 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMEarth-Bench: Global Model Adaptation via Multimodal Test-Time Training
Feb 06, 2026Recent research in geospatial machine learning has demonstrated that models pretrained with self-supervised learning on Earth observation data can perform well on downstream tasks with limited training data. However, most of the existing geospatial benchmark datasets have few data modalities and poor global representation, limiting the ability to evaluate multimodal pretrained models at global scales. To fill this gap, we introduce MMEarth-Bench, a collection of five new multimodal environmental tasks with 12 modalities, globally distributed data, and both in- and out-of-distribution test splits. We benchmark a diverse set of pretrained models and find that while (multimodal) pretraining tends to improve model robustness in limited data settings, geographic generalization abilities remain poor. In order to facilitate model adaptation to new downstream tasks and geographic domains, we propose a model-agnostic method for test-time training with multimodal reconstruction (TTT-MMR) that uses all the modalities available at test time as auxiliary tasks, regardless of whether a pretrained model accepts them as input. Our method improves model performance on both the random and geographic test splits, and geographic batching leads to a good trade-off between regularization and specialization during TTT. Our dataset, code, and visualization tool are linked from the project page at lgordon99.github.io/mmearth-bench.
SuperF: Neural Implicit Fields for Multi-Image Super-Resolution
Dec 09, 2025High-resolution imagery is often hindered by limitations in sensor technology, atmospheric conditions, and costs. Such challenges occur in satellite remote sensing, but also with handheld cameras, such as our smartphones. Hence, super-resolution aims to enhance the image resolution algorithmically. Since single-image super-resolution requires solving an inverse problem, such methods must exploit strong priors, e.g. learned from high-resolution training data, or be constrained by auxiliary data, e.g. by a high-resolution guide from another modality. While qualitatively pleasing, such approaches often lead to "hallucinated" structures that do not match reality. In contrast, multi-image super-resolution (MISR) aims to improve the (optical) resolution by constraining the super-resolution process with multiple views taken with sub-pixel shifts. Here, we propose SuperF, a test-time optimization approach for MISR that leverages coordinate-based neural networks, also called neural fields. Their ability to represent continuous signals with an implicit neural representation (INR) makes them an ideal fit for the MISR task. The key characteristic of our approach is to share an INR for multiple shifted low-resolution frames and to jointly optimize the frame alignment with the INR. Our approach advances related INR baselines, adopted from burst fusion for layer separation, by directly parameterizing the sub-pixel alignment as optimizable affine transformation parameters and by optimizing via a super-sampled coordinate grid that corresponds to the output resolution. Our experiments yield compelling results on simulated bursts of satellite imagery and ground-level images from handheld cameras, with upsampling factors of up to 8. A key advantage of SuperF is that this approach does not rely on any high-resolution training data.
Climate And Resource Awareness is Imperative to Achieving Sustainable AI (and Preventing a Global AI Arms Race)
Feb 27, 2025



Sustainability encompasses three key facets: economic, environmental, and social. However, the nascent discourse that is emerging on sustainable artificial intelligence (AI) has predominantly focused on the environmental sustainability of AI, often neglecting the economic and social aspects. Achieving truly sustainable AI necessitates addressing the tension between its climate awareness and its social sustainability, which hinges on equitable access to AI development resources. The concept of resource awareness advocates for broader access to the infrastructure required to develop AI, fostering equity in AI innovation. Yet, this push for improving accessibility often overlooks the environmental costs of expanding such resource usage. In this position paper, we argue that reconciling climate and resource awareness is essential to realizing the full potential of sustainable AI. We use the framework of base-superstructure to analyze how the material conditions are influencing the current AI discourse. We also introduce the Climate and Resource Aware Machine Learning (CARAML) framework to address this conflict and propose actionable recommendations spanning individual, community, industry, government, and global levels to achieve sustainable AI.
