 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws of Motion Forecasting and Planning -- A Technical Report
Jun 09, 2025We study the empirical scaling laws of a family of encoder-decoder autoregressive transformer models on the task of joint motion forecasting and planning in the autonomous driving domain. Using a 500 thousand hours driving dataset, we demonstrate that, similar to language modeling, model performance improves as a power-law function of the total compute budget, and we observe a strong correlation between model training loss and model evaluation metrics. Most interestingly, closed-loop metrics also improve with scaling, which has important implications for the suitability of open-loop metrics for model development and hill climbing. We also study the optimal scaling of the number of transformer parameters and the training data size for a training compute-optimal model. We find that as the training compute budget grows, optimal scaling requires increasing the model size 1.5x as fast as the dataset size. We also study inference-time compute scaling, where we observe that sampling and clustering the output of smaller models makes them competitive with larger models, up to a crossover point beyond which a larger models becomes more inference-compute efficient. Overall, our experimental results demonstrate that optimizing the training and inference-time scaling properties of motion forecasting and planning models is a key lever for improving their performance to address a wide variety of driving scenarios. Finally, we briefly study the utility of training on general logged driving data of other agents to improve the performance of the ego-agent, an important research area to address the scarcity of robotics data for large capacity models training.
MoST: Multi-modality Scene Tokenization for Motion Prediction
Apr 30, 2024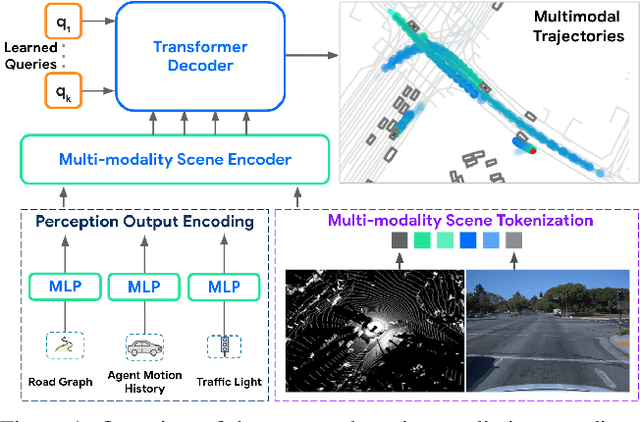

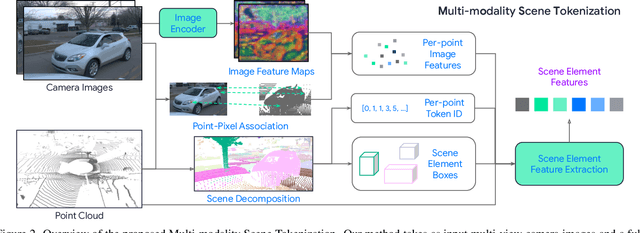
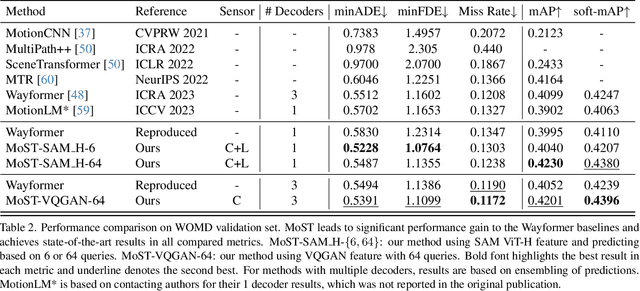
Many existing motion prediction approaches rely on symbolic perception outputs to generate agent trajectories, such as bounding boxes, road graph information and traffic lights. This symbolic representation is a high-level abstraction of the real world, which may render the motion prediction model vulnerable to perception errors (e.g., failures in detecting open-vocabulary obstacles) while missing salient information from the scene context (e.g., poor road conditions). An alternative paradigm is end-to-end learning from raw sensors. However, this approach suffers from the lack of interpretability and requires significantly more training resources. In this work, we propose tokenizing the visual world into a compact set of scene elements and then leveraging pre-trained image foundation models and LiDAR neural networks to encode all the scene elements in an open-vocabulary manner. The image foundation model enables our scene tokens to encode the general knowledge of the open world while the LiDAR neural network encodes geometry information. Our proposed representation can efficiently encode the multi-frame multi-modality observations with a few hundred tokens and is compatible with most transformer-based architectures. To evaluate our method, we have augmented Waymo Open Motion Dataset with camera embeddings. Experiments over Waymo Open Motion Dataset show that our approach leads to significant performance improvements over the state-of-the-art.
