 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionLM: Multi-Agent Motion Forecasting as Language Modeling
Sep 28, 2023Reliable forecasting of the future behavior of road agents is a critical component to safe planning in autonomous vehicles. Here, we represent continuous trajectories as sequences of discrete motion tokens and cast multi-agent motion prediction as a language modeling task over this domain. Our model, MotionLM, provides several advantages: First, it does not require anchors or explicit latent variable optimization to learn multimodal distributions. Instead, we leverage a single standard language modeling objective, maximizing the average log probability over sequence tokens. Second, our approach bypasses post-hoc interaction heuristics where individual agent trajectory generation is conducted prior to interactive scoring. Instead, MotionLM produces joint distributions over interactive agent futures in a single autoregressive decoding process. In addition, the model's sequential factorization enables temporally causal conditional rollouts. The proposed approach establishes new state-of-the-art performance for multi-agent motion prediction on the Waymo Open Motion Dataset, ranking 1st on the interactive challenge leaderboard.
Pedestrian Crossing Action Recognition and Trajectory Prediction with 3D Human Keypoints
Jun 01, 2023



Accurate understanding and prediction of human behaviors are critical prerequisites for autonomous vehicles, especially in highly dynamic and interactive scenarios such as intersections in dense urban areas. In this work, we aim at identifying crossing pedestrians and predicting their future trajectories. To achieve these goals, we not only need the context information of road geometry and other traffic participants but also need fine-grained information of the human pose, motion and activity, which can be inferred from human keypoints. In this paper, we propose a novel multi-task learning framework for pedestrian crossing action recognition and trajectory prediction, which utilizes 3D human keypoints extracted from raw sensor data to capture rich information on human pose and activity. Moreover, we propose to apply two auxiliary tasks and contrastive learning to enable auxiliary supervisions to improve the learned keypoints representation, which further enhances the performance of major tasks. We validate our approach on a large-scale in-house dataset, as well as a public benchmark dataset, and show that our approach achieves state-of-the-art performance on a wide range of evaluation metrics. The effectiveness of each model component is validated in a detailed ablation study.
Wayformer: Motion Forecasting via Simple & Efficient Attention Networks
Jul 12, 2022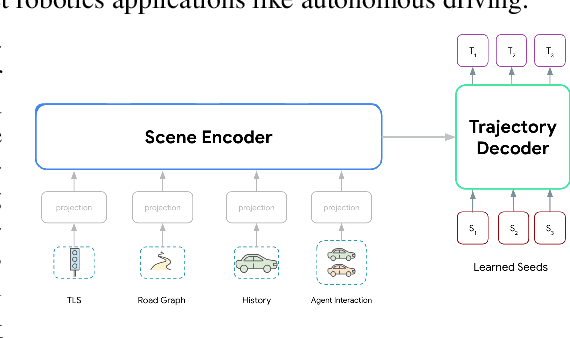
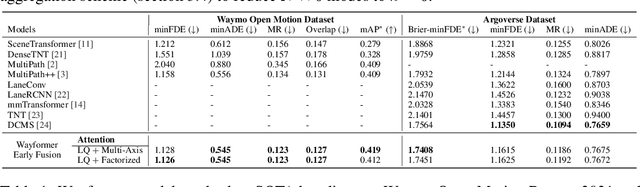
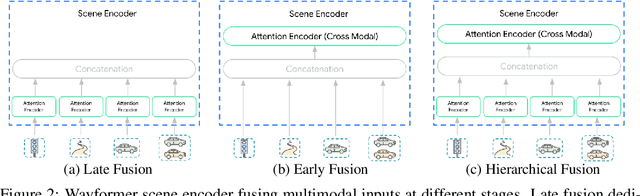
Motion forecasting for autonomous driving is a challenging task because complex driving scenarios result in a heterogeneous mix of static and dynamic inputs. It is an open problem how best to represent and fuse information about road geometry, lane connectivity, time-varying traffic light state, and history of a dynamic set of agents and their interactions into an effective encoding. To model this diverse set of input features, many approaches proposed to design an equally complex system with a diverse set of modality specific modules. This results in systems that are difficult to scale, extend, or tune in rigorous ways to trade off quality and efficiency. In this paper, we present Wayformer, a family of attention based architectures for motion forecasting that are simple and homogeneous. Wayformer offers a compact model description consisting of an attention based scene encoder and a decoder. In the scene encoder we study the choice of early, late and hierarchical fusion of the input modalities. For each fusion type we explore strategies to tradeoff efficiency and quality via factorized attention or latent query attention. We show that early fusion, despite its simplicity of construction, is not only modality agnostic but also achieves state-of-the-art results on both Waymo Open MotionDataset (WOMD) and Argoverse leaderboards, demonstrating the effectiveness of our design philosophy
