 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow cost, easily manufactured, highly flexible strain and touch sensitive fiber for robotics applications
Jun 11, 2026Existing stretch and touch sensors for robots are generally expensive with respect to at least one of material costs, required manufacturing equipment, or manufacturing time. We present and experimentally characterize a conductive fiber made using only inexpensive commercial off-the-shelf parts (conductive thread at $0.07/ft, silicone tubing at $0.94/ft) and tools (loop-style needle threader at $2), which can be manufactured quickly (20 cm length in 2 minutes.) We demonstrate its use as a resistive strain sensor with three applications: Triggering a grasp in a pneumatically actuated assistive finger, sensing the pose of a pneumatically actuated robotic strap, and estimating the pose of a flexible solid. We also demonstrate that it can be used as a capacitive sensor with two applications: First, as a touch sensor which triggers a commercial robot arm to move, and second, as a near-field sensor enabling the robot arm to follow a moving hand. The capacitive sensors are knitted, showcasing the high flexibility of the fiber. We discuss methods for improving manufacturing scalability and their cost trade-offs. Finally, we demonstrate a method for repairing a cut fiber.
Approximately Optimal Global Planning for Contact-Rich SE(2) Manipulation on a Graph of Reachable Sets
Jan 15, 2026If we consider human manipulation, it is clear that contact-rich manipulation (CRM)-the ability to use any surface of the manipulator to make contact with objects-can be far more efficient and natural than relying solely on end-effectors (i.e., fingertips). However, state-of-the-art model-based planners for CRM are still focused on feasibility rather than optimality, limiting their ability to fully exploit CRM's advantages. We introduce a new paradigm that computes approximately optimal manipulator plans. This approach has two phases. Offline, we construct a graph of mutual reachable sets, where each set contains all object orientations reachable from a starting object orientation and grasp. Online, we plan over this graph, effectively computing and sequencing local plans for globally optimized motion. On a challenging, representative contact-rich task, our approach outperforms a leading planner, reducing task cost by 61%. It also achieves a 91% success rate across 250 queries and maintains sub-minute query times, ultimately demonstrating that globally optimized contact-rich manipulation is now practical for real-world tasks.
Neural Spatial-Temporal Tensor Representation for Infrared Small Target Detection
Dec 23, 2024Optimization-based approaches dominate infrared small target detection as they leverage infrared imagery's intrinsic low-rankness and sparsity. While effective for single-frame images, they struggle with dynamic changes in multi-frame scenarios as traditional spatial-temporal representations often fail to adapt. To address these challenges, we introduce a Neural-represented Spatial-Temporal Tensor (NeurSTT) model. This framework employs nonlinear networks to enhance spatial-temporal feature correlations in background approximation, thereby supporting target detection in an unsupervised manner. Specifically, we employ neural layers to approximate sequential backgrounds within a low-rank informed deep scheme. A neural three-dimensional total variation is developed to refine background smoothness while reducing static target-like clusters in sequences. Traditional sparsity constraints are incorporated into the loss functions to preserve potential targets. By replacing complex solvers with a deep updating strategy, NeurSTT simplifies the optimization process in a domain-awareness way. Visual and numerical results across various datasets demonstrate that our method outperforms detection challenges. Notably, it has 16.6$\times$ fewer parameters and averaged 19.19\% higher in $IoU$ compared to the suboptimal method on $256 \times 256$ sequences.
Certifying Robustness of Learning-Based Keypoint Detection and Pose Estimation Methods
Jul 31, 2024



This work addresses the certification of the local robustness of vision-based two-stage 6D object pose estimation. The two-stage method for object pose estimation achieves superior accuracy by first employing deep neural network-driven keypoint regression and then applying a Perspective-n-Point (PnP) technique. Despite advancements, the certification of these methods' robustness remains scarce. This research aims to fill this gap with a focus on their local robustness on the system level--the capacity to maintain robust estimations amidst semantic input perturbations. The core idea is to transform the certification of local robustness into neural network verification for classification tasks. The challenge is to develop model, input, and output specifications that align with off-the-shelf verification tools. To facilitate verification, we modify the keypoint detection model by substituting nonlinear operations with those more amenable to the verification processes. Instead of injecting random noise into images, as is common, we employ a convex hull representation of images as input specifications to more accurately depict semantic perturbations. Furthermore, by conducting a sensitivity analysis, we propagate the robustness criteria from pose to keypoint accuracy, and then formulating an optimal error threshold allocation problem that allows for the setting of a maximally permissible keypoint deviation thresholds. Viewing each pixel as an individual class, these thresholds result in linear, classification-akin output specifications. Under certain conditions, we demonstrate that the main components of our certification framework are both sound and complete, and validate its effects through extensive evaluations on realistic perturbations. To our knowledge, this is the first study to certify the robustness of large-scale, keypoint-based pose estimation given images in real-world scenarios.
