 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosted Trees on a Diet: Compact Models for Resource-Constrained Devices
Oct 30, 2025Deploying machine learning models on compute-constrained devices has become a key building block of modern IoT applications. In this work, we present a compression scheme for boosted decision trees, addressing the growing need for lightweight machine learning models. Specifically, we provide techniques for training compact boosted decision tree ensembles that exhibit a reduced memory footprint by rewarding, among other things, the reuse of features and thresholds during training. Our experimental evaluation shows that models achieved the same performance with a compression ratio of 4-16x compared to LightGBM models using an adapted training process and an alternative memory layout. Once deployed, the corresponding IoT devices can operate independently of constant communication or external energy supply, and, thus, autonomously, requiring only minimal computing power and energy. This capability opens the door to a wide range of IoT applications, including remote monitoring, edge analytics, and real-time decision making in isolated or power-limited environments.
Multi-modal classification of forest biodiversity potential from 2D orthophotos and 3D airborne laser scanning point clouds
Jan 03, 2025
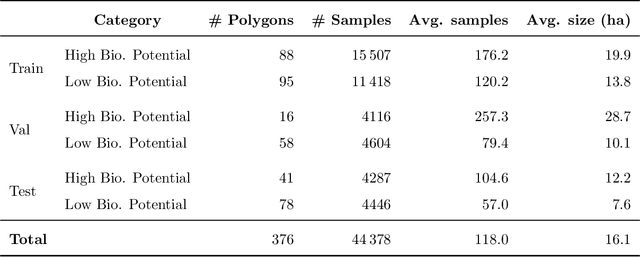
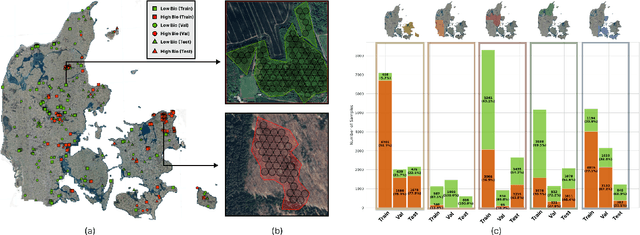
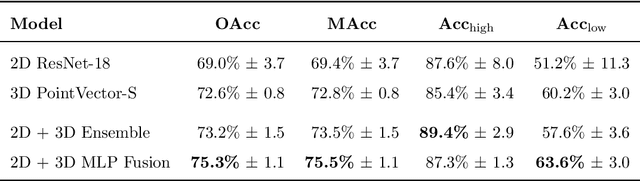
Accurate assessment of forest biodiversity is crucial for ecosystem management and conservation. While traditional field surveys provide high-quality assessments, they are labor-intensive and spatially limited. This study investigates whether deep learning-based fusion of close-range sensing data from 2D orthophotos (12.5 cm resolution) and 3D airborne laser scanning (ALS) point clouds (8 points/m^2) can enhance biodiversity assessment. We introduce the BioVista dataset, comprising 44.378 paired samples of orthophotos and ALS point clouds from temperate forests in Denmark, designed to explore multi-modal fusion approaches for biodiversity potential classification. Using deep neural networks (ResNet for orthophotos and PointVector for ALS point clouds), we investigate each data modality's ability to assess forest biodiversity potential, achieving mean accuracies of 69.4% and 72.8%, respectively. We explore two fusion approaches: a confidence-based ensemble method and a feature-level concatenation strategy, with the latter achieving a mean accuracy of 75.5%. Our results demonstrate that spectral information from orthophotos and structural information from ALS point clouds effectively complement each other in forest biodiversity assessment.
Nacala-Roof-Material: Drone Imagery for Roof Detection, Classification, and Segmentation to Support Mosquito-borne Disease Risk Assessment
Jun 07, 2024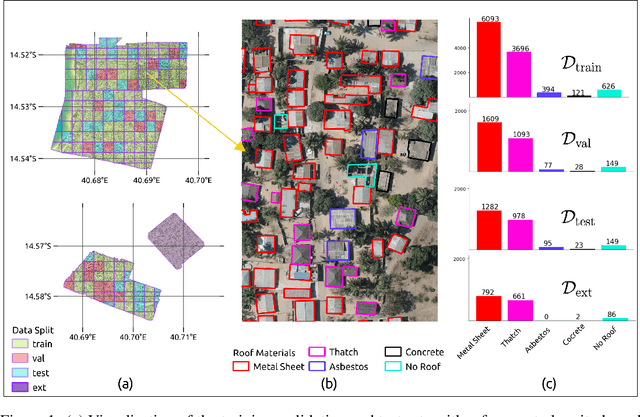
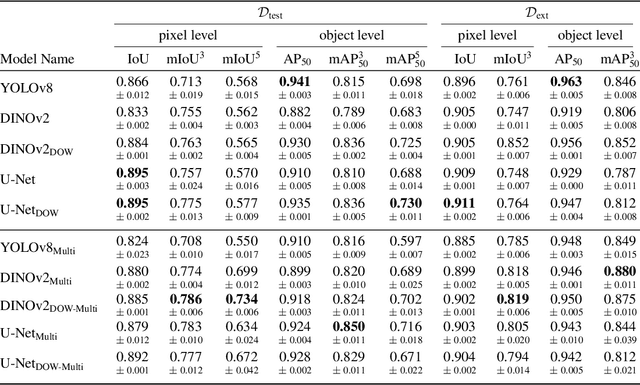
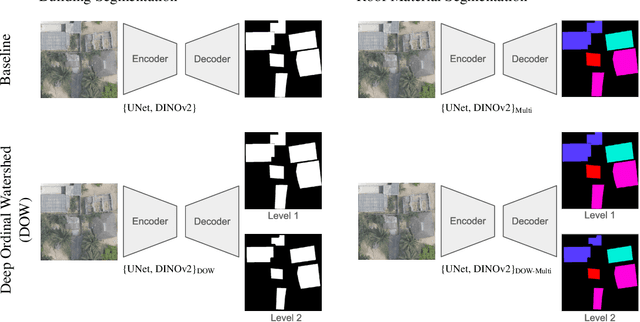