Scaling Motion Forecasting Models with Ensemble Distillation
Apr 05, 2024



Motion forecasting has become an increasingly critical component of autonomous robotic systems. Onboard compute budgets typically limit the accuracy of real-time systems. In this work we propose methods of improving motion forecasting systems subject to limited compute budgets by combining model ensemble and distillation techniques. The use of ensembles of deep neural networks has been shown to improve generalization accuracy in many application domains. We first demonstrate significant performance gains by creating a large ensemble of optimized single models. We then develop a generalized framework to distill motion forecasting model ensembles into small student models which retain high performance with a fraction of the computing cost. For this study we focus on the task of motion forecasting using real world data from autonomous driving systems. We develop ensemble models that are very competitive on the Waymo Open Motion Dataset (WOMD) and Argoverse leaderboards. From these ensembles, we train distilled student models which have high performance at a fraction of the compute costs. These experiments demonstrate distillation from ensembles as an effective method for improving accuracy of predictive models for robotic systems with limited compute budgets.
Unsupervised 3D Perception with 2D Vision-Language Distillation for Autonomous Driving
Sep 25, 2023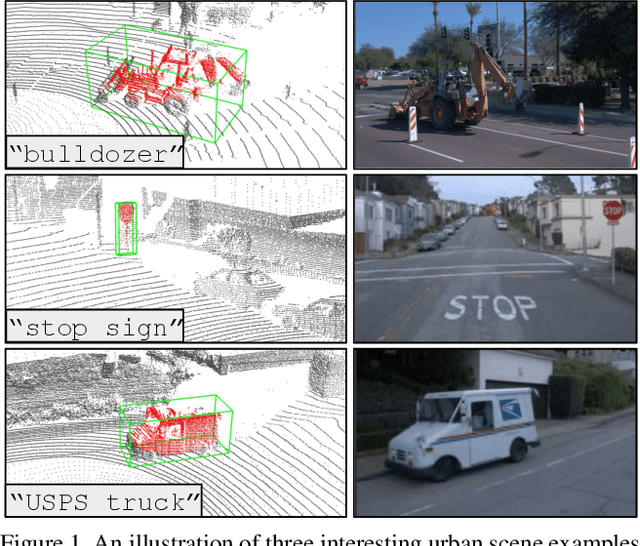
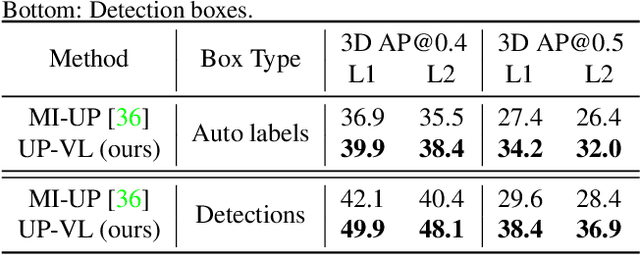
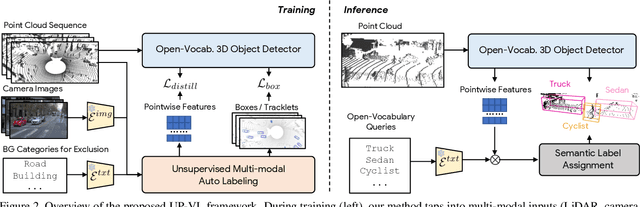

Closed-set 3D perception models trained on only a pre-defined set of object categories can be inadequate for safety critical applications such as autonomous driving where new object types can be encountered after deployment. In this paper, we present a multi-modal auto labeling pipeline capable of generating amodal 3D bounding boxes and tracklets for training models on open-set categories without 3D human labels. Our pipeline exploits motion cues inherent in point cloud sequences in combination with the freely available 2D image-text pairs to identify and track all traffic participants. Compared to the recent studies in this domain, which can only provide class-agnostic auto labels limited to moving objects, our method can handle both static and moving objects in the unsupervised manner and is able to output open-vocabulary semantic labels thanks to the proposed vision-language knowledge distillation. Experiments on the Waymo Open Dataset show that our approach outperforms the prior work by significant margins on various unsupervised 3D perception tasks.