Multi-modal classification of forest biodiversity potential from 2D orthophotos and 3D airborne laser scanning point clouds
Jan 03, 2025
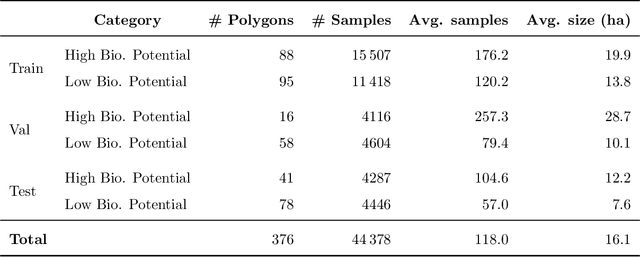
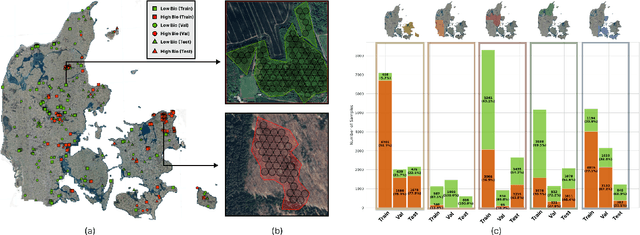
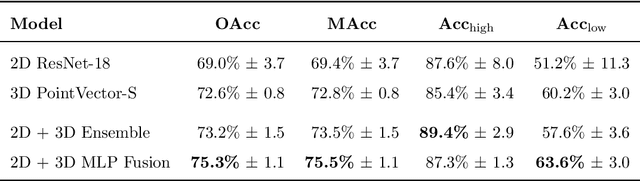
Accurate assessment of forest biodiversity is crucial for ecosystem management and conservation. While traditional field surveys provide high-quality assessments, they are labor-intensive and spatially limited. This study investigates whether deep learning-based fusion of close-range sensing data from 2D orthophotos (12.5 cm resolution) and 3D airborne laser scanning (ALS) point clouds (8 points/m^2) can enhance biodiversity assessment. We introduce the BioVista dataset, comprising 44.378 paired samples of orthophotos and ALS point clouds from temperate forests in Denmark, designed to explore multi-modal fusion approaches for biodiversity potential classification. Using deep neural networks (ResNet for orthophotos and PointVector for ALS point clouds), we investigate each data modality's ability to assess forest biodiversity potential, achieving mean accuracies of 69.4% and 72.8%, respectively. We explore two fusion approaches: a confidence-based ensemble method and a feature-level concatenation strategy, with the latter achieving a mean accuracy of 75.5%. Our results demonstrate that spectral information from orthophotos and structural information from ALS point clouds effectively complement each other in forest biodiversity assessment.
When Can Memorization Improve Fairness?
Dec 12, 2024We study to which extent additive fairness metrics (statistical parity, equal opportunity and equalized odds) can be influenced in a multi-class classification problem by memorizing a subset of the population. We give explicit expressions for the bias resulting from memorization in terms of the label and group membership distribution of the memorized dataset and the classifier bias on the unmemorized dataset. We also characterize the memorized datasets that eliminate the bias for all three metrics considered. Finally we provide upper and lower bounds on the total probability mass in the memorized dataset that is necessary for the complete elimination of these biases.
Bayesian vs. PAC-Bayesian Deep Neural Network Ensembles
Jun 08, 2024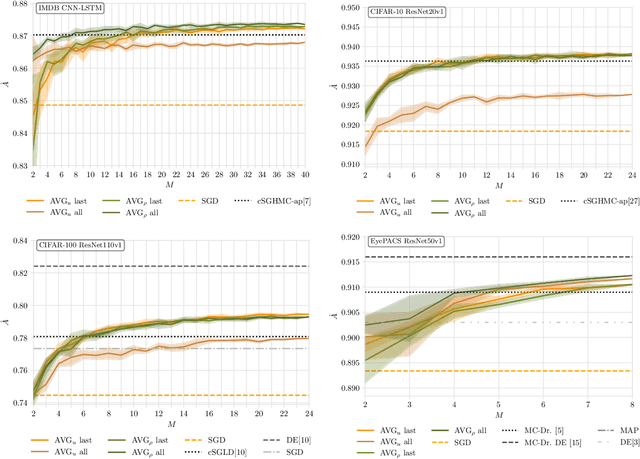
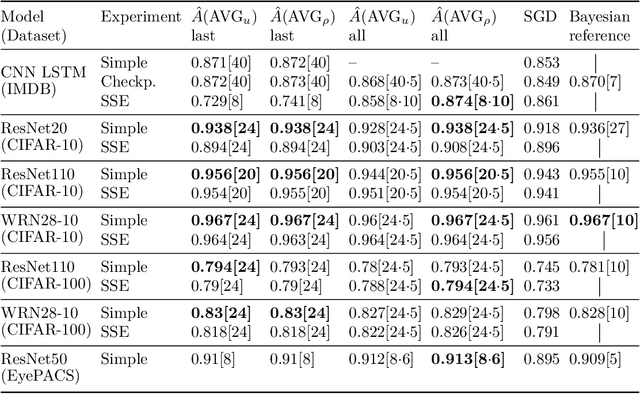
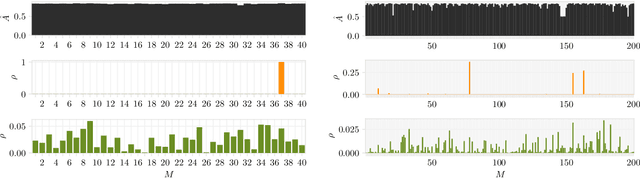
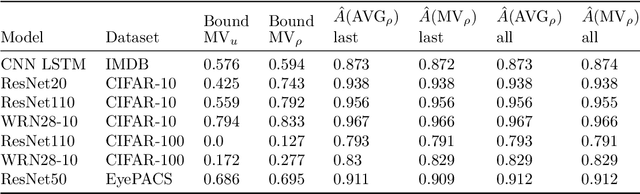
Bayesian neural networks address epistemic uncertainty by learning a posterior distribution over model parameters. Sampling and weighting networks according to this posterior yields an ensemble model referred to as Bayes ensemble. Ensembles of neural networks (deep ensembles) can profit from the cancellation of errors effect: Errors by ensemble members may average out and the deep ensemble achieves better predictive performance than each individual network. We argue that neither the sampling nor the weighting in a Bayes ensemble are particularly well-suited for increasing generalization