Research on Information Extraction of LCSTS Dataset Based on an Improved BERTSum-LSTM Model
Jun 26, 2024



With the continuous advancement of artificial intelligence, natural language processing technology has become widely utilized in various fields. At the same time, there are many challenges in creating Chinese news summaries. First of all, the semantics of Chinese news is complex, and the amount of information is enormous. Extracting critical information from Chinese news presents a significant challenge. Second, the news summary should be concise and clear, focusing on the main content and avoiding redundancy. In addition, the particularity of the Chinese language, such as polysemy, word segmentation, etc., makes it challenging to generate Chinese news summaries. Based on the above, this paper studies the information extraction method of the LCSTS dataset based on an improved BERTSum-LSTM model. We improve the BERTSum-LSTM model to make it perform better in generating Chinese news summaries. The experimental results show that the proposed method has a good effect on creating news summaries, which is of great importance to the construction of news summaries.
Synthesis and verification of robust-adaptive safe controllers
Nov 01, 2023



Safe control with guarantees generally requires the system model to be known. It is far more challenging to handle systems with uncertain parameters. In this paper, we propose a generic algorithm that can synthesize and verify safe controllers for systems with constant, unknown parameters. In particular, we use robust-adaptive control barrier functions (raCBFs) to achieve safety. We develop new theories and techniques using sum-of-squares that enable us to pose synthesis and verification as a series of convex optimization problems. In our experiments, we show that our algorithms are general and scalable, applying them to three different polynomial systems of up to moderate size (7D). Our raCBFs are currently the most effective way to guarantee safety for uncertain systems, achieving 100% safety and up to 55% performance improvement over a robust baseline.
Learning the Positions in CountSketch
Jun 11, 2023We consider sketching algorithms which first compress data by multiplication with a random sketch matrix, and then apply the sketch to quickly solve an optimization problem, e.g., low-rank approximation and regression. In the learning-based sketching paradigm proposed by~\cite{indyk2019learning}, the sketch matrix is found by choosing a random sparse matrix, e.g., CountSketch, and then the values of its non-zero entries are updated by running gradient descent on a training data set. Despite the growing body of work on this paradigm, a noticeable omission is that the locations of the non-zero entries of previous algorithms were fixed, and only their values were learned. In this work, we propose the first learning-based algorithms that also optimize the locations of the non-zero entries. Our first proposed algorithm is based on a greedy algorithm. However, one drawback of the greedy algorithm is its slower training time. We fix this issue and propose approaches for learning a sketching matrix for both low-rank approximation and Hessian approximation for second order optimization. The latter is helpful for a range of constrained optimization problems, such as LASSO and matrix estimation with a nuclear norm constraint. Both approaches achieve good accuracy with a fast running time. Moreover, our experiments suggest that our algorithm can still reduce the error significantly even if we only have a very limited number of training matrices.
Safe Control Under Input Limits with Neural Control Barrier Functions
Nov 20, 2022We propose new methods to synthesize control barrier function (CBF)-based safe controllers that avoid input saturation, which can cause safety violations. In particular, our method is created for high-dimensional, general nonlinear systems, for which such tools are scarce. We leverage techniques from machine learning, like neural networks and deep learning, to simplify this challenging problem in nonlinear control design. The method consists of a learner-critic architecture, in which the critic gives counterexamples of input saturation and the learner optimizes a neural CBF to eliminate those counterexamples. We provide empirical results on a 10D state, 4D input quadcopter-pendulum system. Our learned CBF avoids input saturation and maintains safety over nearly 100% of trials.
