 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFS: Reinforcement learning with Residual flow steering for dexterous manipulation
Feb 03, 2026Imitation learning has emerged as an effective approach for bootstrapping sequential decision-making in robotics, achieving strong performance even in high-dimensional dexterous manipulation tasks. Recent behavior cloning methods further leverage expressive generative models, such as diffusion models and flow matching, to represent multimodal action distributions. However, policies pretrained in this manner often exhibit limited generalization and require additional fine-tuning to achieve robust performance at deployment time. Such adaptation must preserve the global exploration benefits of pretraining while enabling rapid correction of local execution errors. We propose Residual Flow Steering(RFS), a data-efficient reinforcement learning framework for adapting pretrained generative policies. RFS steers a pretrained flow-matching policy by jointly optimizing a residual action and a latent noise distribution, enabling complementary forms of exploration: local refinement through residual corrections and global exploration through latent-space modulation. This design allows efficient adaptation while retaining the expressive structure of the pretrained policy. We demonstrate the effectiveness of RFS on dexterous manipulation tasks, showing efficient fine-tuning in both simulation and real-world settings when adapting pretrained base policies. Project website:https://weirdlabuw.github.io/rfs.
Model-Based Reinforcement Learning via Latent-Space Collocation
Jun 24, 2021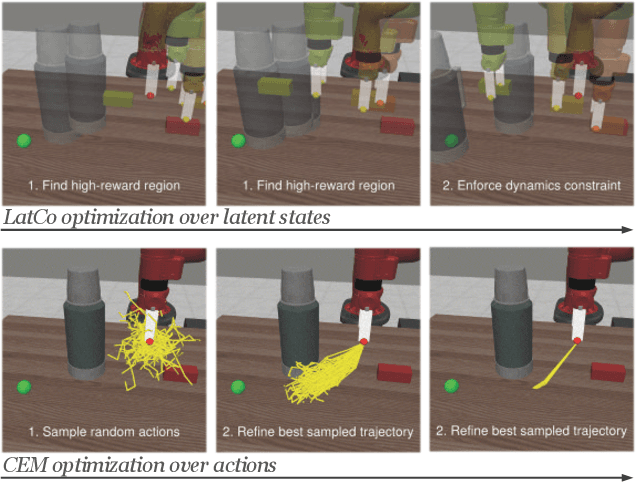
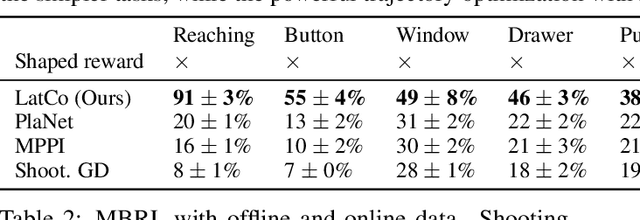
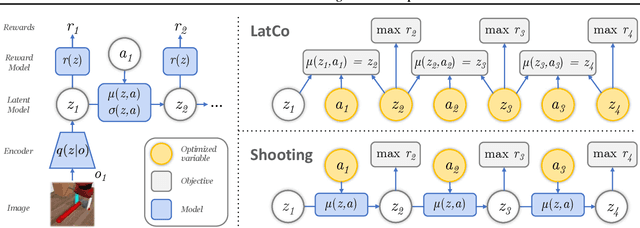

The ability to plan into the future while utilizing only raw high-dimensional observations, such as images, can provide autonomous agents with broad capabilities. Visual model-based reinforcement learning (RL) methods that plan future actions directly have shown impressive results on tasks that require only short-horizon reasoning, however, these methods struggle on temporally extended tasks. We argue that it is easier to solve long-horizon tasks by planning sequences of states rather than just actions, as the effects of actions greatly compound over time and are harder to optimize. To achieve this, we draw on the idea of collocation, which has shown good results on long-horizon tasks in optimal control literature, and adapt it to the image-based setting by utilizing learned latent state space models. The resulting latent collocation method (LatCo) optimizes trajectories of latent states, which improves over previously proposed shooting methods for visual model-based RL on tasks with sparse rewards and long-term goals. Videos and code at https://orybkin.github.io/latco/.
