 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Multi-Robot Deep Reinforcement Learning for Mobile Navigation
Jun 24, 2021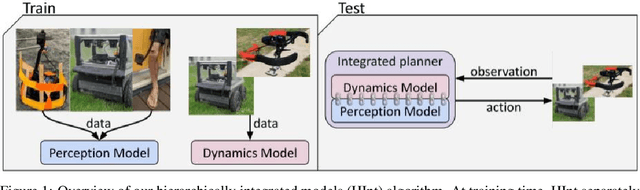
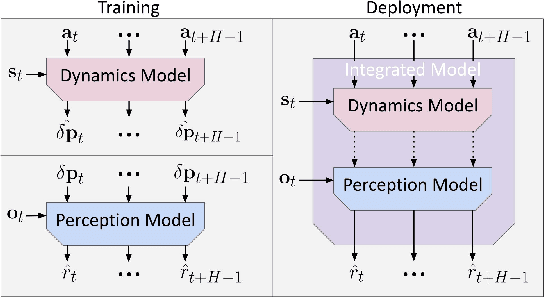

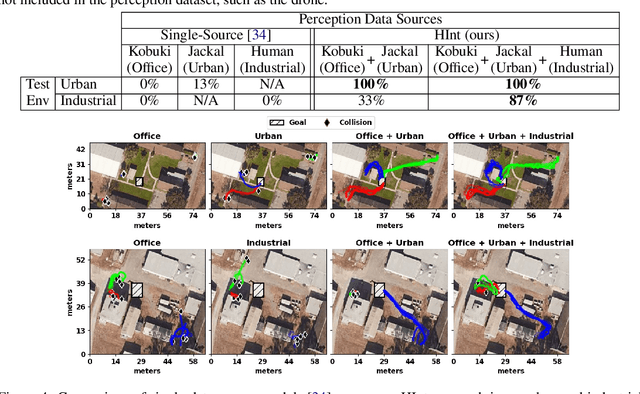
Deep reinforcement learning algorithms require large and diverse datasets in order to learn successful policies for perception-based mobile navigation. However, gathering such datasets with a single robot can be prohibitively expensive. Collecting data with multiple different robotic platforms with possibly different dynamics is a more scalable approach to large-scale data collection. But how can deep reinforcement learning algorithms leverage such heterogeneous datasets? In this work, we propose a deep reinforcement learning algorithm with hierarchically integrated models (HInt). At training time, HInt learns separate perception and dynamics models, and at test time, HInt integrates the two models in a hierarchical manner and plans actions with the integrated model. This method of planning with hierarchically integrated models allows the algorithm to train on datasets gathered by a variety of different platforms, while respecting the physical capabilities of the deployment robot at test time. Our mobile navigation experiments show that HInt outperforms conventional hierarchical policies and single-source approaches.
ViNG: Learning Open-World Navigation with Visual Goals
Dec 17, 2020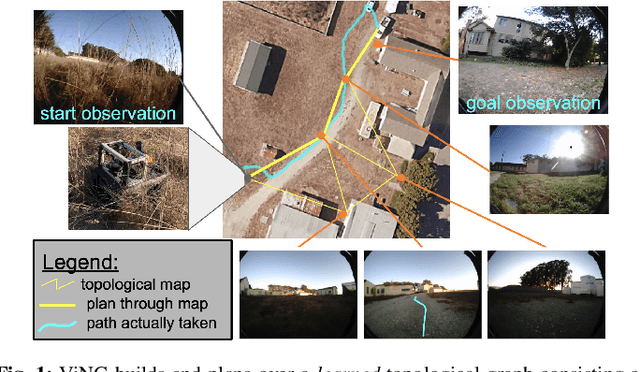

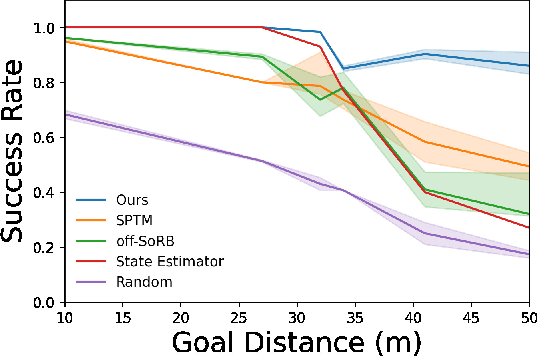
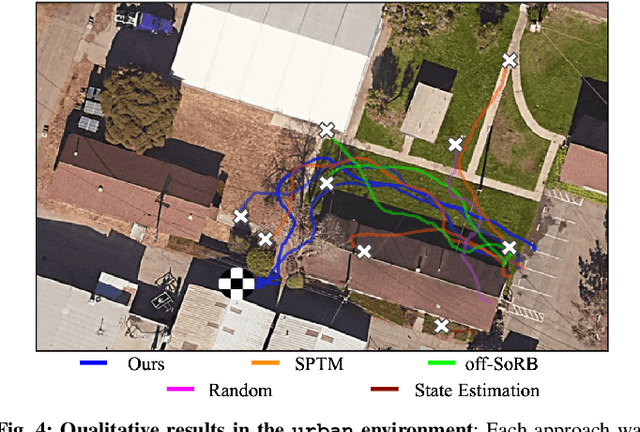
We propose a learning-based navigation system for reaching visually indicated goals and demonstrate this system on a real mobile robot platform. Learning provides an appealing alternative to conventional methods for robotic navigation: instead of reasoning about environments in terms of geometry and maps, learning can enable a robot to learn about navigational affordances, understand what types of obstacles are traversable (e.g., tall grass) or not (e.g., walls), and generalize over patterns in the environment. However, unlike conventional planning algorithms, it is harder to change the goal for a learned policy during deployment. We propose a method for learning to navigate towards a goal image of the desired destination. By combining a learned policy with a topological graph constructed out of previously observed data, our system can determine how to reach this visually indicated goal even in the presence of variable appearance and lighting. Three key insights, waypoint proposal, graph pruning and negative mining, enable our method to learn to navigate in real-world environments using only offline data, a setting where prior methods