 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSPENet: Contour-Aware and Saliency Priors Embedding Network for Infrared Small Target Detection
May 15, 2025Infrared small target detection (ISTD) plays a critical role in a wide range of civilian and military applications. Existing methods suffer from deficiencies in the localization of dim targets and the perception of contour information under dense clutter environments, severely limiting their detection performance. To tackle these issues, we propose a contour-aware and saliency priors embedding network (CSPENet) for ISTD. We first design a surround-convergent prior extraction module (SCPEM) that effectively captures the intrinsic characteristic of target contour pixel gradients converging toward their center. This module concurrently extracts two collaborative priors: a boosted saliency prior for accurate target localization and multi-scale structural priors for comprehensively enriching contour detail representation. Building upon this, we propose a dual-branch priors embedding architecture (DBPEA) that establishes differentiated feature fusion pathways, embedding these two priors at optimal network positions to achieve performance enhancement. Finally, we develop an attention-guided feature enhancement module (AGFEM) to refine feature representations and improve saliency estimation accuracy. Experimental results on public datasets NUDT-SIRST, IRSTD-1k, and NUAA-SIRST demonstrate that our CSPENet outperforms other state-of-the-art methods in detection performance. The code is available at https://github.com/IDIP2025/CSPENet.
Gradient is All You Need: Gradient-Based Attention Fusion for Infrared Small Target Detection
Sep 29, 2024



Infrared small target detection (IRSTD) is widely used in civilian and military applications. However, IRSTD encounters several challenges, including the tendency for small and dim targets to be obscured by complex backgrounds. To address this issue, we propose the Gradient Network (GaNet), which aims to extract and preserve edge and gradient information of small targets. GaNet employs the Gradient Transformer (GradFormer) module, simulating central difference convolutions (CDC) to extract and integrate gradient features with deeper features. Furthermore, we propose a global feature extraction model (GFEM) that offers a comprehensive perspective to prevent the network from focusing solely on details while neglecting the background information. We compare the network with state-of-the-art (SOTA) approaches, and the results demonstrate that our method performs effectively. Our source code is available at https://github.com/greekinRoma/Gradient-Transformer.
SMPISD-MTPNet: Scene Semantic Prior-Assisted Infrared Ship Detection Using Multi-Task Perception Networks
Jul 26, 2024Infrared ship detection (IRSD) has received increasing attention in recent years due to the robustness of infrared images to adverse weather. However, a large number of false alarms may occur in complex scenes. To address these challenges, we propose the Scene Semantic Prior-Assisted Multi-Task Perception Network (SMPISD-MTPNet), which includes three stages: scene semantic extraction, deep feature extraction, and prediction. In the scene semantic extraction stage, we employ a Scene Semantic Extractor (SSE) to guide the network by the features extracted based on expert knowledge. In the deep feature extraction stage, a backbone network is employed to extract deep features. These features are subsequently integrated by a fusion network, enhancing the detection capabilities across targets of varying sizes. In the prediction stage, we utilize the Multi-Task Perception Module, which includes the Gradient-based Module and the Scene Segmentation Module, enabling precise detection of small and dim targets within complex scenes. For the training process, we introduce the Soft Fine-tuning training strategy to suppress the distortion caused by data augmentation. Besides, due to the lack of a publicly available dataset labelled for scenes, we introduce the Infrared Ship Dataset with Scene Segmentation (IRSDSS). Finally, we evaluate the network and compare it with state-of-the-art (SOTA) methods, indicating that SMPISD-MTPNet outperforms existing approaches. The source code and dataset for this research can be accessed at https://github.com/greekinRoma/KMNDNet.
