive loss between unimodal image and text embeddings, in addition to a captioning loss on the multimodal decoder outputs which predicts text tokens autoregressively. By sharing the same computational graph, the two training objectives are computed efficiently with minimal overhead. CoCa is pretrained end-to-end and from scratch on both web-scale alt-text data and annotated images by treating all labels simply as text, seamlessly unifying natural language supervision for representation learning. Empirically, CoCa achieves state-of-the-art performance with zero-shot transfer or minimal task-specific adaptation on a broad range of downstream tasks, spanning visual recognition (ImageNet, Kinetics-400/600/700, Moments-in-Time), crossmodal retrieval (MSCOCO, Flickr30K, MSR-VTT), multimodal understanding (VQA, SNLI-VE, NLVR2), and image captioning (MSCOCO, NoCaps). Notably on ImageNet classification, CoCa obtains 86.3% zero-shot top-1 accuracy, 90.6% with a frozen encoder and learned classification head, and new state-of-the-art 91.0% top-1 accuracy on ImageNet with a finetuned encoder.
To the Point: Efficient 3D Object Detection in the Range Image with Graph Convolution Kernels
Jun 25, 2021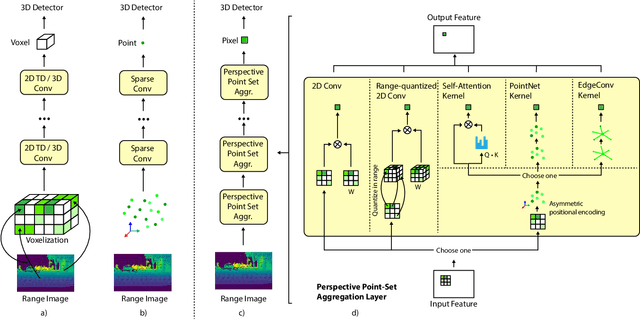
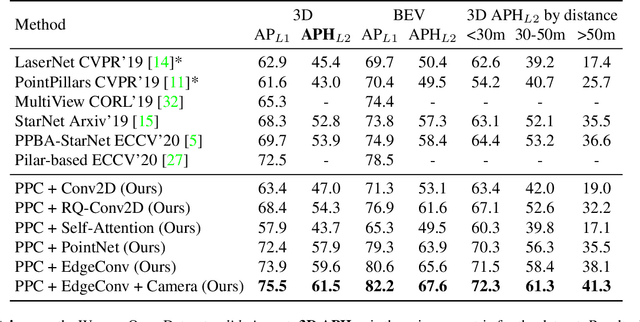
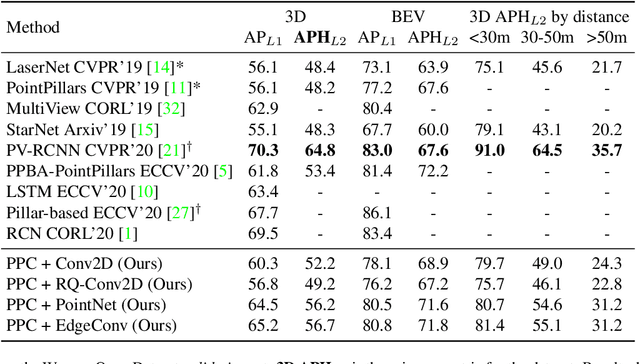
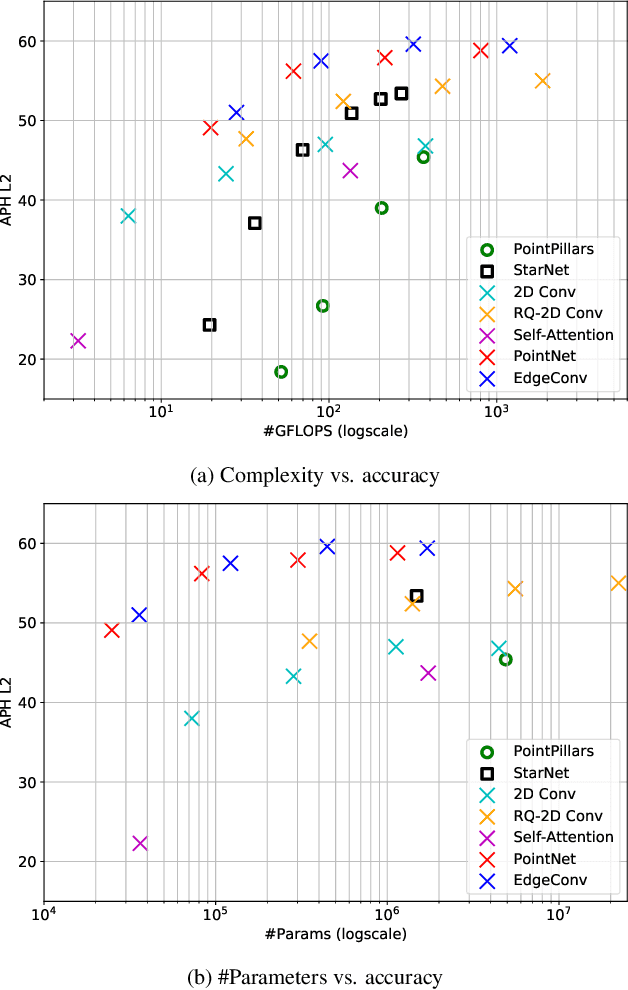
3D object detection is vital for many robotics applications. For tasks where a 2D perspective range image exists, we propose to learn a 3D representation directly from this range image view. To this end, we designed a 2D convolutional network architecture that carries the 3D spherical coordinates of each pixel throughout the network. Its layers can consume any arbitrary convolution kernel in place of the default inner product kernel and exploit the underlying local geometry around each pixel. We outline four such kernels: a dense kernel according to the bag-of-words paradigm, and three graph kernels inspired by recent graph neural network advances: the Transformer, the PointNet, and the Edge Convolution. We also explore cross-modality fusion with the camera image, facilitated by operating in the perspective range image view. Our method performs competitively on the Waymo Open Dataset and improves the state-of-the-art AP for pedestrian detection from 69.7% to 75.5%. It is also efficient in that our smallest model, which still outperforms the popular PointPillars in quality, requires 180 times fewer FLOPS and model parameters