struggle. We instantiate our method on a real outdoor ground robot and show that our system, which we call ViNG, outperforms previously-proposed methods for goal-conditioned reinforcement learning, including other methods that incorporate reinforcement learning and search. We also study how ViNG generalizes to unseen environments and evaluate its ability to adapt to such an environment with growing experience. Finally, we demonstrate ViNG on a number of real-world applications, such as last-mile delivery and warehouse inspection. We encourage the reader to check out the videos of our experiments and demonstrations at our project website https://sites.google.com/view/ving-robot
LaND: Learning to Navigate from Disengagements
Oct 09, 2020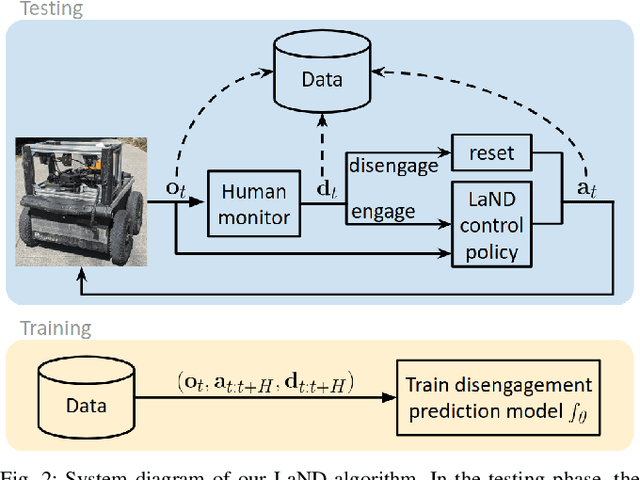

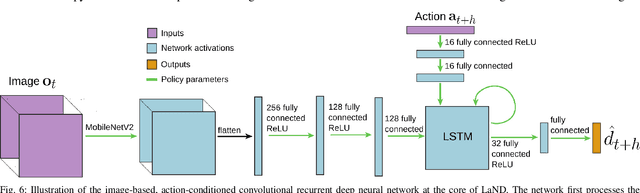
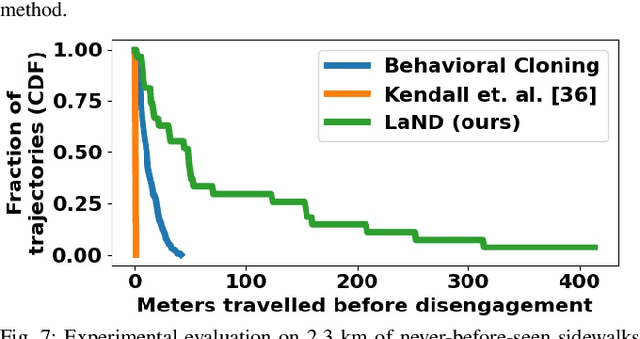
Consistently testing autonomous mobile robots in real world scenarios is a necessary aspect of developing autonomous navigation systems. Each time the human safety monitor disengages the robot's autonomy system due to the robot performing an undesirable maneuver, the autonomy developers gain insight into how to improve the autonomy system. However, we believe that these disengagements not only show where the system fails, which is useful for troubleshooting, but also provide a direct learning signal by which the robot can learn to navigate. We present a reinforcement learning approach for learning to navigate from disengagements, or LaND. LaND learns a neural network model that predicts which actions lead to disengagements given the current sensory observation, and then at test time plans and executes actions that avoid disengagements. Our results demonstrate LaND can successfully learn to navigate in diverse, real world sidewalk environments, outperforming both imitation learning and reinforcement learning approaches. Videos, code, and other material are available on our website https://sites.google.com/view/sidewalk-learning
Model-Based Meta-Reinforcement Learning for Flight with Suspended Payloads
Apr 23, 2020
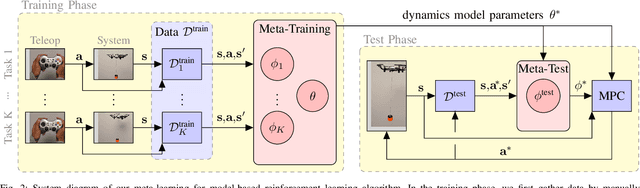
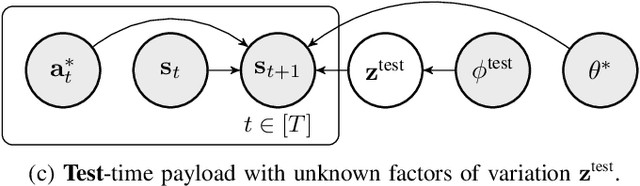

Transporting suspended payloads is challenging for autonomous aerial vehicles because the payload can cause significant and unpredictable changes to the robot's dynamics. These changes can lead to suboptimal flight performance or even catastrophic failure. Although adaptive control and learning-based methods can in principle adapt to changes in these hybrid robot-payload systems, rapid mid-flight adaptation to payloads that have a priori unknown physical properties remains an open problem. We propose a meta-learning approach that "learns how to learn" models of altered dynamics within seconds of post-connection flight data. Our experiments demonstrate that our online adaptation approach outperforms non-adaptive methods on a series of challenging suspended payload transportation tasks. Videos and other supplemental material are available on our website https://sites.google.com/view/meta-rl-for-flight