WOMD-LiDAR: Raw Sensor Dataset Benchmark for Motion Forecasting
Apr 07, 2023



Widely adopted motion forecasting datasets substitute the observed sensory inputs with higher-level abstractions such as 3D boxes and polylines. These sparse shapes are inferred through annotating the original scenes with perception systems' predictions. Such intermediate representations tie the quality of the motion forecasting models to the performance of computer vision models. Moreover, the human-designed explicit interfaces between perception and motion forecasting typically pass only a subset of the semantic information present in the original sensory input. To study the effect of these modular approaches, design new paradigms that mitigate these limitations, and accelerate the development of end-to-end motion forecasting models, we augment the Waymo Open Motion Dataset (WOMD) with large-scale, high-quality, diverse LiDAR data for the motion forecasting task. The new augmented dataset WOMD-LiDAR consists of over 100,000 scenes that each spans 20 seconds, consisting of well-synchronized and calibrated high quality LiDAR point clouds captured across a range of urban and suburban geographies (https://waymo.com/open/data/motion/). Compared to Waymo Open Dataset (WOD), WOMD-LiDAR dataset contains 100x more scenes. Furthermore, we integrate the LiDAR data into the motion forecasting model training and provide a strong baseline. Experiments show that the LiDAR data brings improvement in the motion forecasting task. We hope that WOMD-LiDAR will provide new opportunities for boosting end-to-end motion forecasting models.
Motion Inspired Unsupervised Perception and Prediction in Autonomous Driving
Oct 14, 2022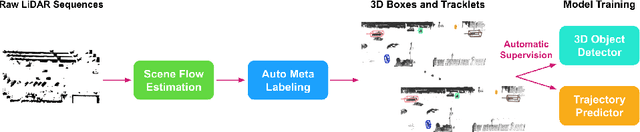
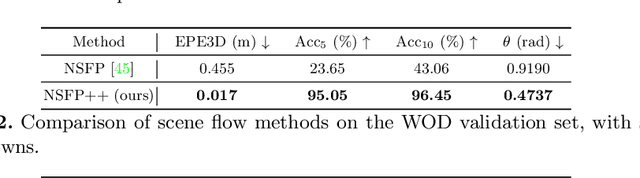

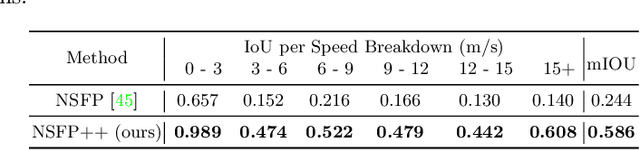
Learning-based perception and prediction modules in modern autonomous driving systems typically rely on expensive human annotation and are designed to perceive only a handful of predefined object categories. This closed-set paradigm is insufficient for the safety-critical autonomous driving task, where the autonomous vehicle needs to process arbitrarily many types of traffic participants and their motion behaviors in a highly dynamic world. To address this difficulty, this paper pioneers a novel and challenging direction, i.e., training perception and prediction models to understand open-set moving objects, with no human supervision. Our proposed framework uses self-learned flow to trigger an automated meta labeling pipeline to achieve automatic supervision. 3D detection experiments on the Waymo Open Dataset show that our method significantly outperforms classical unsupervised approaches and is even competitive to the counterpart with supervised scene flow. We further show that our approach generates highly promising results in open-set 3D detection and trajectory prediction, confirming its potential in closing the safety gap of fully supervised systems.
CausalAgents: A Robustness Benchmark for Motion Forecasting using Causal Relationships
Jul 07, 2022


As machine learning models become increasingly prevalent in motion forecasting systems for autonomous vehicles (AVs), it is critical that we ensure that model predictions are safe and reliable. However, exhaustively collecting and labeling the data necessary to fully test the long tail of rare and challenging scenarios is difficult and expensive. In this work, we construct a new benchmark for evaluating and improving model robustness by applying perturbations to existing data. Specifically, we conduct an extensive labeling effort to identify causal agents, or agents whose presence influences human driver behavior in any way, in the Waymo Open Motion Dataset (WOMD), and we use these labels to perturb the data by deleting non-causal agents from the scene. We then evaluate a diverse set of state-of-the-art deep-learning model architectures on our proposed benchmark and find that all models exhibit large shifts under perturbation. Under non-causal perturbations, we observe a $25$-$38\%$ relative change in minADE as compared to the original. We then investigate techniques to improve model robustness, including increasing the training dataset size and using targeted data augmentations that drop agents throughout training. We plan to provide the causal agent labels as an additional attribute to WOMD and release the robustness benchmarks to aid the community in building more reliable and safe deep-learning models for motion forecasting.