MELD: Meta-Reinforcement Learning from Images via Latent State Models
Oct 26, 2020
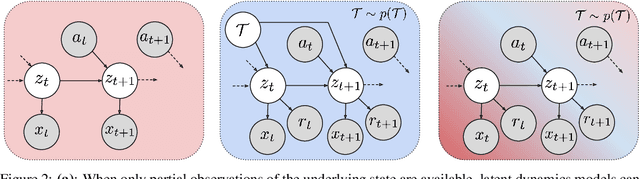
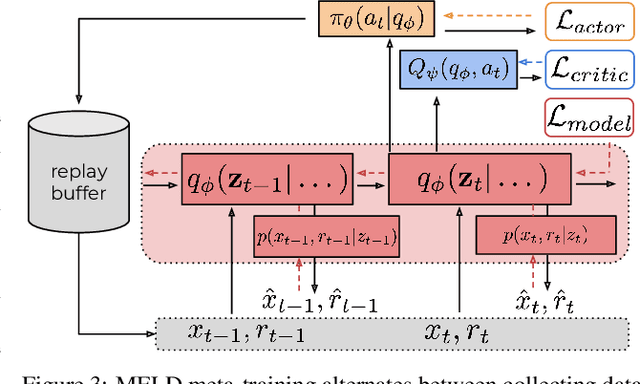
Meta-reinforcement learning algorithms can enable autonomous agents, such as robots, to quickly acquire new behaviors by leveraging prior experience in a set of related training tasks. However, the onerous data requirements of meta-training compounded with the challenge of learning from sensory inputs such as images have made meta-RL challenging to apply to real robotic systems. Latent state models, which learn compact state representations from a sequence of observations, can accelerate representation learning from visual inputs. In this paper, we leverage the perspective of meta-learning as task inference to show that latent state models can \emph{also} perform meta-learning given an appropriately defined observation space. Building on this insight, we develop meta-RL with latent dynamics (MELD), an algorithm for meta-RL from images that performs inference in a latent state model to quickly acquire new skills given observations and rewards. MELD outperforms prior meta-RL methods on several simulated image-based robotic control problems, and enables a real WidowX robotic arm to insert an Ethernet cable into new locations given a sparse task completion signal after only $8$ hours of real world meta-training. To our knowledge, MELD is the first meta-RL algorithm trained in a real-world robotic control setting from images.
Deep Dynamics Models for Learning Dexterous Manipulation
Sep 25, 2019

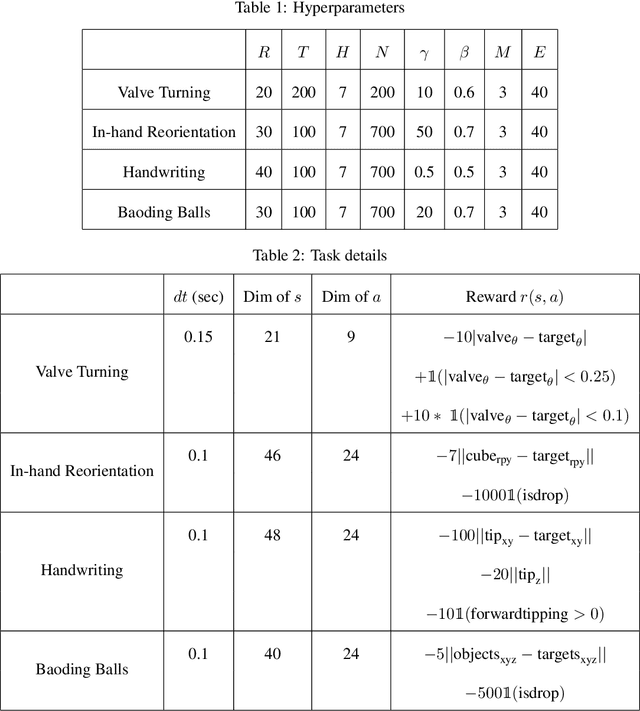

Dexterous multi-fingered hands can provide robots with the ability to flexibly perform a wide range of manipulation skills. However, many of the more complex behaviors are also notoriously difficult to control: Performing in-hand object manipulation, executing finger gaits to move objects, and exhibiting precise fine motor skills such as writing, all require finely balancing contact forces, breaking and reestablishing contacts repeatedly, and maintaining control of unactuated objects. Learning-based techniques provide the appealing possibility of acquiring these skills directly from data, but current learning approaches either require large amounts of data and produce task-specific policies, or they have not yet been shown to scale up to more complex and realistic tasks requiring fine motor skills. In this work, we demonstrate that our method of online planning with deep dynamics models (PDDM) addresses both of these limitations; we show that improvements in learned dynamics models, together with improvements in online model-predictive control, can indeed enable efficient and effective learning of flexible contact-rich dexterous manipulation skills -- and that too, on a 24-DoF anthropomorphic hand in the real world, using just 4 hours of purely real-world data to learn to simultaneously coordinate multiple free-floating objects. Videos can be found at https://sites.google.com/view/pddm/
Stochastic Latent Actor-Critic: Deep Reinforcement Learning with a Latent Variable Model
