 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially Selective Self-Training for Unsupervised Building Change Detection
Jun 09, 2026Unsupervised building change detection aims to learn building-change masks from unlabeled bi-temporal remote sensing images. Existing label-free methods often follow a discrepancy-to-mask paradigm, directly using temporal differences, frozen foundation-model responses, prompt-based outputs, or post-processing results as final change maps. Although these strategies provide annotation-free cues, they do not learn a task-specific building-change detector and remain vulnerable to the gap between generic temporal discrepancies and building-defined structural changes. In practice, such discrepancies are often noisy and task-irrelevant, as appearance shifts, registration errors, and non-building modifications can produce strong but misleading responses. To address this problem, we propose SST-CD, a spatially selective self-training framework that reformulates fully label-free building change detection as end-to-end detector learning under noisy pseudo supervision. SST-CD uses temporal discrepancies as candidate pseudo labels and trains the detector only on spatially reliable pixels, whose reliability is estimated by a local consistency criterion that filters inconsistent regions from supervision. To further stabilize noisy self-training, a lightweight feature adapter recalibrates bi-temporal features, while a prototype-based decoder produces compact change and no-change representations. Experiments on LEVIR-CD, WHU-CD, and DSIFN-CD show that SST-CD achieves F1 scores of 83.08\%, 91.69\%, and 86.60\%, respectively, outperforming existing unsupervised and label-free baselines. Code will be made publicly available.
ExpAlign: Expectation-Guided Vision-Language Alignment for Open-Vocabulary Grounding
Jan 30, 2026Open-vocabulary grounding requires accurate vision-language alignment under weak supervision, yet existing methods either rely on global sentence embeddings that lack fine-grained expressiveness or introduce token-level alignment with explicit supervision or heavy cross-attention designs. We propose ExpAlign, a theoretically grounded vision-language alignment framework built on a principled multiple instance learning formulation. ExpAlign introduces an Expectation Alignment Head that performs attention-based soft MIL pooling over token-region similarities, enabling implicit token and instance selection without additional annotations. To further stabilize alignment learning, we develop an energy-based multi-scale consistency regularization scheme, including a Top-K multi-positive contrastive objective and a Geometry-Aware Consistency Objective derived from a Lagrangian-constrained free-energy minimization. Extensive experiments show that ExpAlign consistently improves open-vocabulary detection and zero-shot instance segmentation, particularly on long-tail categories. Most notably, it achieves 36.2 AP$_r$ on the LVIS minival split, outperforming other state-of-the-art methods at comparable model scale, while remaining lightweight and inference-efficient.
FeedbackSTS-Det: Sparse Frames-Based Spatio-Temporal Semantic Feedback Network for Infrared Small Target Detection
Jan 21, 2026Infrared small target detection (ISTD) under complex backgrounds remains a critical yet challenging task, primarily due to the extremely low signal-to-clutter ratio, persistent dynamic interference, and the lack of distinct target features. While multi-frame detection methods leverages temporal cues to improve upon single-frame approaches, existing methods still struggle with inefficient long-range dependency modeling and insufficient robustness. To overcome these issues, we propose a novel scheme for ISTD, realized through a sparse frames-based spatio-temporal semantic feedback network named FeedbackSTS-Det. The core of our approach is a novel spatio-temporal semantic feedback strategy with a closed-loop semantic association mechanism, which consists of paired forward and backward refinement modules that work cooperatively across the encoder and decoder. Moreover, both modules incorporate an embedded sparse semantic module (SSM), which performs structured sparse temporal modeling to capture long-range dependencies with low computational cost. This integrated design facilitates robust implicit inter-frame registration and continuous semantic refinement, effectively suppressing false alarms. Furthermore, our overall procedure maintains a consistent training-inference pipeline, which ensures reliable performance transfer and increases model robustness. Extensive experiments on multiple benchmark datasets confirm the effectiveness of FeedbackSTS-Det. Code and models are available at: https://github.com/IDIP-Lab/FeedbackSTS-Det.