BADGR: An Autonomous Self-Supervised Learning-Based Navigation System
Feb 13, 2020


Mobile robot navigation is typically regarded as a geometric problem, in which the robot's objective is to perceive the geometry of the environment in order to plan collision-free paths towards a desired goal. However, a purely geometric view of the world can can be insufficient for many navigation problems. For example, a robot navigating based on geometry may avoid a field of tall grass because it believes it is untraversable, and will therefore fail to reach its desired goal. In this work, we investigate how to move beyond these purely geometric-based approaches using a method that learns about physical navigational affordances from experience. Our approach, which we call BADGR, is an end-to-end learning-based mobile robot navigation system that can be trained with self-supervised off-policy data gathered in real-world environments, without any simulation or human supervision. BADGR can navigate in real-world urban and off-road environments with geometrically distracting obstacles. It can also incorporate terrain preferences, generalize to novel environments, and continue to improve autonomously by gathering more data. Videos, code, and other supplemental material are available on our website https://sites.google.com/view/badgr
Generalization through Simulation: Integrating Simulated and Real Data into Deep Reinforcement Learning for Vision-Based Autonomous Flight
Feb 11, 2019
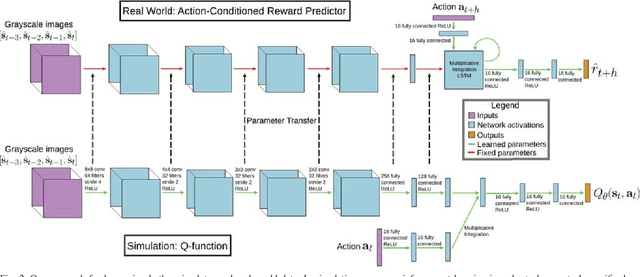

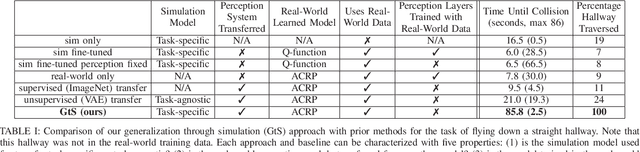
Deep reinforcement learning provides a promising approach for vision-based control of real-world robots. However, the generalization of such models depends critically on the quantity and variety of data available for training. This data can be difficult to obtain for some types of robotic systems, such as fragile, small-scale quadrotors. Simulated rendering and physics can provide for much larger datasets, but such data is inherently of lower quality: many of the phenomena that make the real-world autonomous flight problem challenging, such as complex physics and air currents, are modeled poorly or not at all, and the systematic differences between simulation and the real world are typically impossible to eliminate. In this work, we investigate how data from both simulation and