performance, as they do not support the cancellation of errors effect, which is evident in the limit from the Bernstein-von~Mises theorem for misspecified models. In contrast, a weighted average of models where the weights are optimized by minimizing a PAC-Bayesian generalization bound can improve generalization performance. This requires that the optimization takes correlations between models into account, which can be achieved by minimizing the tandem loss at the cost that hold-out data for estimating error correlations need to be available. The PAC-Bayesian weighting increases the robustness against correlated models and models with lower performance in an ensemble. This allows us to safely add several models from the same learning process to an ensemble, instead of using early-stopping for selecting a single weight configuration. Our study presents empirical results supporting these conceptual considerations on four different classification datasets. We show that state-of-the-art Bayes ensembles from the literature, despite being computationally demanding, do not improve over simple uniformly weighted deep ensembles and cannot match the performance of deep ensembles weighted by optimizing the tandem loss, which additionally come with non-vacuous generalization guarantees.
Nacala-Roof-Material: Drone Imagery for Roof Detection, Classification, and Segmentation to Support Mosquito-borne Disease Risk Assessment
Jun 07, 2024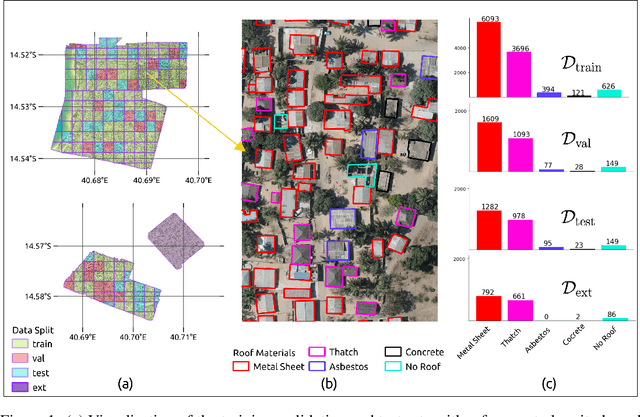
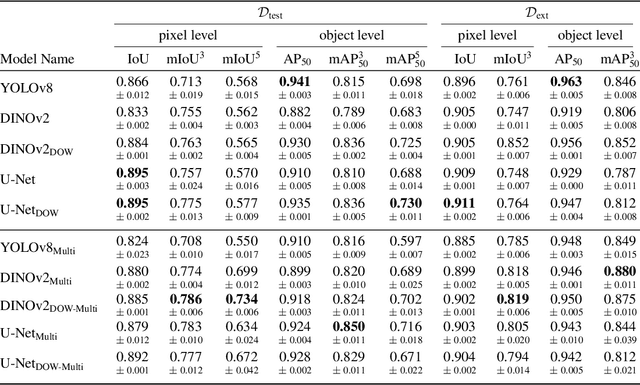
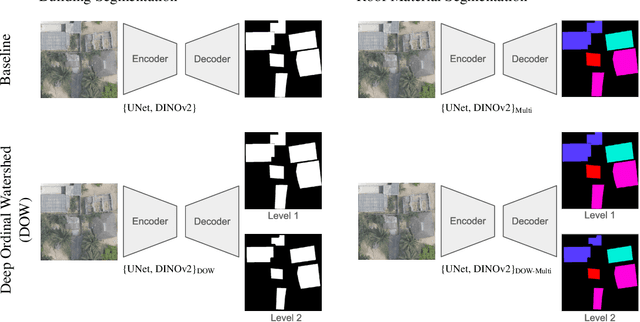

As low-quality housing and in particular certain roof characteristics are associated with an increased risk of malaria, classification of roof types based on remote sensing imagery can support the assessment of malaria risk and thereby help prevent the disease. To support research in this area, we release the Nacala-Roof-Material dataset, which contains high-resolution drone images from Mozambique with corresponding labels delineating houses and specifying their roof types. The dataset defines a multi-task computer vision problem, comprising object detection, classification, and segmentation. In addition, we benchmarked various state-of-the-art approaches on the dataset. Canonical U-Nets, YOLOv8, and a custom decoder on pretrained DINOv2 served as baselines. We show that each of the methods has its advantages but none is superior on all tasks, which highlights the potential of our dataset for future research in multi-task learning. While the tasks are closely related, accurate segmentation of objects does not necessarily imply accurate instance separation, and vice versa. We address this general issue by introducing a variant of the deep ordinal watershed (DOW) approach that additionally separates the interior of objects, allowing for improved object delineation and separation. We show that our DOW variant is a generic approach that improves the performance of both U-Net and DINOv2 backbones, leading to a better trade-off between semantic segmentation and instance segmentation.