Scene Transformer: A unified multi-task model for behavior prediction and planning
Jun 15, 2021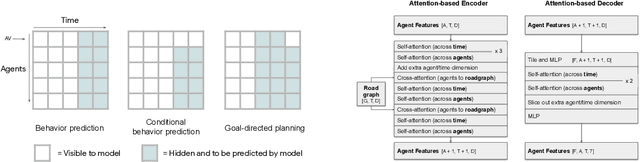
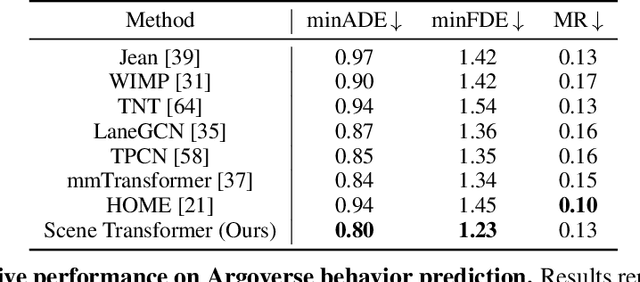
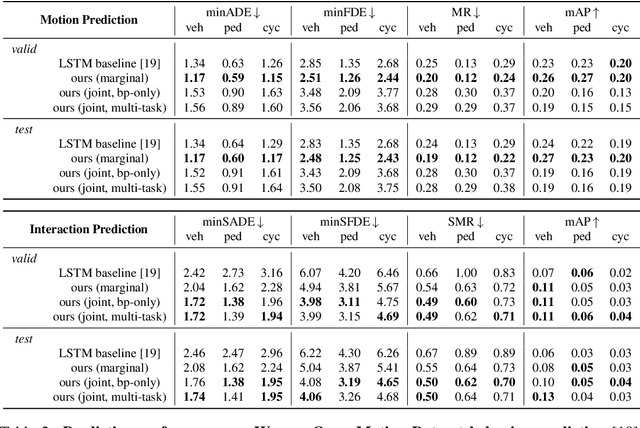
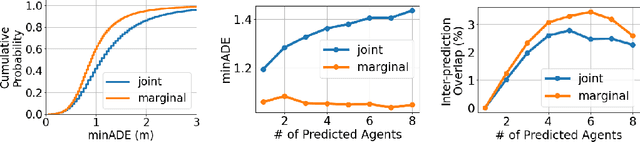
Predicting the future motion of multiple agents is necessary for planning in dynamic environments. This task is challenging for autonomous driving since agents (e.g., vehicles and pedestrians) and their associated behaviors may be diverse and influence each other. Most prior work has focused on first predicting independent futures for each agent based on all past motion, and then planning against these independent predictions. However, planning against fixed predictions can suffer from the inability to represent the future interaction possibilities between different agents, leading to sub-optimal planning. In this work, we formulate a model for predicting the behavior of all agents jointly in real-world driving environments in a unified manner. Inspired by recent language modeling approaches, we use a masking strategy as the query to our model, enabling one to invoke a single model to predict agent behavior in many ways, such as potentially conditioned on the goal or full future trajectory of the autonomous vehicle or the behavior of other agents in the environment. Our model architecture fuses heterogeneous world state in a unified Transformer architecture by employing attention across road elements, agent interactions and time steps. We evaluate our approach on autonomous driving datasets for behavior prediction, and achieve state-of-the-art performance. Our work demonstrates that formulating the problem of behavior prediction in a unified architecture with a masking strategy may allow us to have a single model that can perform multiple motion prediction and planning related tasks effectively.