Jul 01, 2019
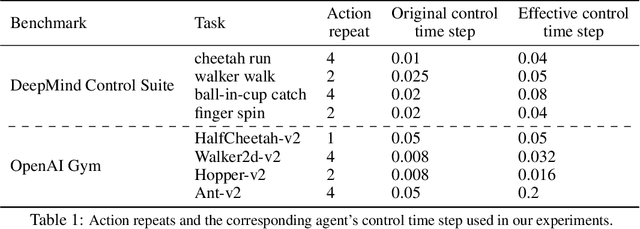

Deep reinforcement learning (RL) algorithms can use high-capacity deep networks to learn directly from image observations. However, these kinds of observation spaces present a number of challenges in practice, since the policy must now solve two problems: a representation learning problem, and a task learning problem. In this paper, we aim to explicitly learn representations that can accelerate reinforcement learning from images. We propose the stochastic latent actor-critic (SLAC) algorithm: a sample-efficient and high-performing RL algorithm for learning policies for complex continuous control tasks directly from high-dimensional image inputs. SLAC learns a compact latent representation space using a stochastic sequential latent variable model, and then learns a critic model within this latent space. By learning a critic within a compact state space, SLAC can learn much more efficiently than standard RL methods. The proposed model improves performance substantially over alternative representations as well, such as variational autoencoders. In fact, our experimental evaluation demonstrates that the sample efficiency of our resulting method is comparable to that of model-based RL methods that directly use a similar type of model for control. Furthermore, our method outperforms both model-free and model-based alternatives in terms of final performance and sample efficiency, on a range of difficult image-based control tasks.
Learning to Adapt in Dynamic, Real-World Environments Through Meta-Reinforcement Learning
Feb 27, 2019
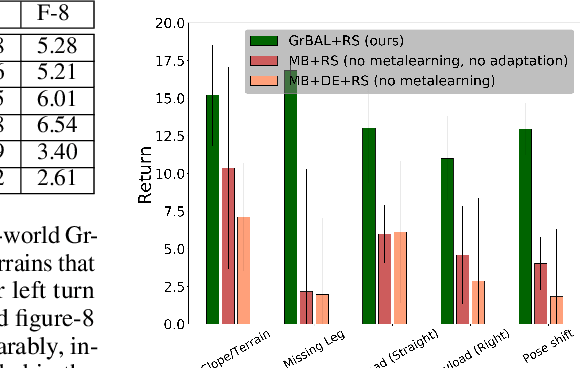


Although reinforcement learning methods can achieve impressive results in simulation, the real world presents two major challenges: generating samples is exceedingly expensive, and unexpected perturbations or unseen situations cause proficient but specialized policies to fail at test time. Given that it is impractical to train separate policies to accommodate all situations the agent may see in the real world, this work proposes to learn how to quickly and effectively adapt online to new tasks. To enable sample-efficient learning, we consider learning online adaptation in the context of model-based reinforcement learning. Our approach uses meta-learning to train a dynamics model prior such that, when combined with recent data, this prior can be rapidly adapted to the local context. Our experiments demonstrate online adaptation for continuous control tasks on both simulated and real-world agents. We first show simulated agents adapting their behavior online to novel terrains, crippled body parts, and highly-dynamic environments. We also illustrate the importance of incorporating online adaptation into autonomous agents that operate in the real world by applying our method to a real dynamic legged millirobot. We demonstrate the agent's learned ability to quickly adapt online to a missing leg, adjust to novel terrains and slopes, account for miscalibration or errors in pose estimation, and compensate for pulling payloads.