BMRS: Bayesian Model Reduction for Structured Pruning
Jun 03, 2024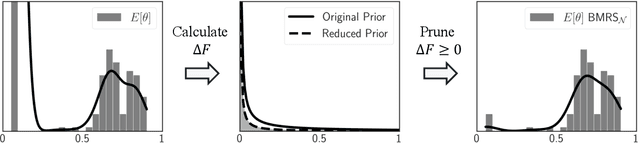



Modern neural networks are often massively overparameterized leading to high compute costs during training and at inference. One effective method to improve both the compute and energy efficiency of neural networks while maintaining good performance is structured pruning, where full network structures (e.g. neurons or convolutional filters) that have limited impact on the model output are removed. In this work, we propose Bayesian Model Reduction for Structured pruning (BMRS), a fully end-to-end Bayesian method of structured pruning. BMRS is based on two recent methods: Bayesian structured pruning with multiplicative noise, and Bayesian model reduction (BMR), a method which allows efficient comparison of Bayesian models under a change in prior. We present two realizations of BMRS derived from different priors which yield different structured pruning characteristics: 1) BMRS_N with the truncated log-normal prior, which offers reliable compression rates and accuracy without the need for tuning any thresholds and 2) BMRS_U with the truncated log-uniform prior that can achieve more aggressive compression based on the boundaries of truncation. Overall, we find that BMRS offers a theoretically grounded approach to structured pruning of neural networks yielding both high compression rates and accuracy. Experiments on multiple datasets and neural networks of varying complexity showed that the two BMRS methods offer a competitive performance-efficiency trade-off compared to other pruning methods.
MMEarth: Exploring Multi-Modal Pretext Tasks For Geospatial Representation Learning
May 04, 2024



The volume of unlabelled Earth observation (EO) data is huge, but many important applications lack labelled training data. However, EO data offers the unique opportunity to pair data from different modalities and sensors automatically based on geographic location and time, at virtually no human labor cost. We seize this opportunity to create a diverse multi-modal pretraining dataset at global scale. Using this new corpus of 1.2 million locations, we propose a Multi-Pretext Masked Autoencoder (MP-MAE) approach to learn general-purpose representations for optical satellite images. Our approach builds on the ConvNeXt V2 architecture, a fully convolutional masked autoencoder (MAE). Drawing upon a suite of multi-modal pretext tasks, we demonstrate that our MP-MAE approach outperforms both MAEs pretrained on ImageNet and MAEs pretrained on domain-specific satellite images. This is shown on several downstream tasks including image classification and semantic segmentation. We find that multi-modal pretraining notably improves the linear probing performance, e.g. 4pp on BigEarthNet and 16pp on So2Sat, compared to pretraining on optical satellite images only. We show that this also leads to better label and parameter efficiency which are crucial aspects in global scale applications.
Building an AI Support Tool for Real-time Ulcerative Colitis Diagnosis
Apr 10, 2024Ulcerative Colitis (UC) is a chronic inflammatory bowel disease decreasing life quality through symptoms such as bloody diarrhoea and abdominal pain. Endoscopy is a cornerstone of diagnosis and monitoring of UC. The Mayo endoscopic subscore (MES) index is the standard for measuring UC severity during endoscopic evaluation. However, the MES is subject to high inter-observer variability leading to misdiagnosis and suboptimal treatment. We propose using a machine-learning based MES classification system to support the endoscopic process and to mitigate the observer-variability. The system runs real-time in the clinic and augments doctors' decision-making during the endoscopy. This project report outlines the process of designing, creating and evaluating our system. We describe our initial evaluation, which is a combination of a standard non-clinical model test and a first clinical test of the system on a real patient.