Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDML: A Method for Learning Parameters in Bayesian Networks
Paper and Code
Feb 14, 2012

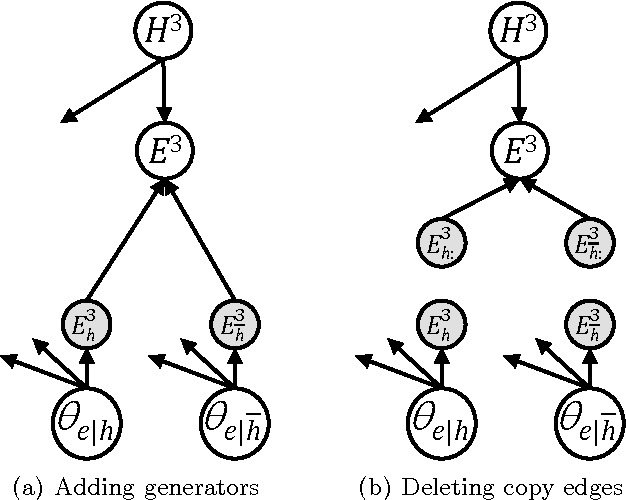

We propose a method called EDML for learning MAP parameters in binary Bayesian networks under incomplete data. The method assumes Beta priors and can be used to learn maximum likelihood parameters when the priors are uninformative. EDML exhibits interesting behaviors, especially when compared to EM. We introduce EDML, explain its origin, and study some of its properties both analytically and empirically.
View paper on