Safety Index Synthesis via Sum-of-Squares Programming
Sep 19, 2022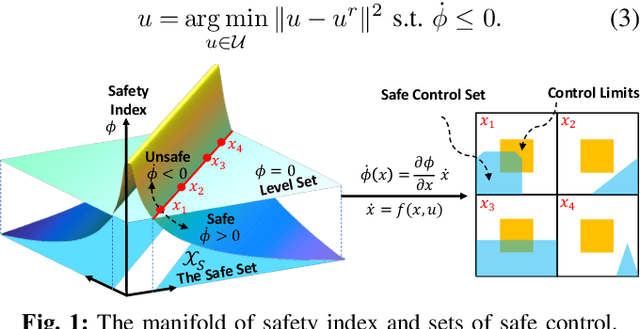
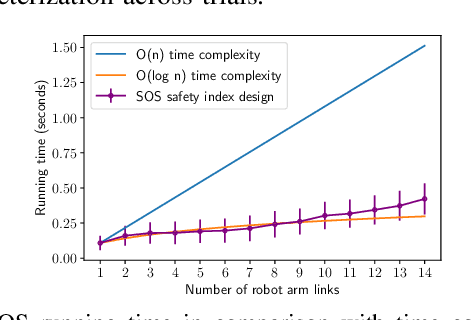
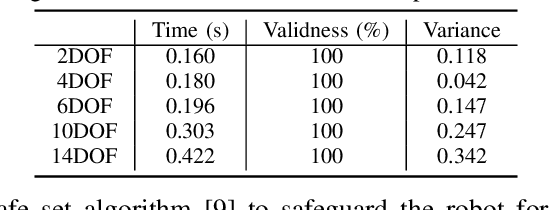

Control systems often need to satisfy strict safety requirements. Safety index provides a handy way to evaluate the safety level of the system and derive the resulting safe control policies. However, designing safety index functions under control limits is difficult and requires a great amount of expert knowledge. This paper proposes a framework for synthesizing the safety index for general control systems using sum-of-squares programming. Our approach is to show that ensuring the non-emptiness of safe control on the safe set boundary is equivalent to a local manifold positiveness problem. We then prove that this problem is equivalent to sum-of-squares programming via the Positivstellensatz of algebraic geometry. We validate the proposed method on robot arms with different degrees of freedom and ground vehicles. The results show that the synthesized safety index guarantees safety and our method is effective even in high-dimensional robot systems.
Overview of FPGA deep learning acceleration based on convolutional neural network
Dec 23, 2020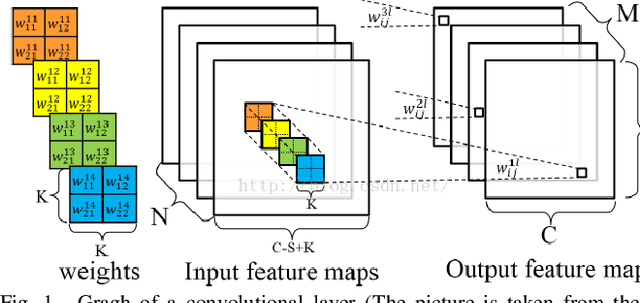
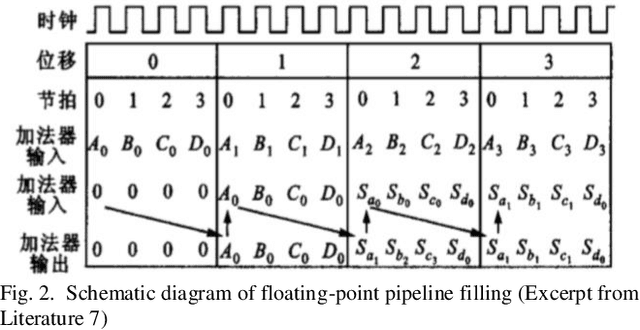
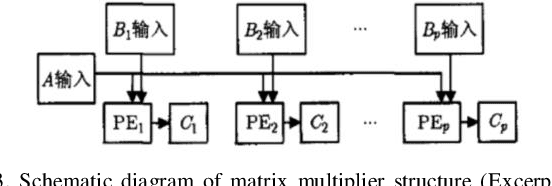
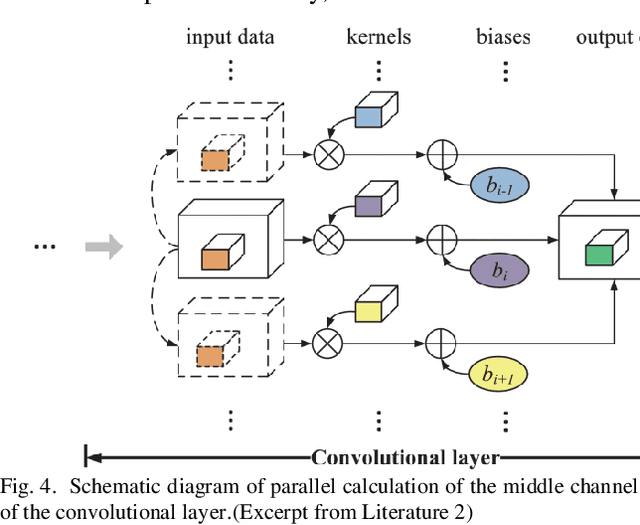
In recent years, deep learning has become more and more mature, and as a commonly used algorithm in deep learning, convolutional neural networks have been widely used in various visual tasks. In the past, research based on deep learning algorithms mainly relied on hardware such as GPUs and CPUs. However, with the increasing development of FPGAs, both field programmable logic gate arrays, it has become the main implementation hardware platform that combines various neural network deep learning algorithms This article is a review article, which mainly introduces the related theories and algorithms of convolution. It summarizes the application scenarios of several existing FPGA technologies based on convolutional neural networks, and mainly introduces the application of accelerators. At the same time, it summarizes some accelerators' under-utilization of logic resources or under-utilization of memory bandwidth, so that they can't get the best performance.