StopNet: Scalable Trajectory and Occupancy Prediction for Urban Autonomous Driving
Jun 02, 2022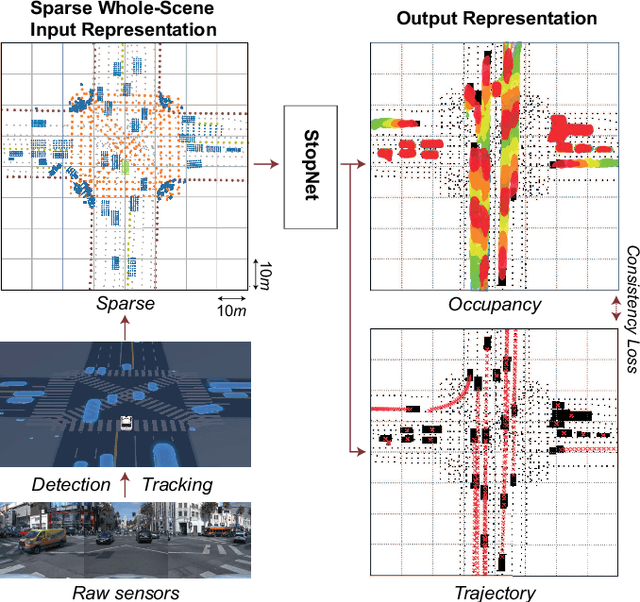
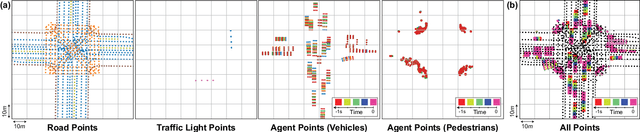
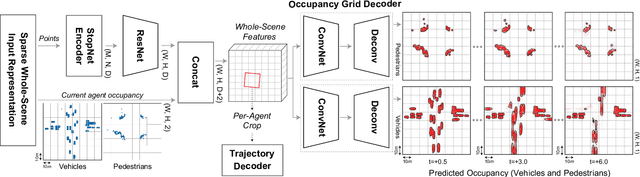
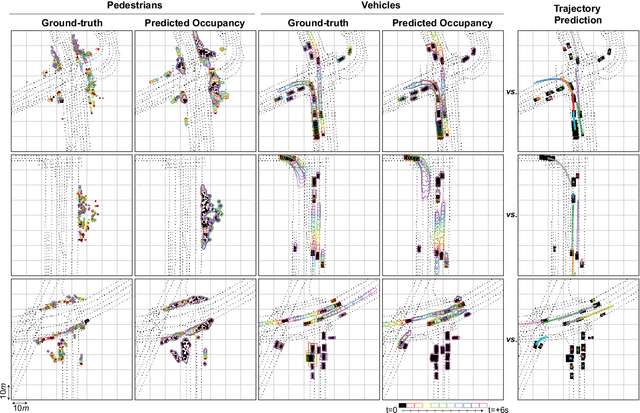
We introduce a motion forecasting (behavior prediction) method that meets the latency requirements for autonomous driving in dense urban environments without sacrificing accuracy. A whole-scene sparse input representation allows StopNet to scale to predicting trajectories for hundreds of road agents with reliable latency. In addition to predicting trajectories, our scene encoder lends itself to predicting whole-scene probabilistic occupancy grids, a complementary output representation suitable for busy urban environments. Occupancy grids allow the AV to reason collectively about the behavior of groups of agents without processing their individual trajectories. We demonstrate the effectiveness of our sparse input representation and our model in terms of computation and accuracy over three datasets. We further show that co-training consistent trajectory and occupancy predictions improves upon state-of-the-art performance under standard metrics.
