 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTractable Joint Prediction and Planning over Discrete Behavior Modes for Urban Driving
Mar 12, 2024Significant progress has been made in training multimodal trajectory forecasting models for autonomous driving. However, effectively integrating these models with downstream planners and model-based control approaches is still an open problem. Although these models have conventionally been evaluated for open-loop prediction, we show that they can be used to parameterize autoregressive closed-loop models without retraining. We consider recent trajectory prediction approaches which leverage learned anchor embeddings to predict multiple trajectories, finding that these anchor embeddings can parameterize discrete and distinct modes representing high-level driving behaviors. We propose to perform fully reactive closed-loop planning over these discrete latent modes, allowing us to tractably model the causal interactions between agents at each step. We validate our approach on a suite of more dynamic merging scenarios, finding that our approach avoids the $\textit{frozen robot problem}$ which is pervasive in conventional planners. Our approach also outperforms the previous state-of-the-art in CARLA on challenging dense traffic scenarios when evaluated at realistic speeds.
Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning
Jul 21, 2022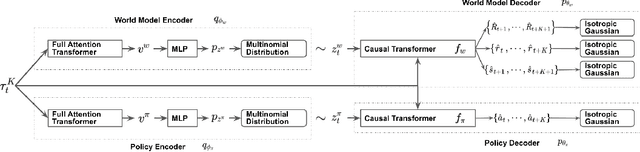


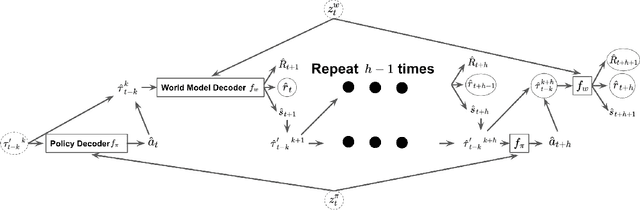
Impressive results in natural language processing (NLP) based on the Transformer neural network architecture have inspired researchers to explore viewing offline reinforcement learning (RL) as a generic sequence modeling problem. Recent works based on this paradigm have achieved state-of-the-art results in several of the mostly deterministic offline Atari and D4RL benchmarks. However, because these methods jointly model the states and actions as a single sequencing problem, they struggle to disentangle the effects of the policy and world dynamics on the return. Thus, in adversarial or stochastic environments, these methods lead to overly optimistic behavior that can be dangerous in safety-critical systems like autonomous driving. In this work, we propose a method that addresses this optimism bias by explicitly disentangling the policy and world models, which allows us at test time to search for policies that are robust to multiple possible futures in the environment. We demonstrate our method's superior performance on a variety of autonomous driving tasks in simulation.
BATS: Best Action Trajectory Stitching
Apr 26, 2022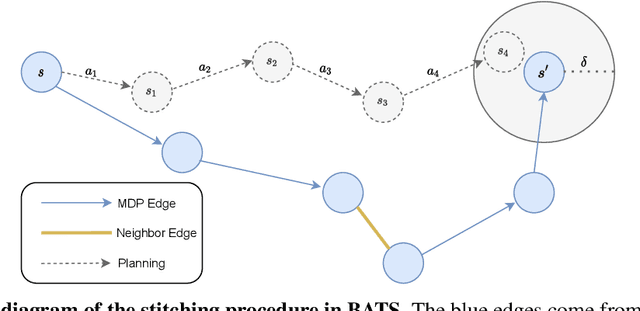

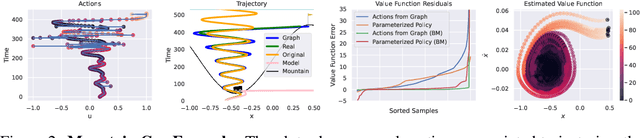
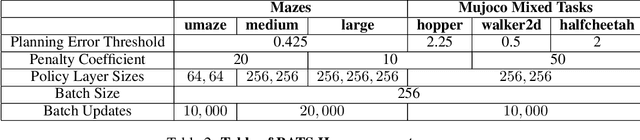
The problem of offline reinforcement learning focuses on learning a good policy from a log of environment interactions. Past efforts for developing algorithms in this area have revolved around introducing constraints to online reinforcement learning algorithms to ensure the actions of the learned policy are constrained to the logged data. In this work, we explore an alternative approach by planning on the fixed dataset directly. Specifically, we introduce an algorithm which forms a tabular Markov Decision Process (MDP) over the logged data by adding new transitions to the dataset. We do this by using learned dynamics models to plan short trajectories between states. Since exact value iteration can be performed on this constructed MDP, it becomes easy to identify which trajectories are advantageous to add to the MDP. Crucially, since most transitions in this MDP come from the logged data, trajectories from the MDP can be rolled out for long periods with confidence. We prove that this property allows one to make upper and lower bounds on the value function up to appropriate distance metrics. Finally, we demonstrate empirically how algorithms that uniformly constrain the learned policy to the entire dataset can result in unwanted behavior, and we show an example in which simply behavior cloning the optimal policy of the MDP created by our algorithm avoids this problem.
Learning to Robustly Negotiate Bi-Directional Lane Usage in High-Conflict Driving Scenarios
Mar 22, 2021
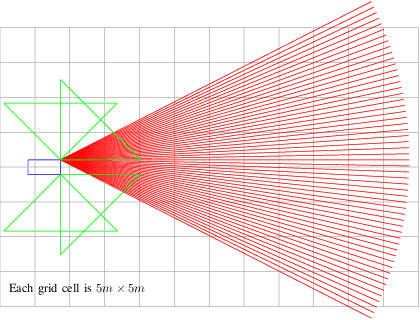