As low-quality housing and in particular certain roof characteristics are associated with an increased risk of malaria, classification of roof types based on remote sensing imagery can support the assessment of malaria risk and thereby help prevent the disease. To support research in this area, we release the Nacala-Roof-Material dataset, which contains high-resolution drone images from Mozambique with corresponding labels delineating houses and specifying their roof types. The dataset defines a multi-task computer vision problem, comprising object detection, classification, and segmentation. In addition, we benchmarked various state-of-the-art approaches on the dataset. Canonical U-Nets, YOLOv8, and a custom decoder on pretrained DINOv2 served as baselines. We show that each of the methods has its advantages but none is superior on all tasks, which highlights the potential of our dataset for future research in multi-task learning. While the tasks are closely related, accurate segmentation of objects does not necessarily imply accurate instance separation, and vice versa. We address this general issue by introducing a variant of the deep ordinal watershed (DOW) approach that additionally separates the interior of objects, allowing for improved object delineation and separation. We show that our DOW variant is a generic approach that improves the performance of both U-Net and DINOv2 backbones, leading to a better trade-off between semantic segmentation and instance segmentation.
MMEarth: Exploring Multi-Modal Pretext Tasks For Geospatial Representation Learning
May 04, 2024



The volume of unlabelled Earth observation (EO) data is huge, but many important applications lack labelled training data. However, EO data offers the unique opportunity to pair data from different modalities and sensors automatically based on geographic location and time, at virtually no human labor cost. We seize this opportunity to create a diverse multi-modal pretraining dataset at global scale. Using this new corpus of 1.2 million locations, we propose a Multi-Pretext Masked Autoencoder (MP-MAE) approach to learn general-purpose representations for optical satellite images. Our approach builds on the ConvNeXt V2 architecture, a fully convolutional masked autoencoder (MAE). Drawing upon a suite of multi-modal pretext tasks, we demonstrate that our MP-MAE approach outperforms both MAEs pretrained on ImageNet and MAEs pretrained on domain-specific satellite images. This is shown on several downstream tasks including image classification and semantic segmentation. We find that multi-modal pretraining notably improves the linear probing performance, e.g. 4pp on BigEarthNet and 16pp on So2Sat, compared to pretraining on optical satellite images only. We show that this also leads to better label and parameter efficiency which are crucial aspects in global scale applications.
Tree Counting by Bridging 3D Point Clouds with Imagery
Mar 12, 2024



Accurate and consistent methods for counting trees based on remote sensing data are needed to support sustainable forest management, assess climate change mitigation strategies, and build trust in tree carbon credits. Two-dimensional remote sensing imagery primarily shows overstory canopy, and it does not facilitate easy differentiation of individual trees in areas with a dense canopy and does not allow for easy separation of trees when the canopy is dense. We leverage the fusion of three-dimensional LiDAR measurements and 2D imagery to facilitate the accurate counting of trees. We compare a deep learning approach to counting trees in forests using 3D airborne LiDAR data and 2D imagery. The approach is compared with state-of-the-art algorithms, like operating on 3D point cloud and 2D imagery. We empirically evaluate the different methods on the NeonTreeCount data set, which we use to define a tree-counting benchmark. The experiments show that FuseCountNet yields more accurate tree counts.
Predicting urban tree cover from incomplete point labels and limited background information
Nov 20, 2023