Large Scale Interactive Motion Forecasting for Autonomous Driving : The Waymo Open Motion Dataset
Apr 20, 2021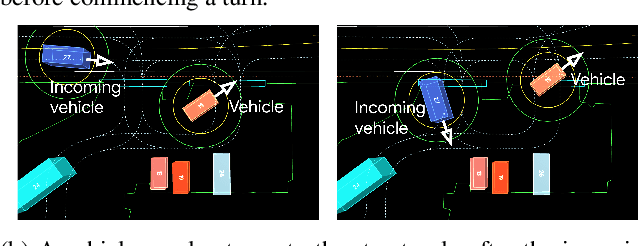
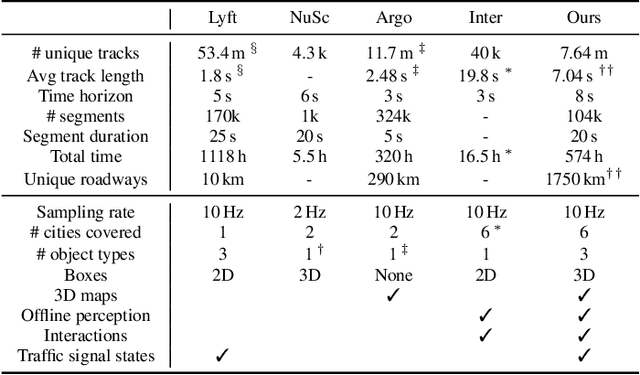
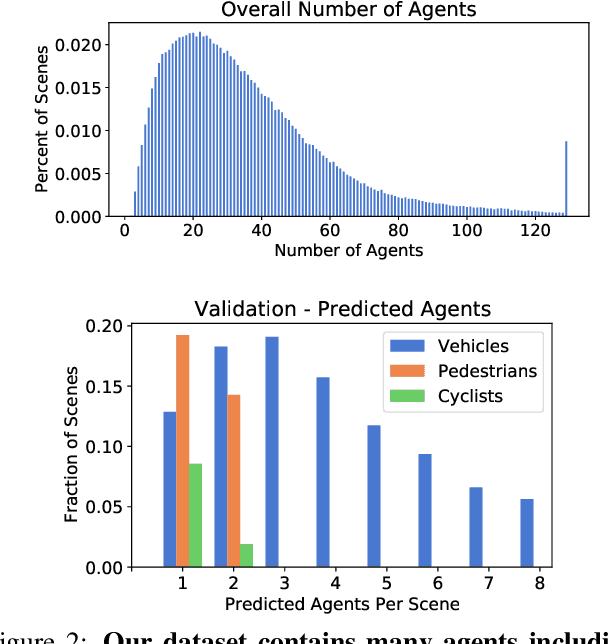
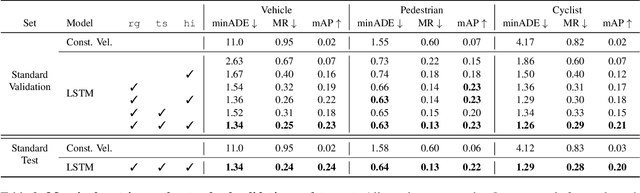
As autonomous driving systems mature, motion forecasting has received increasing attention as a critical requirement for planning. Of particular importance are interactive situations such as merges, unprotected turns, etc., where predicting individual object motion is not sufficient. Joint predictions of multiple objects are required for effective route planning. There has been a critical need for high-quality motion data that is rich in both interactions and annotation to develop motion planning models. In this work, we introduce the most diverse interactive motion dataset to our knowledge, and provide specific labels for interacting objects suitable for developing joint prediction models. With over 100,000 scenes, each 20 seconds long at 10 Hz, our new dataset contains more than 570 hours of unique data over 1750 km of roadways. It was collected by mining for interesting interactions between vehicles, pedestrians, and cyclists across six cities within the United States. We use a high-accuracy 3D auto-labeling system to generate high quality 3D bounding boxes for each road agent, and provide corresponding high definition 3D maps for each scene. Furthermore, we introduce a new set of metrics that provides a comprehensive evaluation of both single agent and joint agent interaction motion forecasting models. Finally, we provide strong baseline models for individual-agent prediction and joint-prediction. We hope that this new large-scale interactive motion dataset will provide new opportunities for advancing motion forecasting models.
