 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionLM: Multi-Agent Motion Forecasting as Language Modeling
Sep 28, 2023Reliable forecasting of the future behavior of road agents is a critical component to safe planning in autonomous vehicles. Here, we represent continuous trajectories as sequences of discrete motion tokens and cast multi-agent motion prediction as a language modeling task over this domain. Our model, MotionLM, provides several advantages: First, it does not require anchors or explicit latent variable optimization to learn multimodal distributions. Instead, we leverage a single standard language modeling objective, maximizing the average log probability over sequence tokens. Second, our approach bypasses post-hoc interaction heuristics where individual agent trajectory generation is conducted prior to interactive scoring. Instead, MotionLM produces joint distributions over interactive agent futures in a single autoregressive decoding process. In addition, the model's sequential factorization enables temporally causal conditional rollouts. The proposed approach establishes new state-of-the-art performance for multi-agent motion prediction on the Waymo Open Motion Dataset, ranking 1st on the interactive challenge leaderboard.
Wayformer: Motion Forecasting via Simple & Efficient Attention Networks
Jul 12, 2022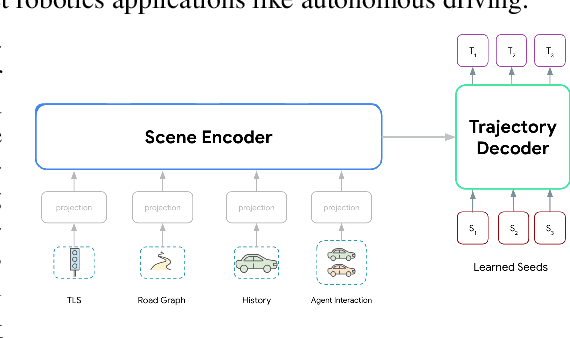
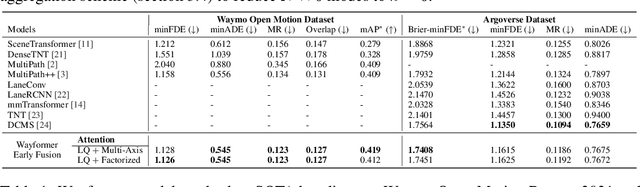
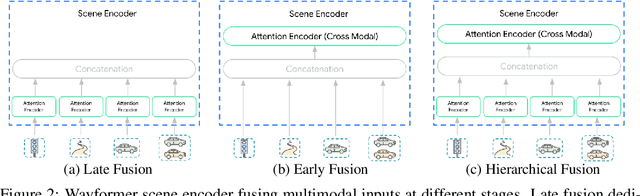
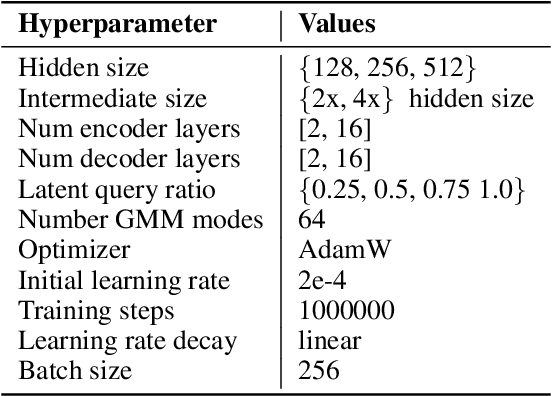
Motion forecasting for autonomous driving is a challenging task because complex driving scenarios result in a heterogeneous mix of static and dynamic inputs. It is an open problem how best to represent and fuse information about road geometry, lane connectivity, time-varying traffic light state, and history of a dynamic set of agents and their interactions into an effective encoding. To model this diverse set of input features, many approaches proposed to design an equally complex system with a diverse set of modality specific modules. This results in systems that are difficult to scale, extend, or tune in rigorous ways to trade off quality and efficiency. In this paper, we present Wayformer, a family of attention based architectures for motion forecasting that are simple and homogeneous. Wayformer offers a compact model description consisting of an attention based scene encoder and a decoder. In the scene encoder we study the choice of early, late and hierarchical fusion of the input modalities. For each fusion type we explore strategies to tradeoff efficiency and quality via factorized attention or latent query attention. We show that early fusion, despite its simplicity of construction, is not only modality agnostic but also achieves state-of-the-art results on both Waymo Open MotionDataset (WOMD) and Argoverse leaderboards, demonstrating the effectiveness of our design philosophy
Training on Test Data with Bayesian Adaptation for Covariate Shift