CausalAgents: A Robustness Benchmark for Motion Forecasting using Causal Relationships
Jul 07, 2022


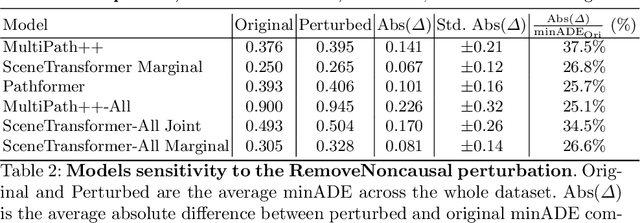
As machine learning models become increasingly prevalent in motion forecasting systems for autonomous vehicles (AVs), it is critical that we ensure that model predictions are safe and reliable. However, exhaustively collecting and labeling the data necessary to fully test the long tail of rare and challenging scenarios is difficult and expensive. In this work, we construct a new benchmark for evaluating and improving model robustness by applying perturbations to existing data. Specifically, we conduct an extensive labeling effort to identify causal agents, or agents whose presence influences human driver behavior in any way, in the Waymo Open Motion Dataset (WOMD), and we use these labels to perturb the data by deleting non-causal agents from the scene. We then evaluate a diverse set of state-of-the-art deep-learning model architectures on our proposed benchmark and find that all models exhibit large shifts under perturbation. Under non-causal perturbations, we observe a $25$-$38\%$ relative change in minADE as compared to the original. We then investigate techniques to improve model robustness, including increasing the training dataset size and using targeted data augmentations that drop agents throughout training. We plan to provide the causal agent labels as an additional attribute to WOMD and release the robustness benchmarks to aid the community in building more reliable and safe deep-learning models for motion forecasting.
MultiPath++: Efficient Information Fusion and Trajectory Aggregation for Behavior Prediction
Dec 22, 2021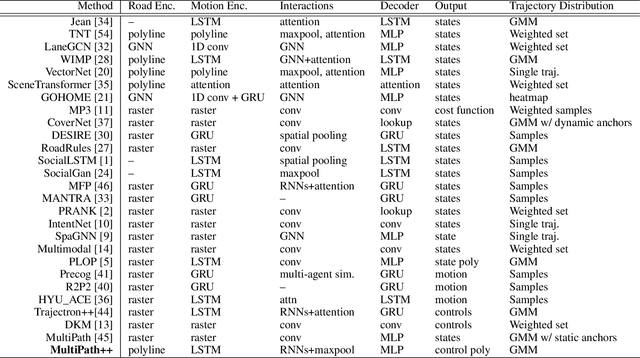
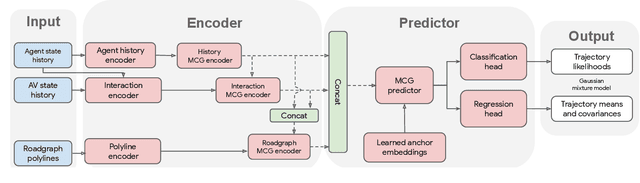
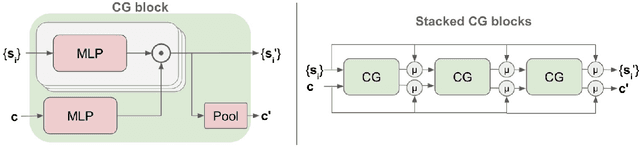
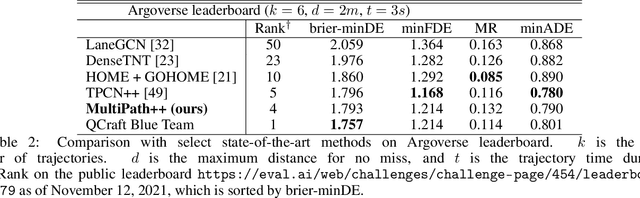
Predicting the future behavior of road users is one of the most challenging and important problems in autonomous driving. Applying deep learning to this problem requires fusing heterogeneous world state in the form of rich perception signals and map information, and inferring highly multi-modal distributions over possible futures. In this paper, we present MultiPath++, a future prediction model that achieves state-of-the-art performance on popular benchmarks. MultiPath++ improves the MultiPath architecture by revisiting many design choices. The first key design difference is a departure from dense image-based encoding of the input world state in favor of a sparse encoding of heterogeneous scene elements: MultiPath++ consumes compact and efficient polylines to describe road features, and raw agent state information directly (e.g., position, velocity, acceleration). We propose a context-aware fusion of these elements and develop a reusable multi-context gating fusion component. Second, we reconsider the choice of pre-defined, static anchors, and develop a way to learn latent anchor embeddings end-to-end in the model. Lastly, we explore ensembling and output aggregation techniques -- common in other ML domains -- and find effective variants for our probabilistic multimodal output representation. We perform an extensive ablation on these design choices, and show that our proposed model achieves state-of-the-art performance on the Argoverse Motion Forecasting Competition and the Waymo Open Dataset Motion Prediction Challenge.
