Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember to correct the bias when using deep learning for regression!
Paper and Code
Mar 30, 2022
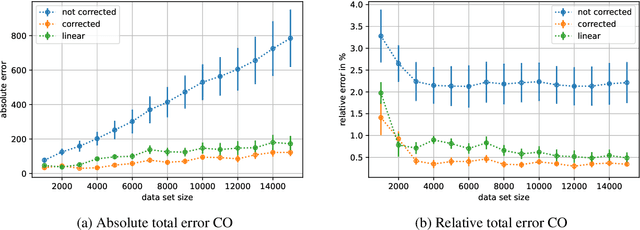


When training deep learning models for least-squares regression, we cannot expect that the training error residuals of the final model, selected after a fixed training time or based on performance on a hold-out data set, sum to zero. This can introduce a systematic error that accumulates if we are interested in the total aggregated performance over many data points. We suggest to adjust the bias of the machine learning model after training as a default postprocessing step, which efficiently solves the problem. The severeness of the error accumulation and the effectiveness of the bias correction is demonstrated in exemplary experiments.
* 8 pages, 3 figures, 2 tables
View paper on