 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Mutual-Information Representation Learning Objectives are Sufficient for Control?
Jun 14, 2021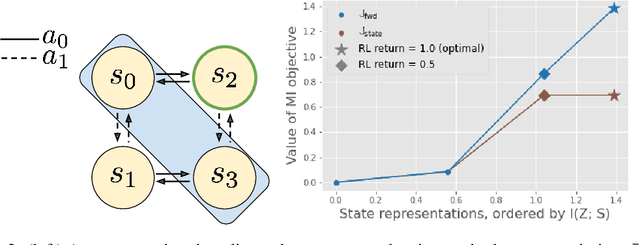
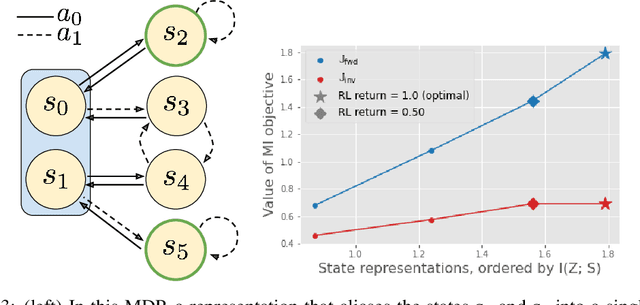
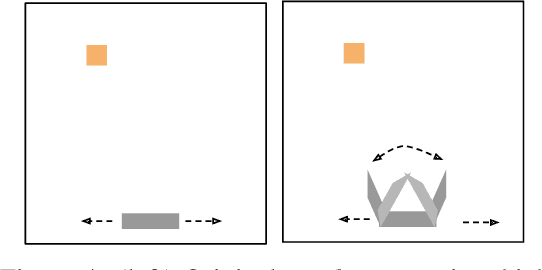
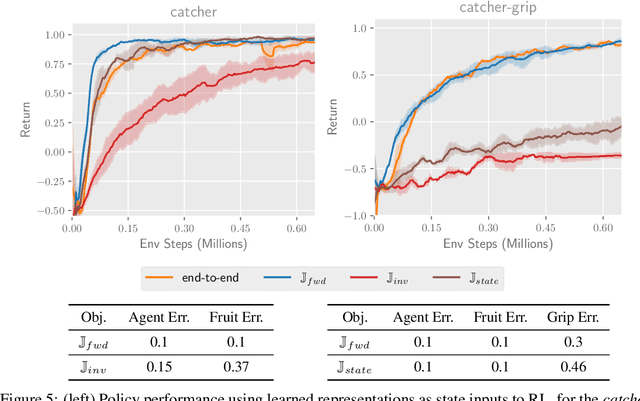
Mutual information maximization provides an appealing formalism for learning representations of data. In the context of reinforcement learning (RL), such representations can accelerate learning by discarding irrelevant and redundant information, while retaining the information necessary for control. Much of the prior work on these methods has addressed the practical difficulties of estimating mutual information from samples of high-dimensional observations, while comparatively less is understood about which mutual information objectives yield representations that are sufficient for RL from a theoretical perspective. In this paper, we formalize the sufficiency of a state representation for learning and representing the optimal policy, and study several popular mutual-information based objectives through this lens. Surprisingly, we find that two of these objectives can yield insufficient representations given mild and common assumptions on the structure of the MDP. We corroborate our theoretical results with empirical experiments on a simulated game environment with visual observations.