Agent Prioritization for Autonomous Navigation
Sep 19, 2019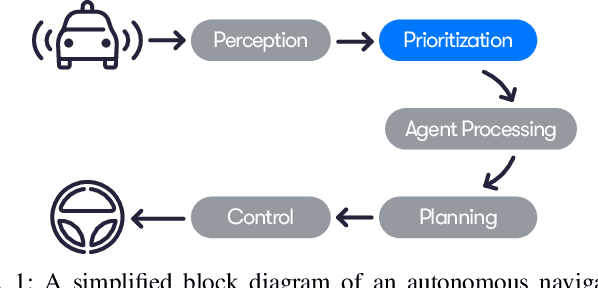
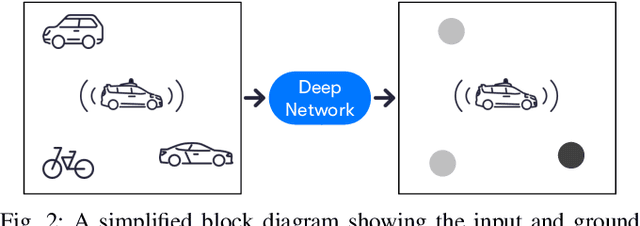
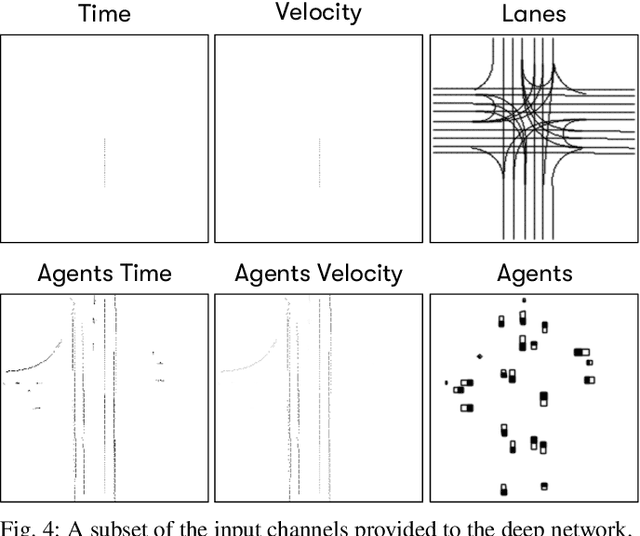
In autonomous navigation, a planning system reasons about other agents to plan a safe and plausible trajectory. Before planning starts, agents are typically processed with computationally intensive models for recognition, tracking, motion estimation and prediction. With limited computational resources and a large number of agents to process in real time, it becomes important to efficiently rank agents according to their impact on the decision making process. This allows spending more time processing the most important agents. We propose a system to rank agents around an autonomous vehicle (AV) in real time. We automatically generate a ranking data set by running the planner in simulation on real-world logged data, where we can afford to run more accurate and expensive models on all the agents. The causes of various planner actions are logged and used for assigning ground truth importance scores. The generated data set can be used to learn ranking models. In particular, we show the utility of combining learned features, via a convolutional neural network, with engineered features designed to capture domain knowledge. We show the benefits of various design choices experimentally. When tested on real AVs, our system demonstrates the capability of understanding complex driving situations.