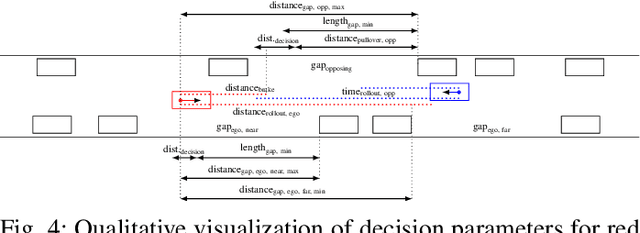
Recently, autonomous driving has made substantial progress in addressing the most common traffic scenarios like intersection navigation and lane changing. However, most of these successes have been limited to scenarios with well-defined traffic rules and require minimal negotiation with other vehicles. In this paper, we introduce a previously unconsidered, yet everyday, high-conflict driving scenario requiring negotiations between agents of equal rights and priorities. There exists no centralized control structure and we do not allow communications. Therefore, it is unknown if other drivers are willing to cooperate, and if so to what extent. We train policies to robustly negotiate with opposing vehicles of an unobservable degree of cooperativeness using multi-agent reinforcement learning (MARL). We propose Discrete Asymmetric Soft Actor-Critic (DASAC), a maximum-entropy off-policy MARL algorithm allowing for centralized training with decentralized execution. We show that using DASAC we are able to successfully negotiate and traverse the scenario considered over 99% of the time. Our agents are robust to an unknown timing of opponent decisions, an unobservable degree of cooperativeness of the opposing vehicle, and previously unencountered policies. Furthermore, they learn to exhibit human-like behaviors such as defensive driving, anticipating solution options and interpreting the behavior of other agents.
Composable Action-Conditioned Predictors: Flexible Off-Policy Learning for Robot Navigation
Oct 16, 2018
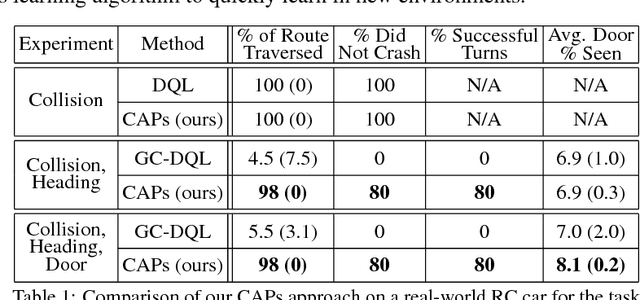
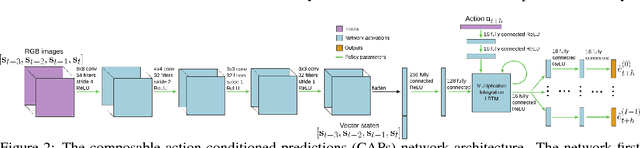
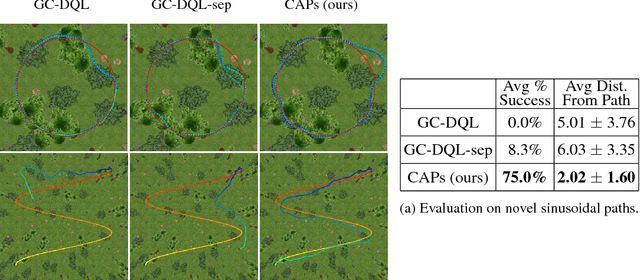
A general-purpose intelligent robot must be able to learn autonomously and be able to accomplish multiple tasks in order to be deployed in the real world. However, standard reinforcement learning approaches learn separate task-specific policies and assume the reward function for each task is known a priori. We propose a framework that learns event cues from off-policy data, and can flexibly combine these event cues at test time to accomplish different tasks. These event cue labels are not assumed to be known a priori, but are instead labeled using learned models, such as computer vision detectors, and then `backed up' in time using an action-conditioned predictive model. We show that a simulated robotic car and a real-world RC car can gather data and train fully autonomously without any human-provided labels beyond those needed to train the detectors, and then at test-time be able to accomplish a variety of different tasks. Videos of the experiments and code can be found at https://github.com/gkahn13/CAPs
Self-supervised Deep Reinforcement Learning with Generalized Computation Graphs for Robot Navigation
May 17, 2018