MELD: Meta-Reinforcement Learning from Images via Latent State Models
Oct 26, 2020
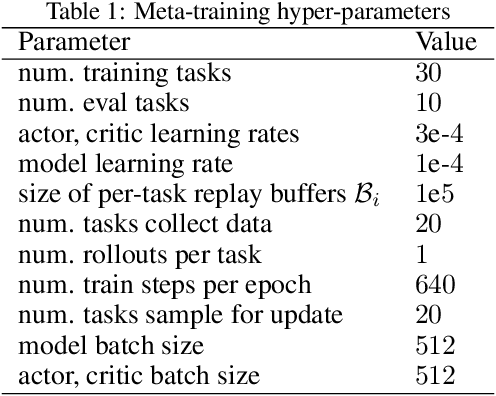
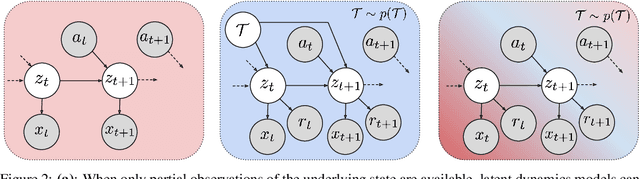
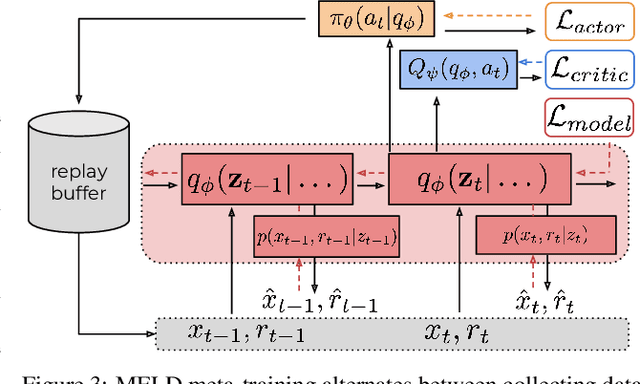
Meta-reinforcement learning algorithms can enable autonomous agents, such as robots, to quickly acquire new behaviors by leveraging prior experience in a set of related training tasks. However, the onerous data requirements of meta-training compounded with the challenge of learning from sensory inputs such as images have made meta-RL challenging to apply to real robotic systems. Latent state models, which learn compact state representations from a sequence of observations, can accelerate representation learning from visual inputs. In this paper, we leverage the perspective of meta-learning as task inference to show that latent state models can \emph{also} perform meta-learning given an appropriately defined observation space. Building on this insight, we develop meta-RL with latent dynamics (MELD), an algorithm for meta-RL from images that performs inference in a latent state model to quickly acquire new skills given observations and rewards. MELD outperforms prior meta-RL methods on several simulated image-based robotic control problems, and enables a real WidowX robotic arm to insert an Ethernet cable into new locations given a sparse task completion signal after only $8$ hours of real world meta-training. To our knowledge, MELD is the first meta-RL algorithm trained in a real-world robotic control setting from images.
Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables
Mar 19, 2019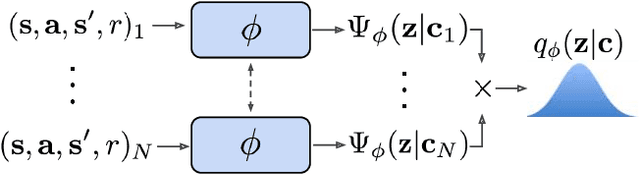
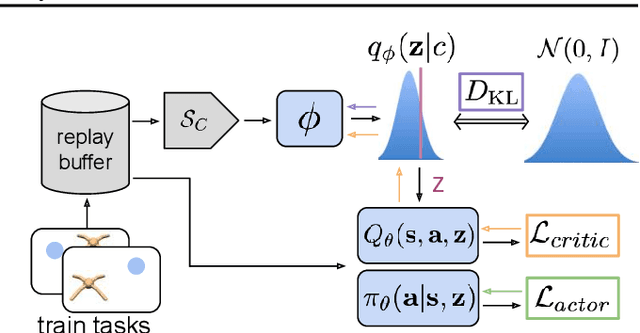
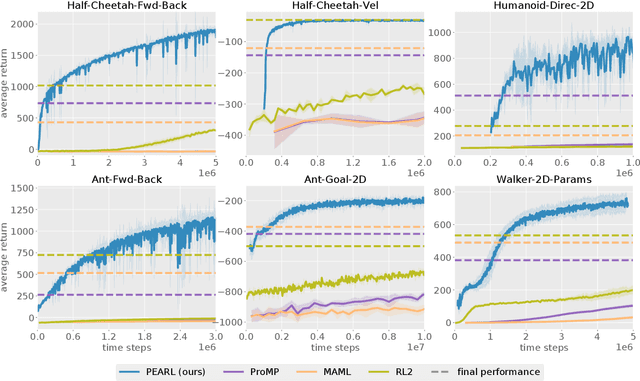
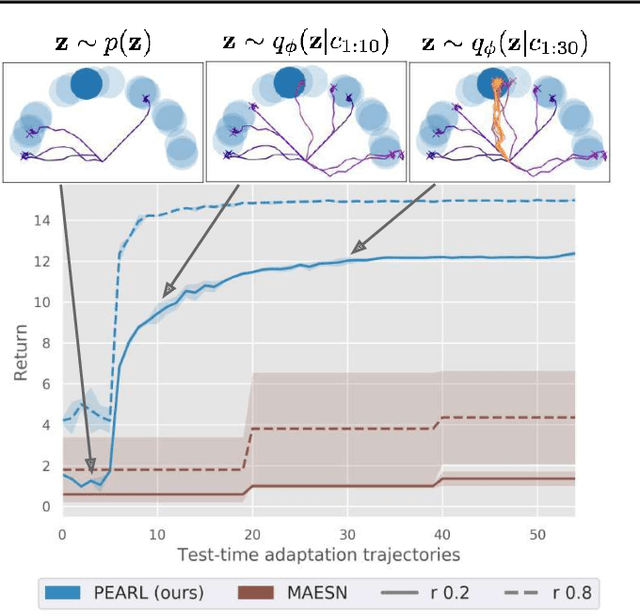
Deep reinforcement learning algorithms require large amounts of experience to learn an individual task. While in principle meta-reinforcement learning (meta-RL) algorithms enable agents to learn new skills from small amounts of experience, several major challenges preclude their practicality. Current methods rely heavily on on-policy experience, limiting their