the real world can be combined in a hybrid deep reinforcement learning algorithm. Our method uses real-world data to learn about the dynamics of the system, and simulated data to learn a generalizable perception system that can enable the robot to avoid collisions using only a monocular camera. We demonstrate our approach on a real-world nano aerial vehicle collision avoidance task, showing that with only an hour of real-world data, the quadrotor can avoid collisions in new environments with various lighting conditions and geometry. Code, instructions for building the aerial vehicles, and videos of the experiments can be found at github.com/gkahn13/GtS
Robustness to Out-of-Distribution Inputs via Task-Aware Generative Uncertainty
Dec 27, 2018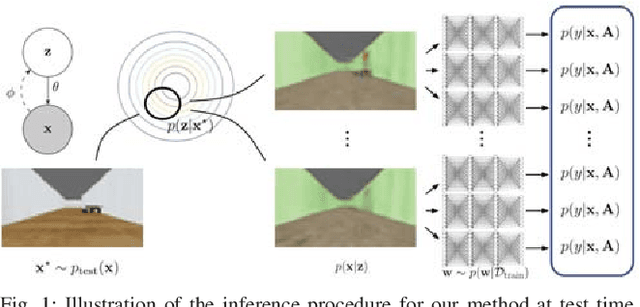
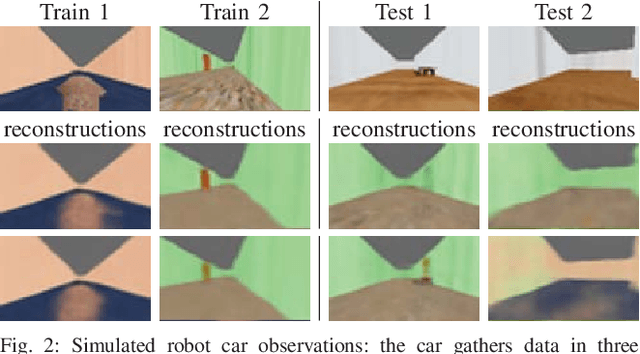
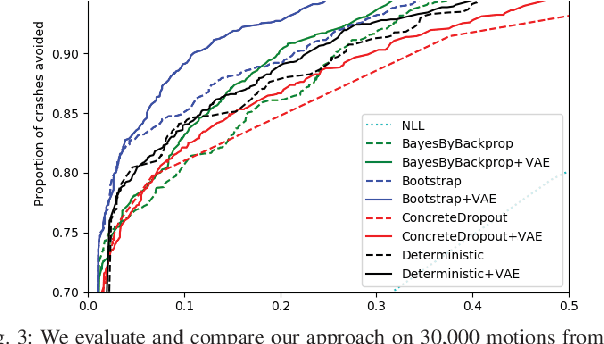

Deep learning provides a powerful tool for machine perception when the observations resemble the training data. However, real-world robotic systems must react intelligently to their observations even in unexpected circumstances. This requires a system to reason about its own uncertainty given unfamiliar, out-of-distribution observations. Approximate Bayesian approaches are commonly used to estimate uncertainty for neural network predictions, but can struggle with out-of-distribution observations. Generative models can in principle detect out-of-distribution observations as those with a low estimated density. However, the mere presence of an out-of-distribution input does not by itself indicate an unsafe situation. In this paper, we present a method for uncertainty-aware robotic perception that combines generative modeling and model uncertainty to cope with uncertainty stemming from out-of-distribution states. Our method estimates an uncertainty measure about the model's prediction, taking into account an explicit (generative) model of the observation distribution to handle out-of-distribution inputs. This is accomplished by probabilistically projecting observations onto the training distribution, such that out-of-distribution inputs map to uncertain in-distribution observations, which in turn produce uncertain task-related predictions, but only if task-relevant parts of the image change. We evaluate our method on an action-conditioned collision prediction task with both simulated and real data, and demonstrate that our method of projecting out-of-distribution observations improves the performance of four standard Bayesian and non-Bayesian neural network approaches, offering more favorable trade-offs between the proportion of time a robot can remain autonomous and the proportion of impending crashes successfully avoided.