Trees inside cities are important for the urban microclimate, contributing positively to the physical and mental health of the urban dwellers. Despite their importance, often only limited information about city trees is available. Therefore in this paper, we propose a method for mapping urban trees in high-resolution aerial imagery using limited datasets and deep learning. Deep learning has become best-practice for this task, however, existing approaches rely on large and accurately labelled training datasets, which can be difficult and expensive to obtain. However, often noisy and incomplete data may be available that can be combined and utilized to solve more difficult tasks than those datasets were intended for. This paper studies how to combine accurate point labels of urban trees along streets with crowd-sourced annotations from an open geographic database to delineate city trees in remote sensing images, a task which is challenging even for humans. To that end, we perform semantic segmentation of very high resolution aerial imagery using a fully convolutional neural network. The main challenge is that our segmentation maps are sparsely annotated and incomplete. Small areas around the point labels of the street trees coming from official and crowd-sourced data are marked as foreground class. Crowd-sourced annotations of streets, buildings, etc. define the background class. Since the tree data is incomplete, we introduce a masking to avoid class confusion. Our experiments in Hamburg, Germany, showed that the system is able to produce tree cover maps, not limited to trees along streets, without providing tree delineations. We evaluated the method on manually labelled trees and show that performance drastically deteriorates if the open geographic database is not used.
BuildSeg: A General Framework for the Segmentation of Buildings
Jan 15, 2023

Building segmentation from aerial images and 3D laser scanning (LiDAR) is a challenging task due to the diversity of backgrounds, building textures, and image quality. While current research using different types of convolutional and transformer networks has considerably improved the performance on this task, even more accurate segmentation methods for buildings are desirable for applications such as automatic mapping. In this study, we propose a general framework termed \emph{BuildSeg} employing a generic approach that can be quickly applied to segment buildings. Different data sources were combined to increase generalization performance. The approach yields good results for different data sources as shown by experiments on high-resolution multi-spectral and LiDAR imagery of cities in Norway, Denmark and France. We applied ConvNeXt and SegFormer based models on the high resolution aerial image dataset from the MapAI-competition. The methods achieved an IOU of 0.7902 and a boundary IOU of 0.6185. We used post-processing to account for the rectangular shape of the objects. This increased the boundary IOU from 0.6185 to 0.6189.
Mask-FPAN: Semi-Supervised Face Parsing in the Wild With De-Occlusion and UV GAN
Dec 18, 2022



Fine-grained semantic segmentation of a person's face and head, including facial parts and head components, has progressed a great deal in recent years. However, it remains a challenging task, whereby considering ambiguous occlusions and large pose variations are particularly difficult. To overcome these difficulties, we propose a novel framework termed Mask-FPAN. It uses a de-occlusion module that learns to parse occluded faces in a semi-supervised way. In particular, face landmark localization, face occlusionstimations, and detected head poses are taken into account. A 3D morphable face model combined with the UV GAN improves the robustness of 2D face parsing. In addition, we introduce two new datasets named FaceOccMask-HQ and CelebAMaskOcc-HQ for face paring work. The proposed Mask-FPAN framework addresses the face parsing problem in the wild and shows significant performance improvements with MIOU from 0.7353 to 0.9013 compared to the state-of-the-art on challenging face datasets.
LR-CSNet: Low-Rank Deep Unfolding Network for Image Compressive Sensing
Dec 18, 2022



Deep unfolding networks (DUNs) have proven to be a viable approach to compressive sensing (CS). In this work, we propose a DUN called low-rank CS network (LR-CSNet) for natural image CS. Real-world image patches are often well-represented by low-rank approximations. LR-CSNet exploits this property by adding a low-rank prior to the CS optimization task. We derive a corresponding iterative optimization procedure using variable splitting, which is then translated to a new DUN architecture. The architecture uses low-rank generation modules (LRGMs), which learn low-rank matrix factorizations, as well as gradient descent and proximal mappings (GDPMs), which are proposed to extract high-frequency features to refine image details. In addition, the deep features generated at each reconstruction stage in the DUN are transferred between stages to boost the performance. Our extensive experiments on three widely considered datasets demonstrate the promising performance of LR-CSNet compared to state-of-the-art methods in natural image CS.
Remember to correct the bias when using deep learning for regression!
Mar 30, 2022
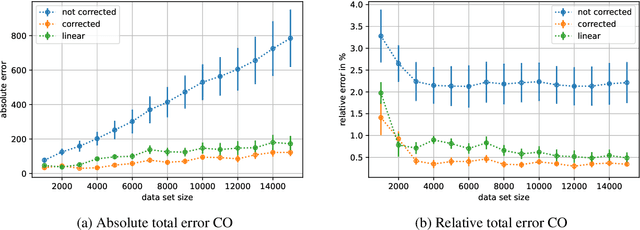


When training deep learning models for least-squares regression, we cannot expect that the training error residuals of the final model, selected after a fixed training time or based on performance on a hold-out data set, sum to zero. This can introduce a systematic error that accumulates if we are interested in the total aggregated performance over many data points. We suggest to adjust the bias of the machine learning model after training as a default postprocessing step, which efficiently solves the problem. The severeness of the error accumulation and the effectiveness of the bias correction is demonstrated in exemplary experiments.