 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximately Optimal Global Planning for Contact-Rich SE(2) Manipulation on a Graph of Reachable Sets
Jan 15, 2026If we consider human manipulation, it is clear that contact-rich manipulation (CRM)-the ability to use any surface of the manipulator to make contact with objects-can be far more efficient and natural than relying solely on end-effectors (i.e., fingertips). However, state-of-the-art model-based planners for CRM are still focused on feasibility rather than optimality, limiting their ability to fully exploit CRM's advantages. We introduce a new paradigm that computes approximately optimal manipulator plans. This approach has two phases. Offline, we construct a graph of mutual reachable sets, where each set contains all object orientations reachable from a starting object orientation and grasp. Online, we plan over this graph, effectively computing and sequencing local plans for globally optimized motion. On a challenging, representative contact-rich task, our approach outperforms a leading planner, reducing task cost by 61%. It also achieves a 91% success rate across 250 queries and maintains sub-minute query times, ultimately demonstrating that globally optimized contact-rich manipulation is now practical for real-world tasks.
Q-learning-based Model-free Safety Filter
Nov 29, 2024Ensuring safety via safety filters in real-world robotics presents significant challenges, particularly when the system dynamics is complex or unavailable. To handle this issue, learning-based safety filters recently gained popularity, which can be classified as model-based and model-free methods. Existing model-based approaches requires various assumptions on system model (e.g., control-affine), which limits their application in complex systems, and existing model-free approaches need substantial modifications to standard RL algorithms and lack versatility. This paper proposes a simple, plugin-and-play, and effective model-free safety filter learning framework. We introduce a novel reward formulation and use Q-learning to learn Q-value functions to safeguard arbitrary task specific nominal policies via filtering out their potentially unsafe actions. The threshold used in the filtering process is supported by our theoretical analysis. Due to its model-free nature and simplicity, our framework can be seamlessly integrated with various RL algorithms. We validate the proposed approach through simulations on double integrator and Dubin's car systems and demonstrate its effectiveness in real-world experiments with a soft robotic limb.
Hierarchical Learned Risk-Aware Planning Framework for Human Driving Modeling
May 10, 2024



This paper presents a novel approach to modeling human driving behavior, designed for use in evaluating autonomous vehicle control systems in a simulation environments. Our methodology leverages a hierarchical forward-looking, risk-aware estimation framework with learned parameters to generate human-like driving trajectories, accommodating multiple driver levels determined by model parameters. This approach is grounded in multimodal trajectory prediction, using a deep neural network with LSTM-based social pooling to predict the trajectories of surrounding vehicles. These trajectories are used to compute forward-looking risk assessments along the ego vehicle's path, guiding its navigation. Our method aims to replicate human driving behaviors by learning parameters that emulate human decision-making during driving. We ensure that our model exhibits robust generalization capabilities by conducting simulations, employing real-world driving data to validate the accuracy of our approach in modeling human behavior. The results reveal that our model effectively captures human behavior, showcasing its versatility in modeling human drivers in diverse highway scenarios.
Tractable Joint Prediction and Planning over Discrete Behavior Modes for Urban Driving
Mar 12, 2024Significant progress has been made in training multimodal trajectory forecasting models for autonomous driving. However, effectively integrating these models with downstream planners and model-based control approaches is still an open problem. Although these models have conventionally been evaluated for open-loop prediction, we show that they can be used to parameterize autoregressive closed-loop models without retraining. We consider recent trajectory prediction approaches which leverage learned anchor embeddings to predict multiple trajectories, finding that these anchor embeddings can parameterize discrete and distinct modes representing high-level driving behaviors. We propose to perform fully reactive closed-loop planning over these discrete latent modes, allowing us to tractably model the causal interactions between agents at each step. We validate our approach on a suite of more dynamic merging scenarios, finding that our approach avoids the $\textit{frozen robot problem}$ which is pervasive in conventional planners. Our approach also outperforms the previous state-of-the-art in CARLA on challenging dense traffic scenarios when evaluated at realistic speeds.
Safe Deep Policy Adaptation
Oct 08, 2023



A critical goal of autonomy and artificial intelligence is enabling autonomous robots to rapidly adapt in dynamic and uncertain environments. Classic adaptive control and safe control provide stability and safety guarantees but are limited to specific system classes. In contrast, policy adaptation based on reinforcement learning (RL) offers versatility and generalizability but presents safety and robustness challenges. We propose SafeDPA, a novel RL and control framework that simultaneously tackles the problems of policy adaptation and safe reinforcement learning. SafeDPA jointly learns adaptive policy and dynamics models in simulation, predicts environment configurations, and fine-tunes dynamics models with few-shot real-world data. A safety filter based on the Control Barrier Function (CBF) on top of the RL policy is introduced to ensure safety during real-world deployment. We provide theoretical safety guarantees of SafeDPA and show the robustness of SafeDPA against learning errors and extra perturbations. Comprehensive experiments on (1) classic control problems (Inverted Pendulum), (2) simulation benchmarks (Safety Gym), and (3) a real-world agile robotics platform (RC Car) demonstrate great superiority of SafeDPA in both safety and task performance, over state-of-the-art baselines. Particularly, SafeDPA demonstrates notable generalizability, achieving a 300% increase in safety rate compared to the baselines, under unseen disturbances in real-world experiments.
Reasoning with Latent Diffusion in Offline Reinforcement Learning
Sep 12, 2023