Pseudo-labeling for Scalable 3D Object Detection
Mar 02, 2021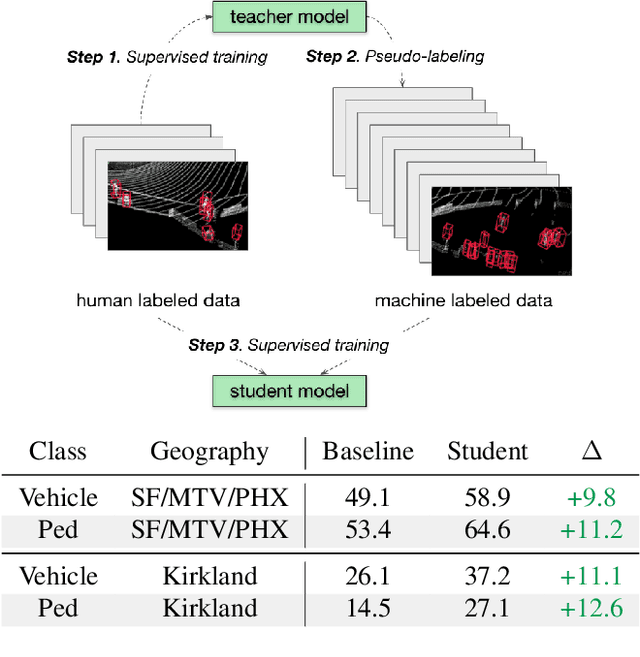
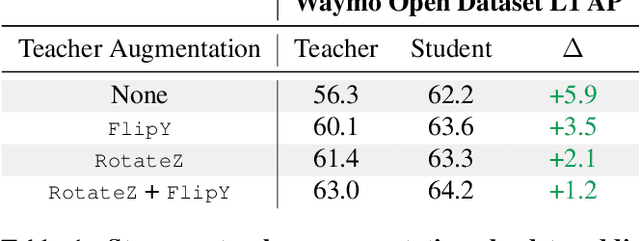
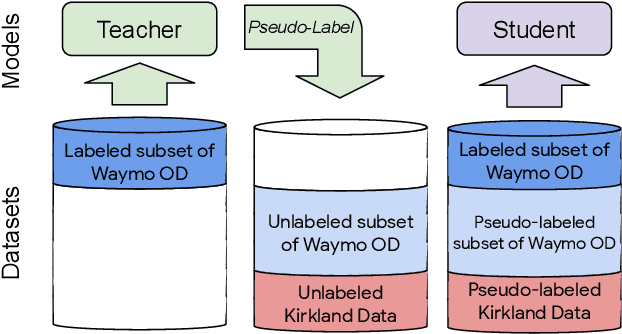
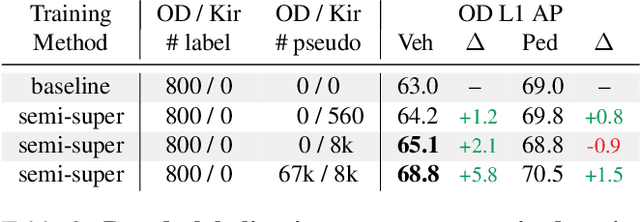
To safely deploy autonomous vehicles, onboard perception systems must work reliably at high accuracy across a diverse set of environments and geographies. One of the most common techniques to improve the efficacy of such systems in new domains involves collecting large labeled datasets, but such datasets can be extremely costly to obtain, especially if each new deployment geography requires additional data with expensive 3D bounding box annotations. We demonstrate that pseudo-labeling for 3D object detection is an effective way to exploit less expensive and more widely available unlabeled data, and can lead to performance gains across various architectures, data augmentation strategies, and sizes of the labeled dataset. Overall, we show that better teacher models lead to better student models, and that we can distill expensive teachers into efficient, simple students. Specifically, we demonstrate that pseudo-label-trained student models can outperform supervised models trained on 3-10 times the amount of labeled examples. Using PointPillars [24], a two-year-old architecture, as our student model, we are able to achieve state of the art accuracy simply by leveraging large quantities of pseudo-labeled data. Lastly, we show that these student models generalize better than supervised models to a new domain in which we only have unlabeled data, making pseudo-label training an effective form of unsupervised domain adaptation.