New Advances and Theoretical Insights into EDML
Oct 16, 2012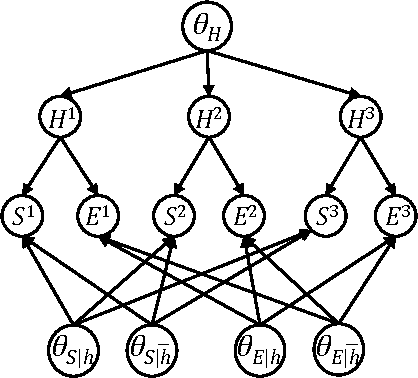
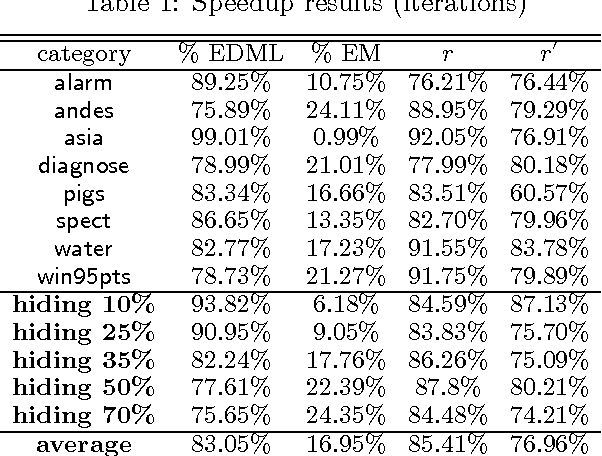
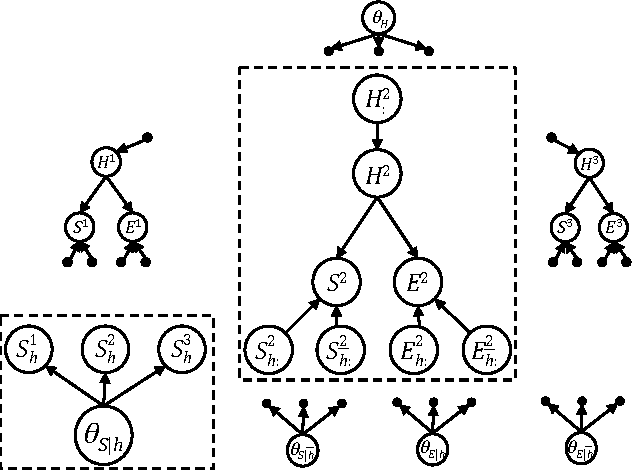
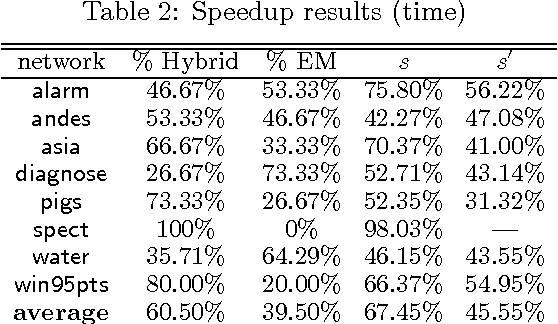
EDML is a recently proposed algorithm for learning MAP parameters in Bayesian networks. In this paper, we present a number of new advances and insights on the EDML algorithm. First, we provide the multivalued extension of EDML, originally proposed for Bayesian networks over binary variables. Next, we identify a simplified characterization of EDML that further implies a simple fixed-point algorithm for the convex optimization problem that underlies it. This characterization further reveals a connection between EDML and EM: a fixed point of EDML is a fixed point of EM, and vice versa. We thus identify also a new characterization of EM fixed points, but in the semantics of EDML. Finally, we propose a hybrid EDML/EM algorithm that takes advantage of the improved empirical convergence behavior of EDML, while maintaining the monotonic improvement property of EM.
EDML: A Method for Learning Parameters in Bayesian Networks
Feb 14, 2012


We propose a method called EDML for learning MAP parameters in binary Bayesian networks under incomplete data. The method assumes Beta priors and can be used to learn maximum likelihood parameters when the priors are uninformative. EDML exhibits interesting behaviors, especially when compared to EM. We introduce EDML, explain its origin, and study some of its properties both analytically and empirically.