RPCANet++: Deep Interpretable Robust PCA for Sparse Object Segmentation
Aug 06, 2025
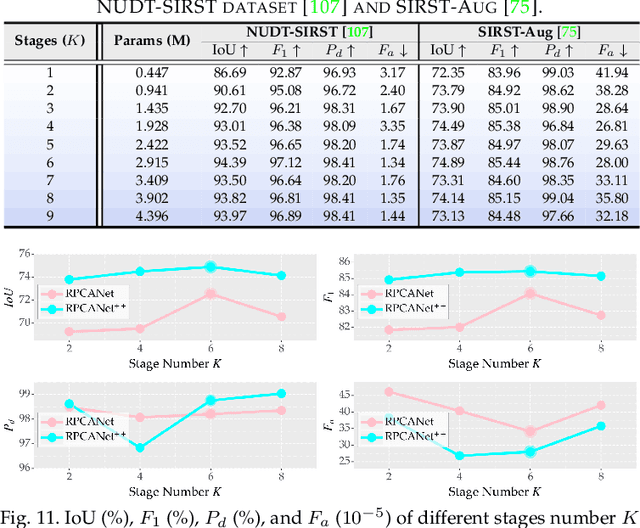

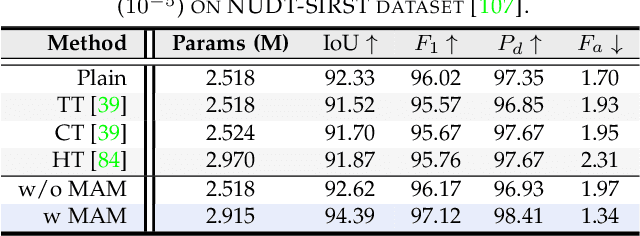
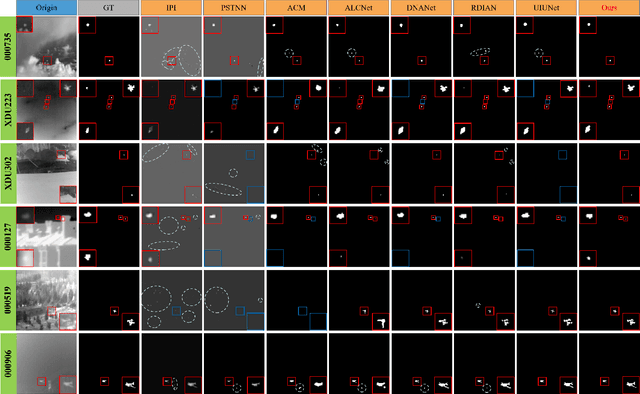
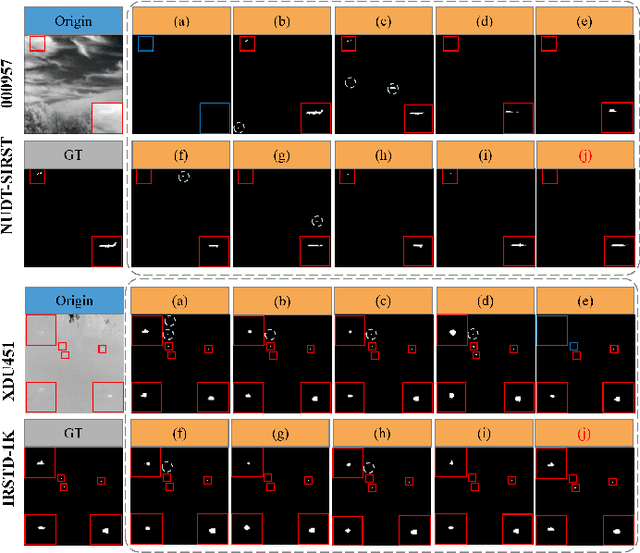
Robust principal component analysis (RPCA) decomposes an observation matrix into low-rank background and sparse object components. This capability has enabled its application in tasks ranging from image restoration to segmentation. However, traditional RPCA models suffer from computational burdens caused by matrix operations, reliance on finely tuned hyperparameters, and rigid priors that limit adaptability in dynamic scenarios. To solve these limitations, we propose RPCANet++, a sparse object segmentation framework that fuses the interpretability of RPCA with efficient deep architectures. Our approach unfolds a relaxed RPCA model into a structured network comprising a Background Approximation Module (BAM), an Object Extraction Module (OEM), and an Image Restoration Module (IRM). To mitigate inter-stage transmission loss in the BAM, we introduce a Memory-Augmented Module (MAM) to enhance background feature preservation, while a Deep Contrast Prior Module (DCPM) leverages saliency cues to expedite object extraction. Extensive experiments on diverse datasets demonstrate that RPCANet++ achieves state-of-the-art performance under various imaging scenarios. We further improve interpretability via visual and numerical low-rankness and sparsity measurements. By combining the theoretical strengths of RPCA with the efficiency of deep networks, our approach sets a new baseline for reliable and interpretable sparse object segmentation. Codes are available at our Project Webpage https://fengyiwu98.github.io/rpcanetx.
CSPENet: Contour-Aware and Saliency Priors Embedding Network for Infrared Small Target Detection
May 15, 2025Infrared small target detection (ISTD) plays a critical role in a wide range of civilian and military applications. Existing methods suffer from deficiencies in the localization of dim targets and the perception of contour information under dense clutter environments, severely limiting their detection performance. To tackle these issues, we propose a contour-aware and saliency priors embedding network (CSPENet) for ISTD. We first design a surround-convergent prior extraction module (SCPEM) that effectively captures the intrinsic characteristic of target contour pixel gradients converging toward their center. This module concurrently extracts two