VEDA: Uneven light image enhancement via a vision-based exploratory data analysis model
May 25, 2023



Uneven light image enhancement is a highly demanded task in many industrial image processing applications. Many existing enhancement methods using physical lighting models or deep-learning techniques often lead to unnatural results. This is mainly because: 1) the assumptions and priors made by the physical lighting model (PLM) based approaches are often violated in most natural scenes, and 2) the training datasets or loss functions used by deep-learning technique based methods cannot handle the various lighting scenarios in the real world well. In this paper, we propose a novel vision-based exploratory data analysis model (VEDA) for uneven light image enhancement. Our method is conceptually simple yet effective. A given image is first decomposed into a contrast image that preserves most of the perceptually important scene details, and a residual image that preserves the lighting variations. After achieving this decomposition at multiple scales using a retinal model that simulates the neuron response to light, the enhanced result at each scale can be obtained by manipulating the two images and recombining them. Then, a weighted averaging strategy based on the residual image is designed to obtain the output image by combining enhanced results at multiple scales. A similar weighting strategy can also be leveraged to reconcile noise suppression and detail preservation. Extensive experiments on different image datasets demonstrate that the proposed method can achieve competitive results in its simplicity and effectiveness compared with state-of-the-art methods. It does not require any explicit assumptions and priors about the scene imaging process, nor iteratively solving any optimization functions or any learning procedures.
AGPCNet: Attention-Guided Pyramid Context Networks for Infrared Small Target Detection
Nov 05, 2021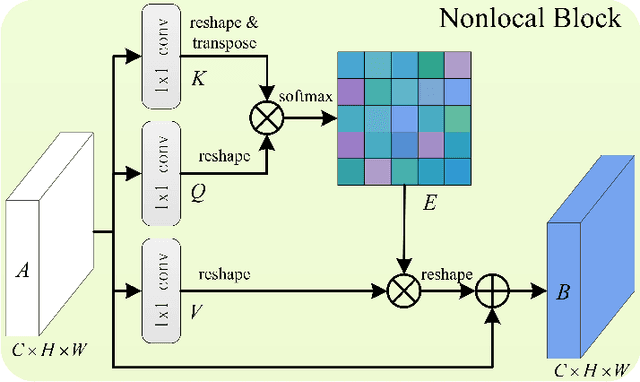
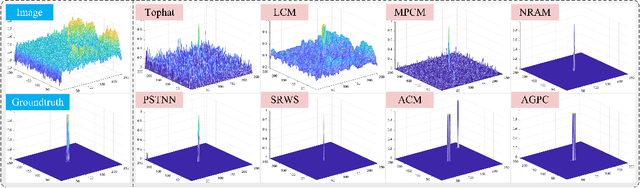
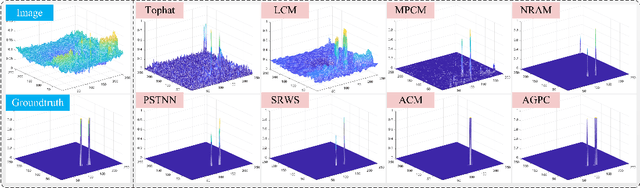
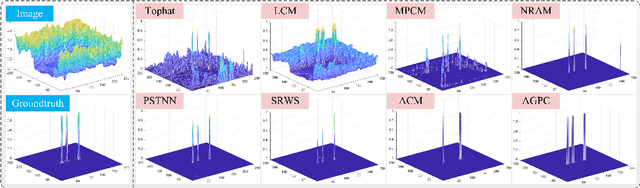
Infrared small target detection is an important problem in many fields such as earth observation, military reconnaissance, disaster relief, and has received widespread attention recently. This paper presents the Attention-Guided Pyramid Context Network (AGPCNet) algorithm. Its main components are an Attention-Guided Context Block (AGCB), a Context Pyramid Module (CPM), and an Asymmetric Fusion Module (AFM). AGCB divides the feature map into patches to compute local associations and uses Global Context Attention (GCA) to compute global associations between semantics, CPM integrates features from multi-scale AGCBs, and AFM integrates low-level and deep-level semantics from a feature-fusion perspective to enhance the utilization of features. The experimental results illustrate that AGPCNet has achieved new state-of-the-art performance on two available infrared small target datasets. The source codes are available at https://github.com/Tianfang-Zhang/AGPCNet.