Sep 27, 2021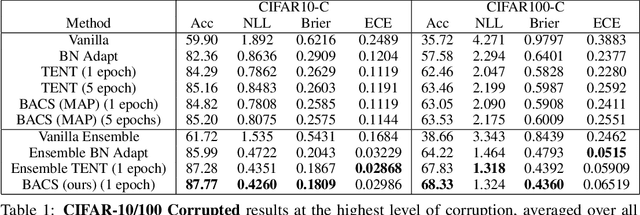
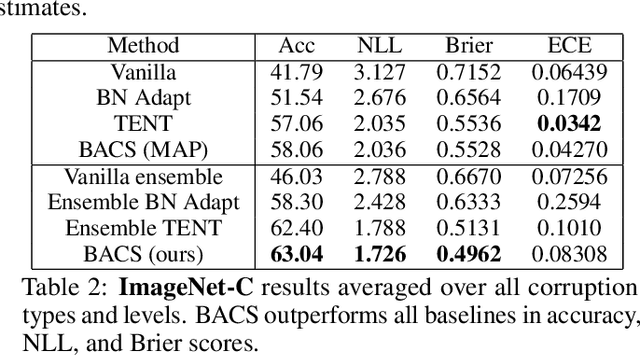
When faced with distribution shift at test time, deep neural networks often make inaccurate predictions with unreliable uncertainty estimates. While improving the robustness of neural networks is one promising approach to mitigate this issue, an appealing alternate to robustifying networks against all possible test-time shifts is to instead directly adapt them to unlabeled inputs from the particular distribution shift we encounter at test time. However, this poses a challenging question: in the standard Bayesian model for supervised learning, unlabeled inputs are conditionally independent of model parameters when the labels are unobserved, so what can unlabeled data tell us about the model parameters at test-time? In this paper, we derive a Bayesian model that provides for a well-defined relationship between unlabeled inputs under distributional shift and model parameters, and show how approximate inference in this model can be instantiated with a simple regularized entropy minimization procedure at test-time. We evaluate our method on a variety of distribution shifts for image classification, including image corruptions, natural distribution shifts, and domain adaptation settings, and show that our method improves both accuracy and uncertainty estimation.
MURAL: Meta-Learning Uncertainty-Aware Rewards for Outcome-Driven Reinforcement Learning
Jul 18, 2021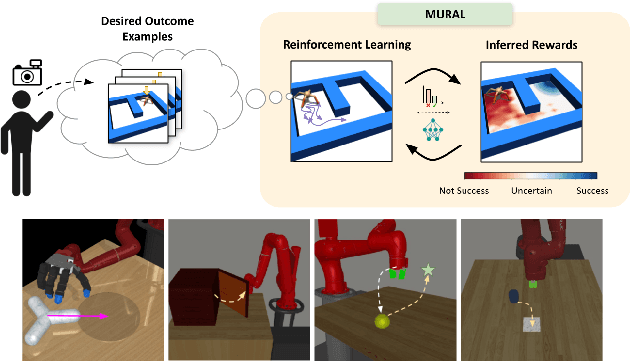

Exploration in reinforcement learning is a challenging problem: in the worst case, the agent must search for high-reward states that could be hidden anywhere in the state space. Can we define a more tractable class of RL problems, where the agent is provided with examples of successful outcomes? In this problem setting, the reward function can be obtained automatically by training a classifier to categorize states as successful or not. If trained properly, such a classifier can provide a well-shaped objective landscape that both promotes progress toward good states and provides a calibrated exploration bonus. In this work, we show that an uncertainty aware classifier can solve challenging reinforcement learning problems by both encouraging exploration and provided directed guidance towards positive outcomes. We propose a novel mechanism for obtaining these calibrated, uncertainty-aware classifiers based on an amortized technique for computing the normalized maximum likelihood (NML) distribution. To make this tractable, we propose a novel method for computing the NML distribution by using meta-learning. We show that the resulting algorithm has a number of intriguing connections to both count-based exploration methods and prior algorithms for learning reward functions, while also providing more effective guidance towards the goal. We demonstrate that our algorithm solves a number of challenging navigation and robotic manipulation tasks which prove difficult or impossible for prior methods.