collaborative priors: a boosted saliency prior for accurate target localization and multi-scale structural priors for comprehensively enriching contour detail representation. Building upon this, we propose a dual-branch priors embedding architecture (DBPEA) that establishes differentiated feature fusion pathways, embedding these two priors at optimal network positions to achieve performance enhancement. Finally, we develop an attention-guided feature enhancement module (AGFEM) to refine feature representations and improve saliency estimation accuracy. Experimental results on public datasets NUDT-SIRST, IRSTD-1k, and NUAA-SIRST demonstrate that our CSPENet outperforms other state-of-the-art methods in detection performance. The code is available at https://github.com/IDIP2025/CSPENet.
ARFC-WAHNet: Adaptive Receptive Field Convolution and Wavelet-Attentive Hierarchical Network for Infrared Small Target Detection
May 15, 2025

Infrared small target detection (ISTD) is critical in both civilian and military applications. However, the limited texture and structural information in infrared images makes accurate detection particularly challenging. Although recent deep learning-based methods have improved performance, their use of conventional convolution kernels limits adaptability to complex scenes and diverse targets. Moreover, pooling operations often cause feature loss and insufficient exploitation of image information. To address these issues, we propose an adaptive receptive field convolution and wavelet-attentive hierarchical network for infrared small target detection (ARFC-WAHNet). This network incorporates a multi-receptive field feature interaction convolution (MRFFIConv) module to adaptively extract discriminative features by integrating multiple convolutional branches with a gated unit. A wavelet frequency enhancement downsampling (WFED) module leverages Haar wavelet transform and frequency-domain reconstruction to enhance target features and suppress background noise. Additionally, we introduce a high-low feature fusion (HLFF) module for integrating low-level details with high-level semantics, and a global median enhancement attention (GMEA) module to improve feature diversity and expressiveness via global attention. Experiments on public datasets SIRST, NUDT-SIRST, and IRSTD-1k demonstrate that ARFC-WAHNet outperforms recent state-of-the-art methods in both detection accuracy and robustness, particularly under complex backgrounds. The code is available at https://github.com/Leaf2001/ARFC-WAHNet.