Large Scale Interactive Motion Forecasting for Autonomous Driving : The Waymo Open Motion Dataset
Apr 20, 2021
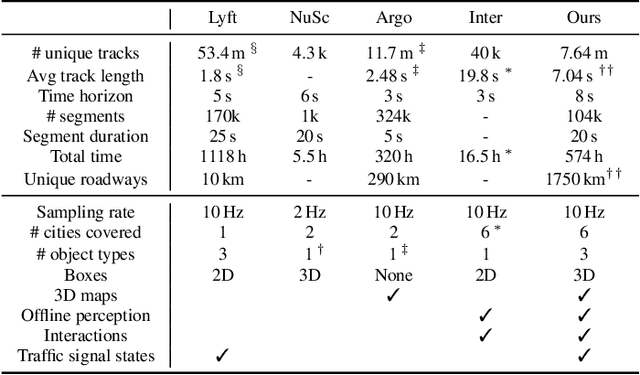
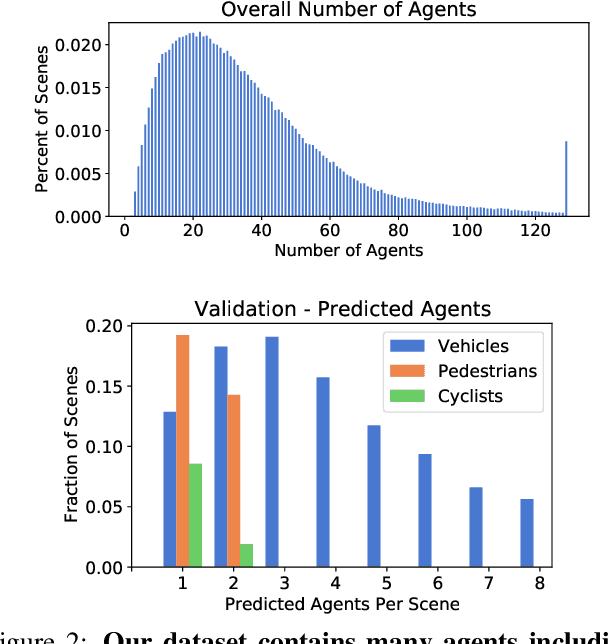
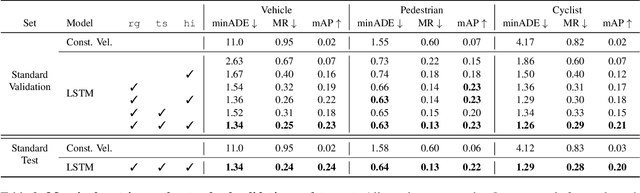
As autonomous driving systems mature, motion forecasting has received increasing attention as a critical requirement for planning. Of particular importance are interactive situations such as merges, unprotected turns, etc., where predicting individual object motion is not sufficient. Joint predictions of multiple objects are required for effective route planning. There has been a critical need for high-quality motion data that is rich in both interactions and annotation to develop motion planning models. In this work, we introduce the most diverse interactive motion dataset to our knowledge, and provide specific labels for interacting objects suitable for developing joint prediction models. With over 100,000 scenes, each 20 seconds long at 10 Hz, our new dataset contains more than 570 hours of unique data over 1750 km of roadways. It was collected by mining for interesting interactions between vehicles, pedestrians, and cyclists across six cities within the United States. We use a high-accuracy 3D auto-labeling system to generate high quality 3D bounding boxes for each road agent, and provide corresponding high definition 3D maps for each scene. Furthermore, we introduce a new set of metrics that provides a comprehensive evaluation of both single agent and joint agent interaction motion forecasting models. Finally, we provide strong baseline models for individual-agent prediction and joint-prediction. We hope that this new large-scale interactive motion dataset will provide new opportunities for advancing motion forecasting models.
Scalability in Perception for Autonomous Driving: Waymo Open Dataset
Dec 18, 2019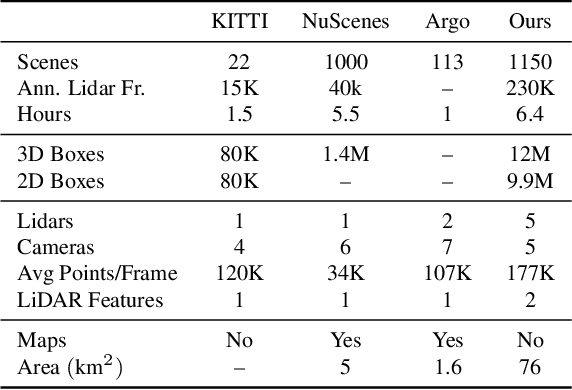



The research community has increasing interest in autonomous driving research, despite the resource intensity of obtaining representative real world data. Existing self-driving datasets are limited in the scale and variation of the environments they capture, even though generalization within and between operating regions is crucial to the overall viability of the technology. In an effort to help align the research community's contributions with real-world self-driving problems, we introduce a new large scale, high quality, diverse dataset. Our new dataset consists of 1150 scenes that each span 20 seconds, consisting of well synchronized and calibrated high quality LiDAR and camera data captured across a range of urban and suburban geographies. It is 15x more diverse than the largest camera+LiDAR dataset available based on our proposed diversity metric. We exhaustively annotated this data with 2D (camera image) and 3D (LiDAR) bounding boxes, with consistent identifiers across frames. Finally, we provide strong baselines for 2D as well as 3D detection and tracking tasks. We further study the effects of dataset size and generalization across geographies on 3D detection methods. Find data, code and more up-to-date information at http://www.waymo.com/open.