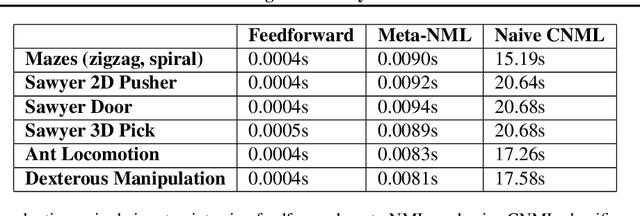
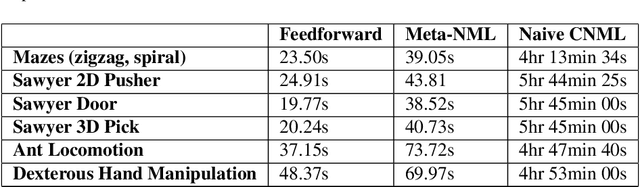
Amortized Conditional Normalized Maximum Likelihood
Nov 05, 2020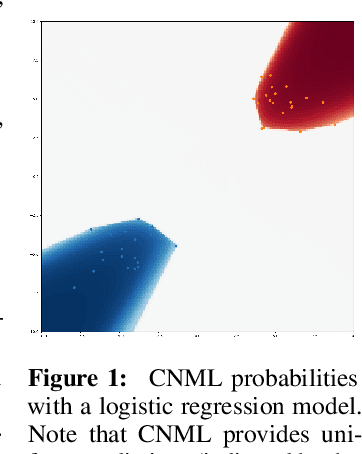
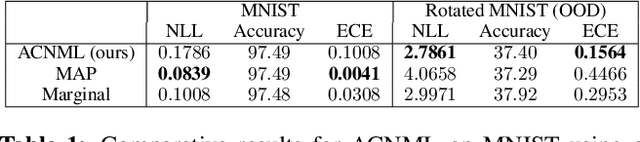
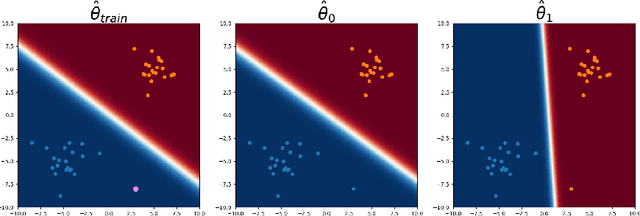
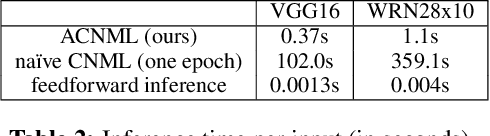
While deep neural networks provide good performance for a range of challenging tasks, calibration and uncertainty estimation remain major challenges. In this paper, we propose the amortized conditional normalized maximum likelihood (ACNML) method as a scalable general-purpose approach for uncertainty estimation, calibration, and out-of-distribution robustness with deep networks. Our algorithm builds on the conditional normalized maximum likelihood (CNML) coding scheme, which has minimax optimal properties according to the minimum description length principle, but is computationally intractable to evaluate exactly for all but the simplest of model classes. We propose to use approximate Bayesian inference technqiues to produce a tractable approximation to the CNML distribution. Our approach can be combined with any approximate inference algorithm that provides tractable posterior densities over model parameters. We demonstrate that ACNML compares favorably to a number of prior techniques for uncertainty estimation in terms of calibration on out-of-distribution inputs.