Neural Spatial-Temporal Tensor Representation for Infrared Small Target Detection
Dec 23, 2024Optimization-based approaches dominate infrared small target detection as they leverage infrared imagery's intrinsic low-rankness and sparsity. While effective for single-frame images, they struggle with dynamic changes in multi-frame scenarios as traditional spatial-temporal representations often fail to adapt. To address these challenges, we introduce a Neural-represented Spatial-Temporal Tensor (NeurSTT) model. This framework employs nonlinear networks to enhance spatial-temporal feature correlations in background approximation, thereby supporting target detection in an unsupervised manner. Specifically, we employ neural layers to approximate sequential backgrounds within a low-rank informed deep scheme. A neural three-dimensional total variation is developed to refine background smoothness while reducing static target-like clusters in sequences. Traditional sparsity constraints are incorporated into the loss functions to preserve potential targets. By replacing complex solvers with a deep updating strategy, NeurSTT simplifies the optimization process in a domain-awareness way. Visual and numerical results across various datasets demonstrate that our method outperforms detection challenges. Notably, it has 16.6$\times$ fewer parameters and averaged 19.19\% higher in $IoU$ compared to the suboptimal method on $256 \times 256$ sequences.
Gradient is All You Need: Gradient-Based Attention Fusion for Infrared Small Target Detection
Sep 29, 2024



Infrared small target detection (IRSTD) is widely used in civilian and military applications. However, IRSTD encounters several challenges, including the tendency for small and dim targets to be obscured by complex backgrounds. To address this issue, we propose the Gradient Network (GaNet), which aims to extract and preserve edge and gradient information of small targets. GaNet employs the Gradient Transformer (GradFormer) module, simulating central difference convolutions (CDC) to extract and integrate gradient features with deeper features. Furthermore, we propose a global feature extraction model (GFEM) that offers a comprehensive perspective to prevent the network from focusing solely on details while neglecting the background information. We compare the network with state-of-the-art (SOTA) approaches, and the results demonstrate that our method performs effectively. Our source code is available at https://github.com/greekinRoma/Gradient-Transformer.
SMPISD-MTPNet: Scene Semantic Prior-Assisted Infrared Ship Detection Using Multi-Task Perception Networks
Jul 26, 2024Infrared ship detection (IRSD) has received increasing attention in recent years due to the robustness of infrared images to adverse weather. However, a large number of false alarms may occur in complex scenes. To address these challenges, we propose the Scene Semantic Prior-Assisted Multi-Task Perception Network (SMPISD-MTPNet), which includes three stages: scene semantic extraction, deep feature extraction, and prediction. In the scene semantic extraction stage, we employ a Scene Semantic Extractor (SSE) to guide the network by the features extracted based on expert knowledge. In the deep feature extraction stage, a backbone network is employed to extract deep features. These features are subsequently integrated by a fusion network, enhancing the detection capabilities across targets of varying sizes. In the prediction stage, we utilize the Multi-Task Perception Module, which includes the Gradient-based Module and the Scene Segmentation Module, enabling precise detection of small and dim targets within complex scenes. For the training process, we introduce the Soft Fine-tuning training strategy to suppress the distortion caused by data augmentation. Besides, due to the lack of a publicly available dataset labelled for scenes, we introduce the Infrared Ship Dataset with Scene Segmentation (IRSDSS). Finally, we evaluate the network and compare it with state-of-the-art (SOTA) methods, indicating that SMPISD-MTPNet outperforms existing approaches. The source code and dataset for this research can be accessed at https://github.com/greekinRoma/KMNDNet.