Deep Online Learning via Meta-Learning: Continual Adaptation for Model-Based RL
Jan 28, 2019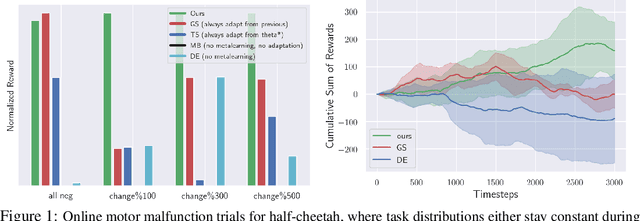

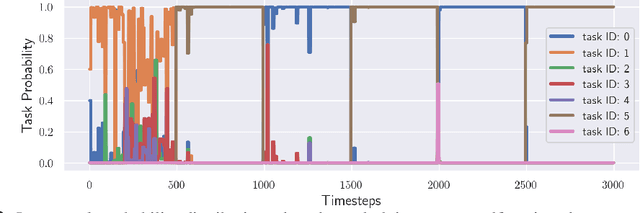
Humans and animals can learn complex predictive models that allow them to accurately and reliably reason about real-world phenomena, and they can adapt such models extremely quickly in the face of unexpected changes. Deep neural network models allow us to represent very complex functions, but lack this capacity for rapid online adaptation. The goal in this paper is to develop a method for continual online learning from an incoming stream of data, using deep neural network models. We formulate an online learning procedure that uses stochastic gradient descent to update model parameters, and an expectation maximization algorithm with a Chinese restaurant process prior to develop and maintain a mixture of models to handle non-stationary task distributions. This allows for all models to be adapted as necessary, with new models instantiated for task changes and old models recalled when previously seen tasks are encountered again. Furthermore, we observe that meta-learning can be used to meta-train a model such that this direct online adaptation with SGD is effective, which is otherwise not the case for large function approximators. In this work, we apply our meta-learning for online learning (MOLe) approach to model-based reinforcement learning, where adapting the predictive model is critical for control; we demonstrate that MOLe outperforms alternative prior methods, and enables effective continuous adaptation in non-stationary task distributions such as varying terrains, motor failures, and unexpected disturbances.
Learning Image-Conditioned Dynamics Models for Control of Under-actuated Legged Millirobots
Mar 30, 2018
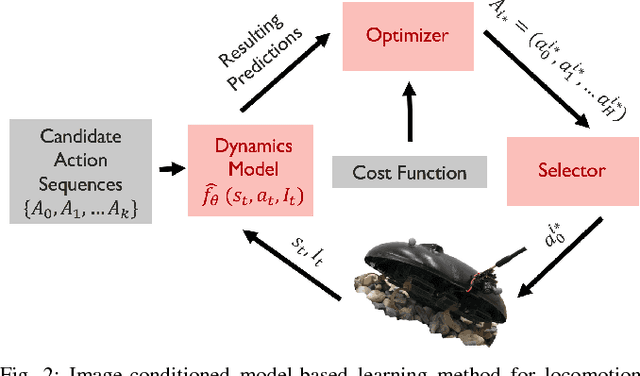


Millirobots are a promising robotic platform for many applications due to their small size and low manufacturing costs. Legged millirobots, in particular, can provide increased mobility in complex environments and improved scaling of obstacles. However, controlling these small, highly dynamic, and underactuated legged systems is difficult. Hand-engineered controllers can sometimes control these legged millirobots, but they have difficulties with dynamic maneuvers and complex terrains. We present an approach for controlling a real-world legged millirobot that is based on learned neural network models. Using less than 17 minutes of data, our method can learn a predictive model of the robot's dynamics that can enable effective gaits to be synthesized on the fly for following user-specified waypoints on a given terrain. Furthermore, by leveraging expressive, high-capacity neural network models, our approach allows for these predictions to be directly conditioned on camera images, endowing the robot with the ability to predict how different terrains might affect its dynamics. This enables sample-efficient and effective learning for locomotion of a dynamic legged millirobot on various terrains, including gravel, turf, carpet, and styrofoam. Experiment videos can be found at https://sites.google.com/view/imageconddyn