sample efficiency. The also lack mechanisms to reason about task uncertainty when adapting to new tasks, limiting their effectiveness in sparse reward problems. In this paper, we address these challenges by developing an off-policy meta-RL algorithm that disentangles task inference and control. In our approach, we perform online probabilistic filtering of latent task variables to infer how to solve a new task from small amounts of experience. This probabilistic interpretation enables posterior sampling for structured and efficient exploration. We demonstrate how to integrate these task variables with off-policy RL algorithms to achieve both meta-training and adaptation efficiency. Our method outperforms prior algorithms in sample efficiency by 20-100X as well as in asymptotic performance on several meta-RL benchmarks.
Few-Shot Segmentation Propagation with Guided Networks
May 25, 2018

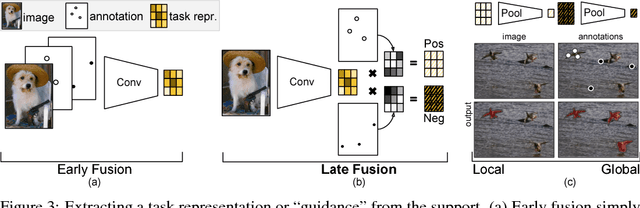

Learning-based methods for visual segmentation have made progress on particular types of segmentation tasks, but are limited by the necessary supervision, the narrow definitions of fixed tasks, and the lack of control during inference for correcting errors. To remedy the rigidity and annotation burden of standard approaches, we address the problem of few-shot segmentation: given few image and few pixel supervision, segment any images accordingly. We propose guided networks, which extract a latent task representation from any amount of supervision, and optimize our architecture end-to-end for fast, accurate few-shot segmentation. Our method can switch tasks without further optimization and quickly update when given more guidance. We report the first results for segmentation from one pixel per concept and show real-time interactive video segmentation. Our unified approach propagates pixel annotations across space for interactive segmentation, across time for video segmentation, and across scenes for semantic segmentation. Our guided segmentor is state-of-the-art in accuracy for the amount of annotation and time. See http://github.com/shelhamer/revolver for code, models, and more details.