RPCANet: Deep Unfolding RPCA Based Infrared Small Target Detection
Nov 02, 2023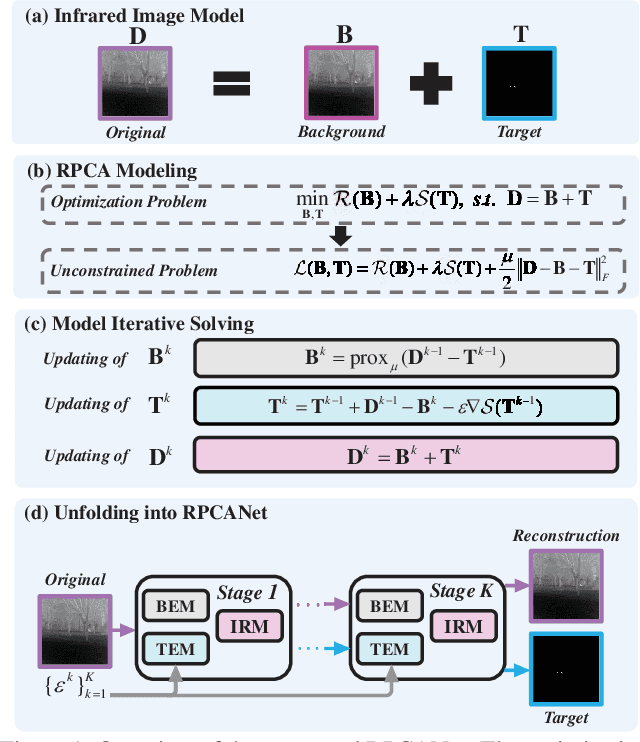
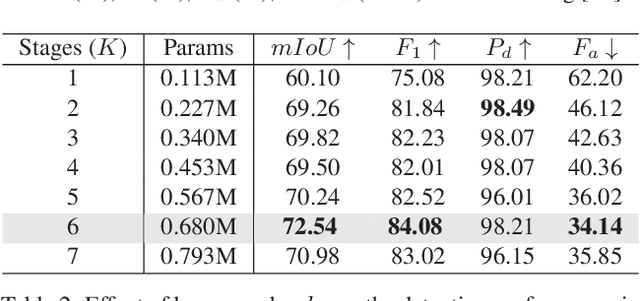
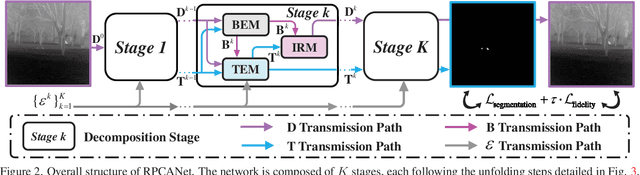
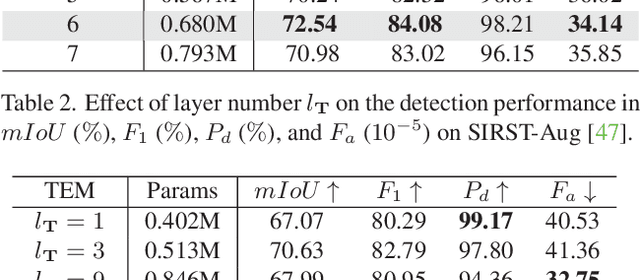
Deep learning (DL) networks have achieved remarkable performance in infrared small target detection (ISTD). However, these structures exhibit a deficiency in interpretability and are widely regarded as black boxes, as they disregard domain knowledge in ISTD. To alleviate this issue, this work proposes an interpretable deep network for detecting infrared dim targets, dubbed RPCANet. Specifically, our approach formulates the ISTD task as sparse target extraction, low-rank background estimation, and image reconstruction in a relaxed Robust Principle Component Analysis (RPCA) model. By unfolding the iterative optimization updating steps into a deep-learning framework, time-consuming and complex matrix calculations are replaced by theory-guided neural networks. RPCANet detects targets with clear interpretability and preserves the intrinsic image feature, instead of directly transforming the detection task into a matrix decomposition problem. Extensive experiments substantiate the effectiveness of our deep unfolding framework and demonstrate its trustworthy results, surpassing baseline methods in both qualitative and quantitative evaluations.