Offline reinforcement learning (RL) holds promise as a means to learn high-reward policies from a static dataset, without the need for further environment interactions. However, a key challenge in offline RL lies in effectively stitching portions of suboptimal trajectories from the static dataset while avoiding extrapolation errors arising due to a lack of support in the dataset. Existing approaches use conservative methods that are tricky to tune and struggle with multi-modal data (as we show) or rely on noisy Monte Carlo return-to-go samples for reward conditioning. In this work, we propose a novel approach that leverages the expressiveness of latent diffusion to model in-support trajectory sequences as compressed latent skills. This facilitates learning a Q-function while avoiding extrapolation error via batch-constraining. The latent space is also expressive and gracefully copes with multi-modal data. We show that the learned temporally-abstract latent space encodes richer task-specific information for offline RL tasks as compared to raw state-actions. This improves credit assignment and facilitates faster reward propagation during Q-learning. Our method demonstrates state-of-the-art performance on the D4RL benchmarks, particularly excelling in long-horizon, sparse-reward tasks.
Model-based Dynamic Shielding for Safe and Efficient Multi-Agent Reinforcement Learning
Apr 13, 2023



Multi-Agent Reinforcement Learning (MARL) discovers policies that maximize reward but do not have safety guarantees during the learning and deployment phases. Although shielding with Linear Temporal Logic (LTL) is a promising formal method to ensure safety in single-agent Reinforcement Learning (RL), it results in conservative behaviors when scaling to multi-agent scenarios. Additionally, it poses computational challenges for synthesizing shields in complex multi-agent environments. This work introduces Model-based Dynamic Shielding (MBDS) to support MARL algorithm design. Our algorithm synthesizes distributive shields, which are reactive systems running in parallel with each MARL agent, to monitor and rectify unsafe behaviors. The shields can dynamically split, merge, and recompute based on agents' states. This design enables efficient synthesis of shields to monitor agents in complex environments without coordination overheads. We also propose an algorithm to synthesize shields without prior knowledge of the dynamics model. The proposed algorithm obtains an approximate world model by interacting with the environment during the early stage of exploration, making our MBDS enjoy formal safety guarantees with high probability. We demonstrate in simulations that our framework can surpass existing baselines in terms of safety guarantees and learning performance.
Safe Reinforcement Learning with Probabilistic Control Barrier Functions for Ramp Merging
Dec 01, 2022



Prior work has looked at applying reinforcement learning and imitation learning approaches to autonomous driving scenarios, but either the safety or the efficiency of the algorithm is compromised. With the use of control barrier functions embedded into the reinforcement learning policy, we arrive at safe policies to optimize the performance of the autonomous driving vehicle. However, control barrier functions need a good approximation of the model of the car. We use probabilistic control barrier functions as an estimate of the model uncertainty. The algorithm is implemented as an online version in the CARLA (Dosovitskiy et al., 2017) Simulator and as an offline version on a dataset extracted from the NGSIM Database. The proposed algorithm is not just a safe ramp merging algorithm but a safe autonomous driving algorithm applied to address ramp merging on highways.
Safe Control Under Input Limits with Neural Control Barrier Functions
Nov 20, 2022We propose new methods to synthesize control barrier function (CBF)-based safe controllers that avoid input saturation, which can cause safety violations. In particular, our method is created for high-dimensional, general nonlinear systems, for which such tools are scarce. We leverage techniques from machine learning, like neural networks and deep learning, to simplify this challenging problem in nonlinear control design. The method consists of a learner-critic architecture, in which the critic gives counterexamples of input saturation and the learner optimizes a neural CBF to eliminate those counterexamples. We provide empirical results on a 10D state, 4D input quadcopter-pendulum system. Our learned CBF avoids input saturation and maintains safety over nearly 100% of trials.
Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning
Jul 21, 2022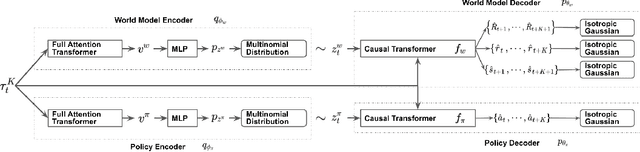


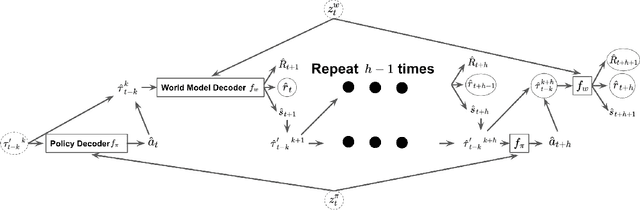
Impressive results in natural language processing (NLP) based on the Transformer neural network architecture have inspired researchers to explore viewing offline reinforcement learning (RL) as a generic sequence modeling problem. Recent works based on this paradigm have achieved state-of-the-art results in several of the mostly deterministic offline Atari and D4RL benchmarks. However, because these methods jointly model the states and actions as a single sequencing problem, they struggle to disentangle the effects of the policy and world dynamics on the return. Thus, in adversarial or stochastic environments, these methods lead to overly optimistic behavior that can be dangerous in safety-critical systems like autonomous driving. In this work, we propose a method that addresses this optimism bias by explicitly disentangling the policy and world models, which allows us at test time to search for policies that are robust to multiple possible futures in the environment. We demonstrate our method's superior performance on a variety of autonomous driving tasks in simulation.