Composable Action-Conditioned Predictors: Flexible Off-Policy Learning for Robot Navigation
Oct 16, 2018
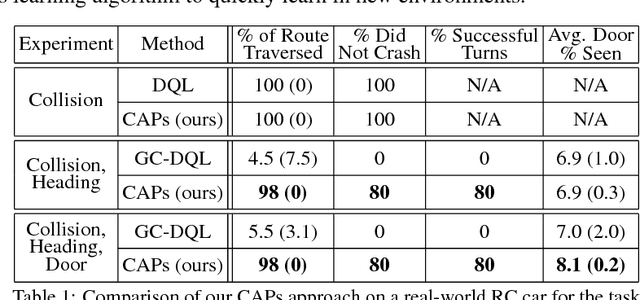
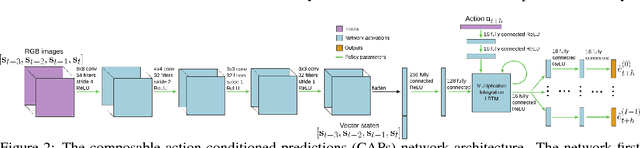
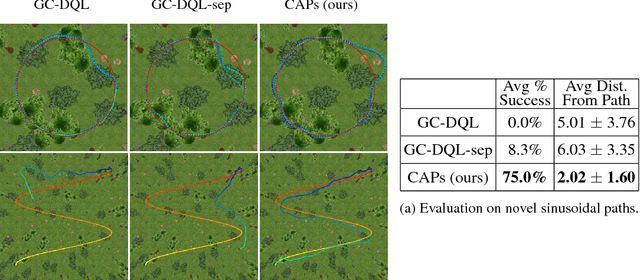
A general-purpose intelligent robot must be able to learn autonomously and be able to accomplish multiple tasks in order to be deployed in the real world. However, standard reinforcement learning approaches learn separate task-specific policies and assume the reward function for each task is known a priori. We propose a framework that learns event cues from off-policy data, and can flexibly combine these event cues at test time to accomplish different tasks. These event cue labels are not assumed to be known a priori, but are instead labeled using learned models, such as computer vision detectors, and then `backed up' in time using an action-conditioned predictive model. We show that a simulated robotic car and a real-world RC car can gather data and train fully autonomously without any human-provided labels beyond those needed to train the detectors, and then at test-time be able to accomplish a variety of different tasks. Videos of the experiments and code can be found at https://github.com/gkahn13/CAPs
Self-supervised Deep Reinforcement Learning with Generalized Computation Graphs for Robot Navigation
May 17, 2018

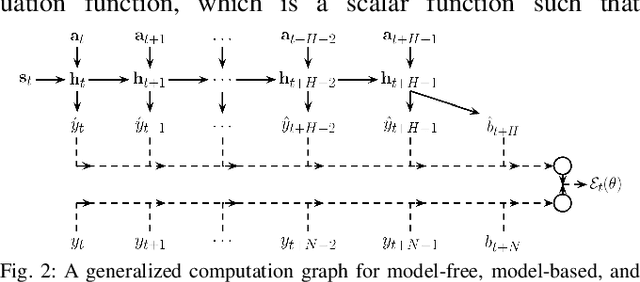
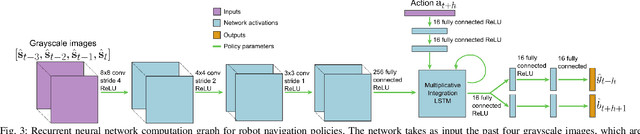
Enabling robots to autonomously navigate complex environments is essential for real-world deployment. Prior methods approach this problem by having the robot maintain an internal map of the world, and then use a localization and planning method to navigate through the internal map. However, these approaches often include a variety of assumptions, are computationally intensive, and do not learn from failures. In contrast, learning-based methods improve as the robot acts in the environment, but are difficult to deploy in the real-world due to their high sample complexity. To address the need to learn complex policies with few samples, we propose a generalized computation graph that subsumes value-based model-free methods and model-based methods, with specific instantiations interpolating between model-free and model-based. We then instantiate this graph to form a navigation model that learns from raw images and is sample efficient. Our simulated car experiments explore the design decisions of our navigation model, and show our approach outperforms single-step and $N$-step double Q-learning. We also evaluate our approach on a real-world RC car and show it can learn to navigate through a complex indoor environment with a few hours of fully autonomous, self-supervised training. Videos of the experiments and code can be found at github.com/gkahn13/gcg