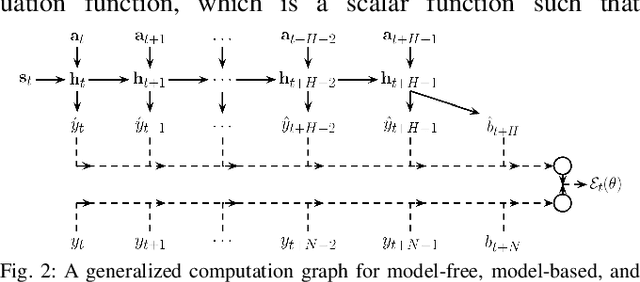
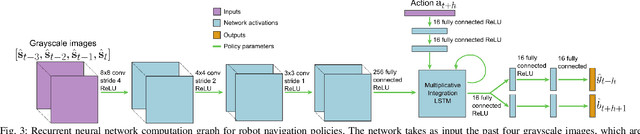
Enabling robots to autonomously navigate complex environments is essential for real-world deployment. Prior methods approach this problem by having the robot maintain an internal map of the world, and then use a localization and planning method to navigate through the internal map. However, these approaches often include a variety of assumptions, are computationally intensive, and do not learn from failures. In contrast, learning-based methods improve as the robot acts in the environment, but are difficult to deploy in the real-world due to their high sample complexity. To address the need to learn complex policies with few samples, we propose a generalized computation graph that subsumes value-based model-free methods and model-based methods, with specific instantiations interpolating between model-free and model-based. We then instantiate this graph to form a navigation model that learns from raw images and is sample efficient. Our simulated car experiments explore the design decisions of our navigation model, and show our approach outperforms single-step and $N$-step double Q-learning. We also evaluate our approach on a real-world RC car and show it can learn to navigate through a complex indoor environment with a few hours of fully autonomous, self-supervised training. Videos of the experiments and code can be found at github.com/gkahn13/gcg
Uncertainty-Aware Reinforcement Learning for Collision Avoidance
Feb 03, 2017
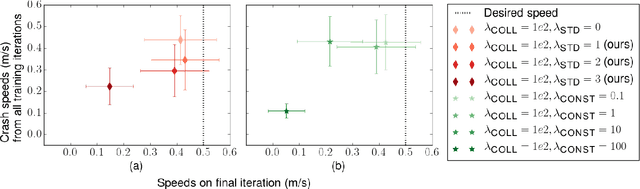

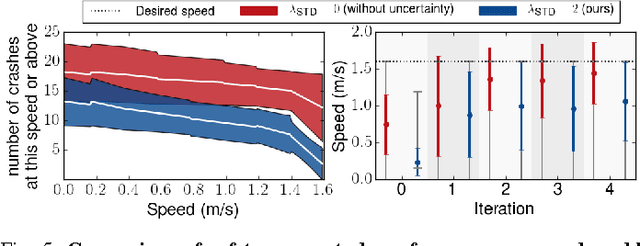
Reinforcement learning can enable complex, adaptive behavior to be learned automatically for autonomous robotic platforms. However, practical deployment of reinforcement learning methods must contend with the fact that the training process itself can be unsafe for the robot. In this paper, we consider the specific case of a mobile robot learning to navigate an a priori unknown environment while avoiding collisions. In order to learn collision avoidance, the robot must experience collisions at training time. However, high-speed collisions, even at training time, could damage the robot. A successful learning method must therefore proceed cautiously, experiencing only low-speed collisions until it gains confidence. To this end, we present an uncertainty-aware model-based learning algorithm that estimates the probability of collision together with a statistical estimate of uncertainty. By formulating an uncertainty-dependent cost function, we show that the algorithm naturally chooses to proceed cautiously in unfamiliar environments, and increases the velocity of the robot in settings where it has high confidence. Our predictive model is based on bootstrapped neural networks using dropout, allowing it to process raw sensory inputs from high-bandwidth sensors such as cameras. Our experimental evaluation demonstrates that our method effectively minimizes dangerous collisions at training time in an obstacle avoidance task for a simulated and real-world quadrotor, and a real-world RC car. Videos of the experiments can be found at https://sites.google.com/site/probcoll.