Conservative Q-Learning for Offline Reinforcement Learning
Jun 29, 2020


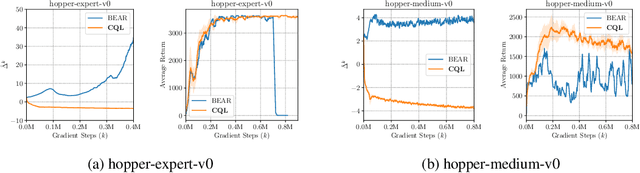
Effectively leveraging large, previously collected datasets in reinforcement learning (RL) is a key challenge for large-scale real-world applications. Offline RL algorithms promise to learn effective policies from previously-collected, static datasets without further interaction. However, in practice, offline RL presents a major challenge, and standard off-policy RL methods can fail due to overestimation of values induced by the distributional shift between the dataset and the learned policy, especially when training on complex and multi-modal data distributions. In this paper, we propose conservative Q-learning (CQL), which aims to address these limitations by learning a conservative Q-function such that the expected value of a policy under this Q-function lower-bounds its true value. We theoretically show that CQL produces a lower bound on the value of the current policy and that it can be incorporated into a principled policy improvement procedure. In practice, CQL augments the standard Bellman error objective with a simple Q-value regularizer which is straightforward to implement on top of existing deep Q-learning and actor-critic implementations. On both discrete and continuous control domains, we show that CQL substantially outperforms existing offline RL methods, often learning policies that attain 2-5 times higher final return, especially when learning from complex and multi-modal data distributions.
Learning to Walk via Deep Reinforcement Learning
Mar 25, 2019
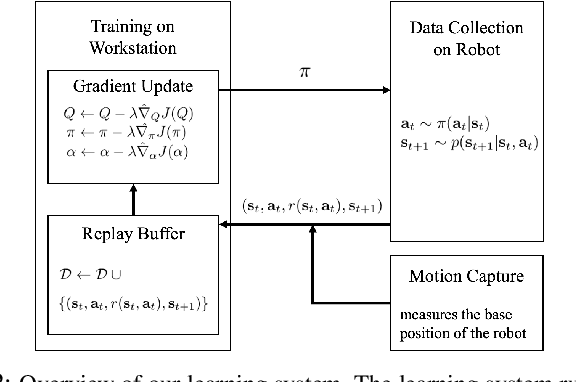
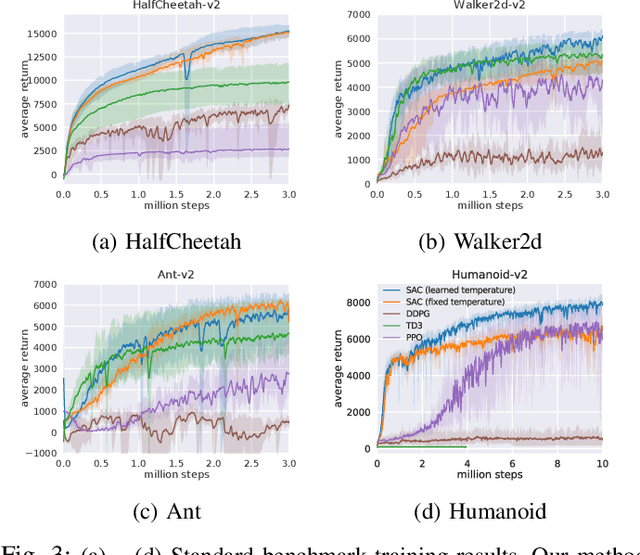
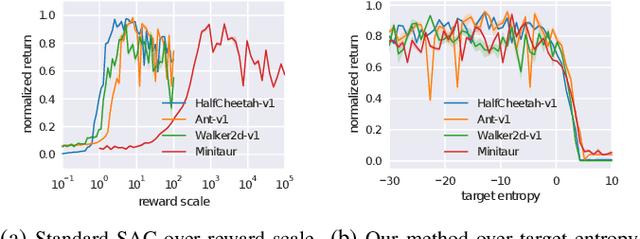
Deep reinforcement learning offers the promise of automatic acquisition of robotic control policies that directly map sensory inputs to low-level actions. In the domain of robotic locomotion, it could make it possible for locomotion skills to be learned with minimal engineering and without even needing to construct a model of the robot. However, applying deep reinforcement learning methods on real-world robots is exceptionally difficult, due both to the sample complexity and, just as importantly, the sensitivity of such methods to hyperparameters. While hyperparameter tuning can be performed in parallel in simulated domains, it is usually impractical to tune hyperparameters directly on real-world robotic platforms, especially legged platforms like quadrupedal robots that can be damaged through extensive trial-and-error learning. We develop a stable deep RL algorithm that extends soft actor-critic, requires minimal hyperparameter tuning, and requires only a modest number of trials to learn multilayer neural network policies. We then apply this method to learn walking gaits on a real-world Minitaur robot. Our method can learn to walk from scratch directly in the real world in two hours of training, without any model or simulation, and the resulting policy is robust to moderate variations in the environment. We further show that our algorithm achieves state-of-the-art performance on four standard simulated benchmarks.
Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables
Mar 19, 2019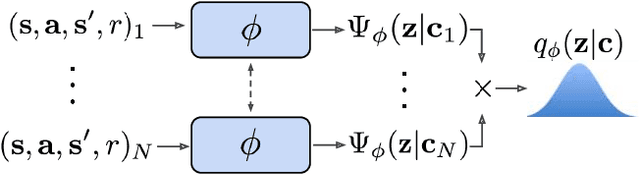
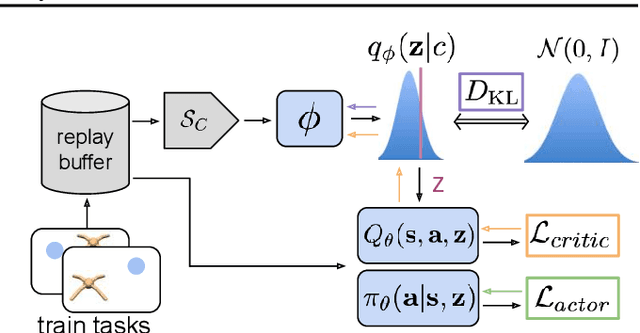
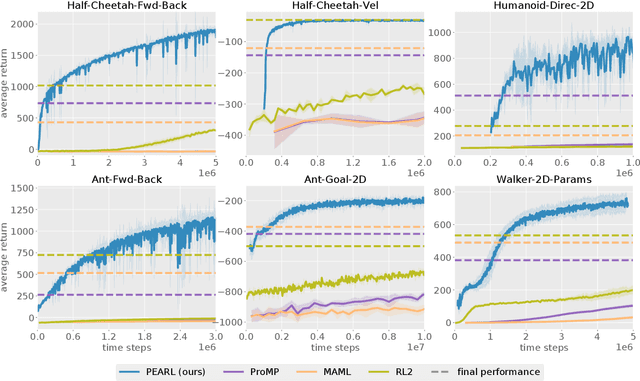
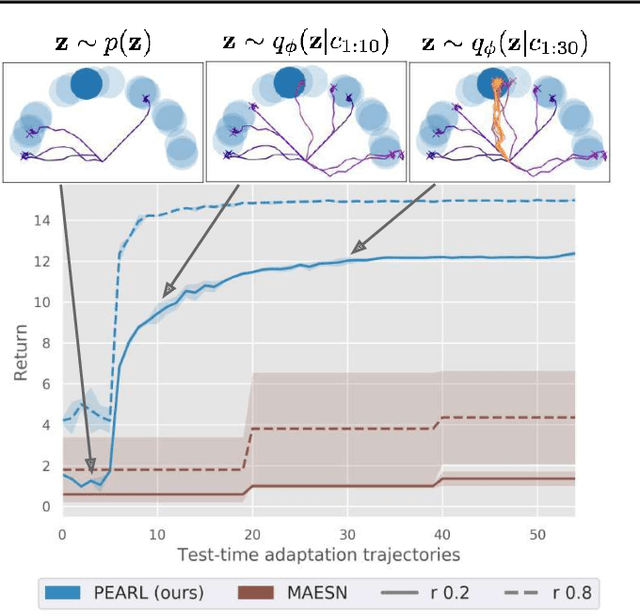
Deep reinforcement learning algorithms require large amounts of experience to learn an individual task. While in principle meta-reinforcement learning (meta-RL) algorithms enable agents to learn new skills from small amounts of experience, several major challenges preclude their practicality. Current methods rely heavily on on-policy experience, limiting their sample efficiency. The also lack mechanisms to reason about task uncertainty when adapting to new tasks, limiting their effectiveness in sparse reward problems. In this paper, we address these challenges by developing an off-policy meta-RL algorithm that disentangles task inference and control. In our approach, we perform online probabilistic filtering of latent task variables to infer how to solve a new task from small amounts of experience. This probabilistic interpretation enables posterior sampling for structured and efficient exploration. We demonstrate how to integrate these task variables with off-policy RL algorithms to achieve both meta-training and adaptation efficiency. Our method outperforms prior algorithms in sample efficiency by 20-100X as well as in asymptotic performance on several meta-RL benchmarks.