Streaming Object Detection for 3-D Point Clouds
May 04, 2020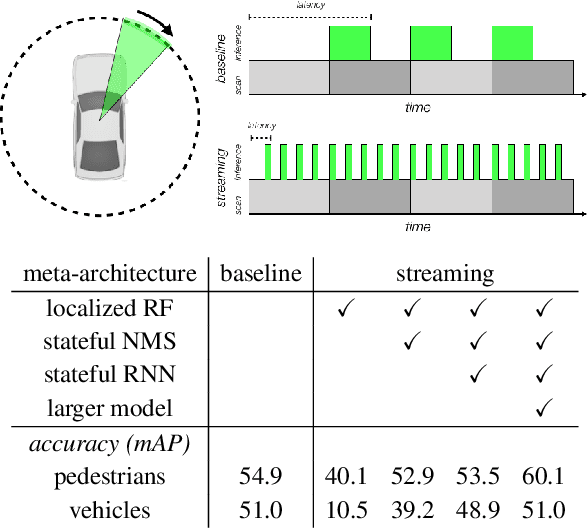
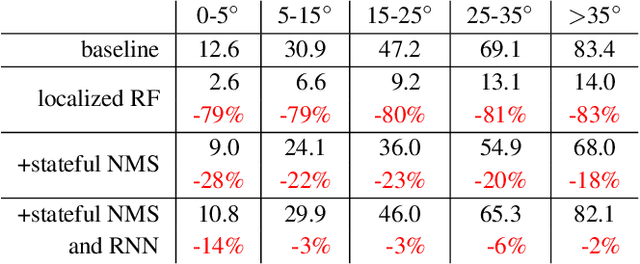
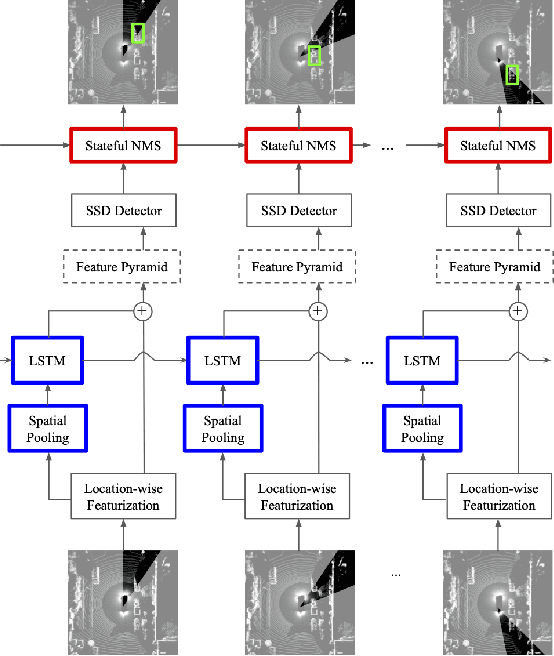
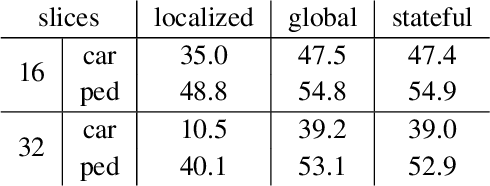
Autonomous vehicles operate in a dynamic environment, where the speed with which a vehicle can perceive and react impacts the safety and efficacy of the system. LiDAR provides a prominent sensory modality that informs many existing perceptual systems including object detection, segmentation, motion estimation, and action recognition. The latency for perceptual systems based on point cloud data can be dominated by the amount of time for a complete rotational scan (e.g. 100 ms). This built-in data capture latency is artificial, and based on treating the point cloud as a camera image in order to leverage camera-inspired architectures. However, unlike camera sensors, most LiDAR point cloud data is natively a streaming data source in which laser reflections are sequentially recorded based on the precession of the laser beam. In this work, we explore how to build an object detector that removes this artificial latency constraint, and instead operates on native streaming data in order to significantly reduce latency. This approach has the added benefit of reducing the peak computational burden on inference hardware by spreading the computation over the acquisition time for a scan. We demonstrate a family of streaming detection systems based on sequential modeling through a series of modifications to the traditional detection meta-architecture. We highlight how this model may achieve competitive if not superior predictive performance with state-of-the-art, traditional non-streaming detection systems while achieving significant latency gains (e.g. 1/15'th - 1/3'rd of peak latency). Our results show that operating on LiDAR data in its native streaming formulation offers several advantages for self driving object detection -- advantages that we hope will be useful for any LiDAR perception system where minimizing latency is critical for safe and efficient operation.