Clockwork Convnets for Video Semantic Segmentation
Aug 11, 2016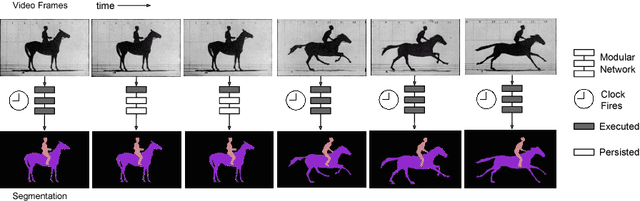
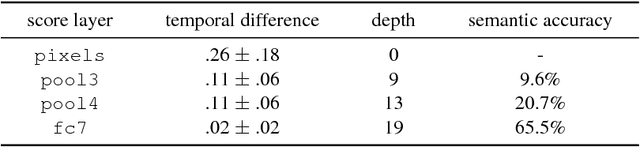
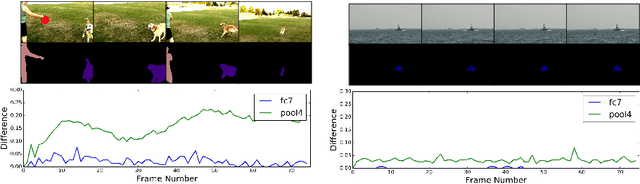
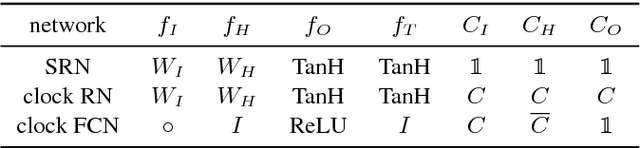
Recent years have seen tremendous progress in still-image segmentation; however the na\"ive application of these state-of-the-art algorithms to every video frame requires considerable computation and ignores the temporal continuity inherent in video. We propose a video recognition framework that relies on two key observations: 1) while pixels may change rapidly from frame to frame, the semantic content of a scene evolves more slowly, and 2) execution can be viewed as an aspect of architecture, yielding purpose-fit computation schedules for networks. We define a novel family of "clockwork" convnets driven by fixed or adaptive clock signals that schedule the processing of different layers at different update rates according to their semantic stability. We design a pipeline schedule to reduce latency for real-time recognition and a fixed-rate schedule to reduce overall computation. Finally, we extend clockwork scheduling to adaptive video processing by incorporating data-driven clocks that can be tuned on unlabeled video. The accuracy and efficiency of clockwork convnets are evaluated on the Youtube-Objects, NYUD, and Cityscapes video datasets.
A Century of Portraits: A Visual Historical Record of American High School Yearbooks
Nov 09, 2015
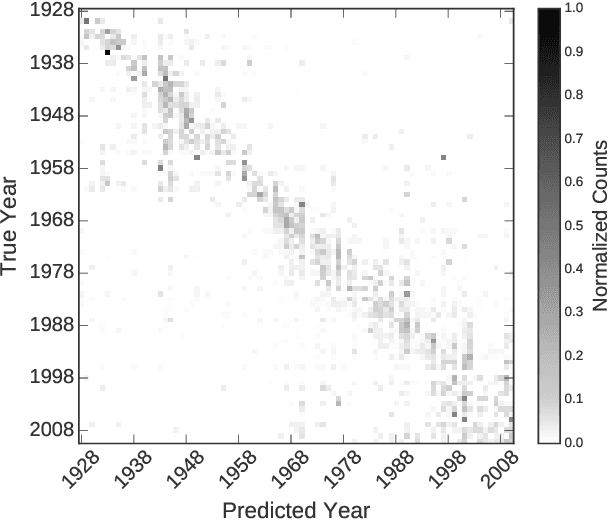


Many details about our world are not captured in written records because they are too mundane or too abstract to describe in words. Fortunately, since the invention of the camera, an ever-increasing number of photographs capture much of this otherwise lost information. This plethora of artifacts documenting our "visual culture" is a treasure trove of knowledge as yet untapped by historians. We present a dataset of 37,921 frontal-facing American high school yearbook photos that allow us to use computation to glimpse into the historical visual record too voluminous to be evaluated manually. The collected portraits provide a constant visual frame of reference with varying content. We can therefore use them to consider issues such as a decade's defining style elements, or trends in fashion and social norms over time. We demonstrate that our historical image dataset may be used together with weakly-supervised data-driven techniques to perform scalable historical analysis of large image corpora with minimal human effort, much in the same way that large text corpora together with natural language processing revolutionized historians' workflow. Furthermore, we demonstrate the use of our dataset in dating grayscale portraits using deep learning methods.