Soft Actor-Critic Algorithms and Applications
Jan 29, 2019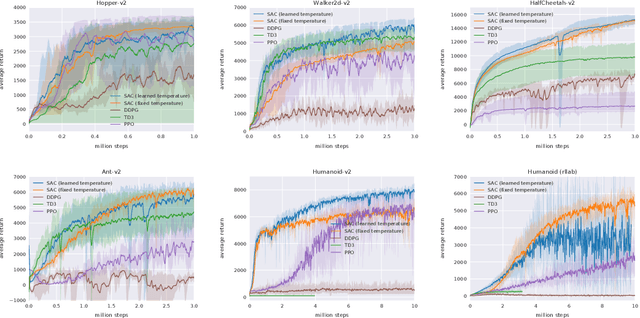



Model-free deep reinforcement learning (RL) algorithms have been successfully applied to a range of challenging sequential decision making and control tasks. However, these methods typically suffer from two major challenges: high sample complexity and brittleness to hyperparameters. Both of these challenges limit the applicability of such methods to real-world domains. In this paper, we describe Soft Actor-Critic (SAC), our recently introduced off-policy actor-critic algorithm based on the maximum entropy RL framework. In this framework, the actor aims to simultaneously maximize expected return and entropy. That is, to succeed at the task while acting as randomly as possible. We extend SAC to incorporate a number of modifications that accelerate training and improve stability with respect to the hyperparameters, including a constrained formulation that automatically tunes the temperature hyperparameter. We systematically evaluate SAC on a range of benchmark tasks, as well as real-world challenging tasks such as locomotion for a quadrupedal robot and robotic manipulation with a dexterous hand. With these improvements, SAC achieves state-of-the-art performance, outperforming prior on-policy and off-policy methods in sample-efficiency and asymptotic performance. Furthermore, we demonstrate that, in contrast to other off-policy algorithms, our approach is very stable, achieving similar performance across different random seeds. These results suggest that SAC is a promising candidate for learning in real-world robotics tasks.
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Aug 08, 2018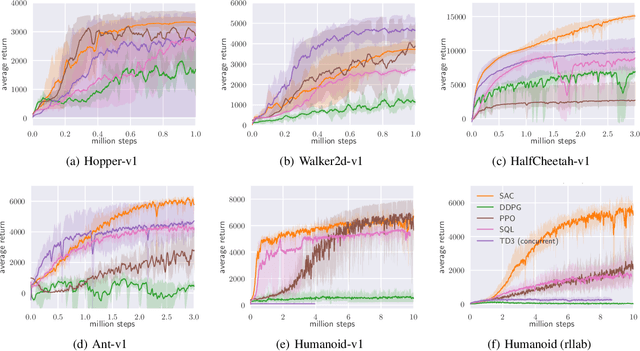

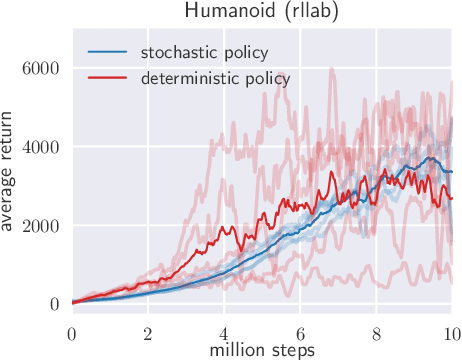

Model-free deep reinforcement learning (RL) algorithms have been demonstrated on a range of challenging decision making and control tasks. However, these methods typically suffer from two major challenges: very high sample complexity and brittle convergence properties, which necessitate meticulous hyperparameter tuning. Both of these challenges severely limit the applicability of such methods to complex, real-world domains. In this paper, we propose soft actor-critic, an off-policy actor-critic deep RL algorithm based on the maximum entropy reinforcement learning framework. In this framework, the actor aims to maximize expected reward while also maximizing entropy. That is, to succeed at the task while acting as randomly as possible. Prior deep RL methods based on this framework have been formulated as Q-learning methods. By combining off-policy updates with a stable stochastic actor-critic formulation, our method achieves state-of-the-art performance on a range of continuous control benchmark tasks, outperforming prior on-policy and off-policy methods. Furthermore, we demonstrate that, in contrast to other off-policy algorithms, our approach is very stable, achieving very similar performance across different random seeds.