Expressive Robot Motion Timing
Feb 05, 2018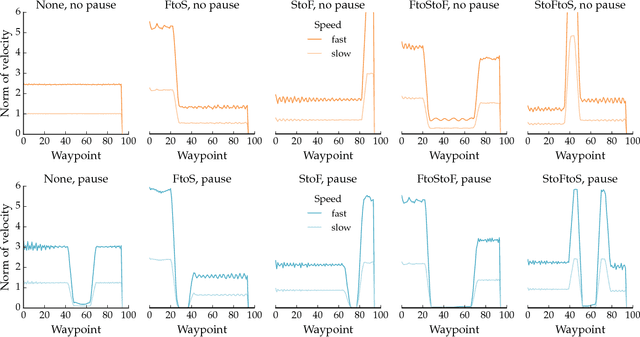
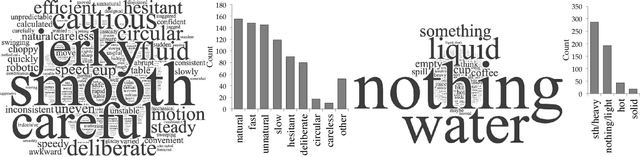
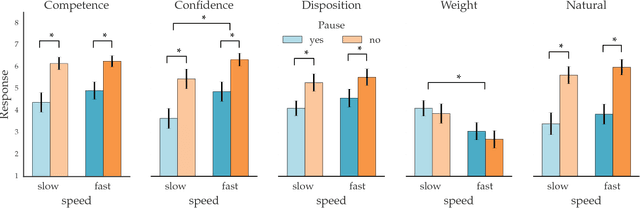
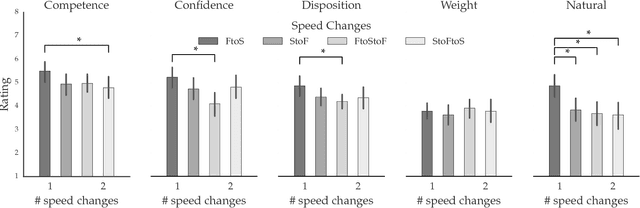
Our goal is to enable robots to \emph{time} their motion in a way that is purposefully expressive of their internal states, making them more transparent to people. We start by investigating what types of states motion timing is capable of expressing, focusing on robot manipulation and keeping the path constant while systematically varying the timing. We find that users naturally pick up on certain properties of the robot (like confidence), of the motion (like naturalness), or of the task (like the weight of the object that the robot is carrying). We then conduct a hypothesis-driven experiment to tease out the directions and magnitudes of these effects, and use our findings to develop candidate mathematical models for how users make these inferences from the timing. We find a strong correlation between the models and real user data, suggesting that robots can leverage these models to autonomously optimize the timing of their motion to be expressive.
Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning
Dec 02, 2017
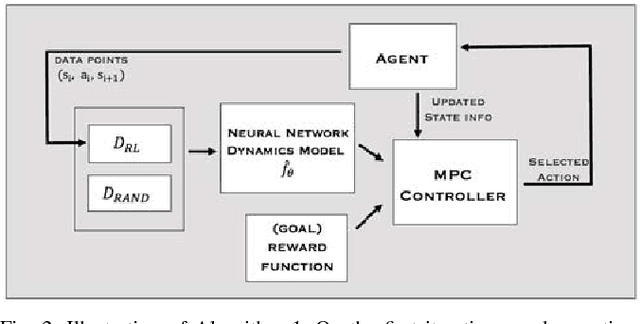
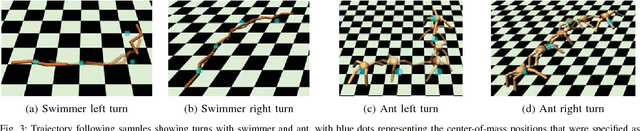

Model-free deep reinforcement learning algorithms have been shown to be capable of learning a wide range of robotic skills, but typically require a very large number of samples to achieve good performance. Model-based algorithms, in principle, can provide for much more efficient learning, but have proven difficult to extend to expressive, high-capacity models such as deep neural networks. In this work, we demonstrate that medium-sized neural network models can in fact be combined with model predictive control (MPC) to achieve excellent sample complexity in a model-based reinforcement learning algorithm, producing stable and plausible gaits to accomplish various complex locomotion tasks. We also propose using deep neural network dynamics models to initialize a model-free learner, in order to combine the sample efficiency of model-based approaches with the high task-specific performance of model-free methods. We empirically demonstrate on MuJoCo locomotion tasks that our pure model-based approach trained on just random action data can follow arbitrary trajectories with excellent sample efficiency, and that our hybrid algorithm can accelerate model-free learning on high-speed benchmark tasks, achieving sample efficiency gains of 3-5x on swimmer, cheetah, hopper, and ant agents. Videos can be found at https://sites.google.com/view/mbmf