 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairQuant: Fairness-Aware Mixed-Precision Quantization for Medical Image Classification
Feb 26, 2026Compressing neural networks by quantizing model parameters offers useful trade-off between performance and efficiency. Methods like quantization-aware training and post-training quantization strive to maintain the downstream performance of compressed models compared to the full precision models. However, these techniques do not explicitly consider the impact on algorithmic fairness. In this work, we study fairness-aware mixed-precision quantization schemes for medical image classification under explicit bit budgets. We introduce FairQuant, a framework that combines group-aware importance analysis, budgeted mixed-precision allocation, and a learnable Bit-Aware Quantization (BAQ) mode that jointly optimizes weights and per-unit bit allocations under bitrate and fairness regularization. We evaluate the method on Fitzpatrick17k and ISIC2019 across ResNet18/50, DeiT-Tiny, and TinyViT. Results show that FairQuant configurations with average precision near 4-6 bits recover much of the Uniform 8-bit accuracy while improving worst-group performance relative to Uniform 4- and 8-bit baselines, with comparable fairness metrics under shared budgets.
Stop Preaching and Start Practising Data Frugality for Responsible Development of AI
Feb 23, 2026This position paper argues that the machine learning community must move from preaching to practising data frugality for responsible artificial intelligence (AI) development. For long, progress has been equated with ever-larger datasets, driving remarkable advances but now yielding increasingly diminishing performance gains alongside rising energy use and carbon emissions. While awareness of data frugal approaches has grown, their adoption has remained rhetorical, and data scaling continues to dominate development practice. We argue that this gap between preach and practice must be closed, as continued data scaling entails substantial and under-accounted environmental impacts. To ground our position, we provide indicative estimates of the energy use and carbon emissions associated with the downstream use of ImageNet-1K. We then present empirical evidence that data frugality is both practical and beneficial, demonstrating that coreset-based subset selection can substantially reduce training energy consumption with little loss in accuracy, while also mitigating dataset bias. Finally, we outline actionable recommendations for moving data frugality from rhetorical preach to concrete practice for responsible development of AI.
Algorithmic Simplification of Neural Networks with Mosaic-of-Motifs
Feb 16, 2026Large-scale deep learning models are well-suited for compression. Methods like pruning, quantization, and knowledge distillation have been used to achieve massive reductions in the number of model parameters, with marginal performance drops across a variety of architectures and tasks. This raises the central question: \emph{Why are deep neural networks suited for compression?} In this work, we take up the perspective of algorithmic complexity to explain this behavior. We hypothesize that the parameters of trained models have more structure and, hence, exhibit lower algorithmic complexity compared to the weights at (random) initialization. Furthermore, that model compression methods harness this reduced algorithmic complexity to compress models. Although an unconstrained parameterization of model weights, $\mathbf{w} \in \mathbb{R}^n$, can represent arbitrary weight assignments, the solutions found during training exhibit repeatability and structure, making them algorithmically simpler than a generic program. To this end, we formalize the Kolmogorov complexity of $\mathbf{w}$ by $\mathcal{K}(\mathbf{w})$. We introduce a constrained parameterization $\widehat{\mathbf{w}}$, that partitions parameters into blocks of size $s$, and restricts each block to be selected from a set of $k$ reusable motifs, specified by a reuse pattern (or mosaic). The resulting method, $\textit{Mosaic-of-Motifs}$ (MoMos), yields algorithmically simpler model parameterization compared to unconstrained models. Empirical evidence from multiple experiments shows that the algorithmic complexity of neural networks, measured using approximations to Kolmogorov complexity, can be reduced during training. This results in models that perform comparably with unconstrained models while being algorithmically simpler.
CoDeQ: End-to-End Joint Model Compression with Dead-Zone Quantizer for High-Sparsity and Low-Precision Networks
Dec 15, 2025While joint pruning--quantization is theoretically superior to sequential application, current joint methods rely on auxiliary procedures outside the training loop for finding compression parameters. This reliance adds engineering complexity and hyperparameter tuning, while also lacking a direct data-driven gradient signal, which might result in sub-optimal compression. In this paper, we introduce CoDeQ, a simple, fully differentiable method for joint pruning--quantization. Our approach builds on a key observation: the dead-zone of a scalar quantizer is equivalent to magnitude pruning, and can be used to induce sparsity directly within the quantization operator. Concretely, we parameterize the dead-zone width and learn it via backpropagation, alongside the quantization parameters. This design provides explicit control of sparsity, regularized by a single global hyperparameter, while decoupling sparsity selection from bit-width selection. The result is a method for Compression with Dead-zone Quantizer (CoDeQ) that supports both fixed-precision and mixed-precision quantization (controlled by an optional second hyperparameter). It simultaneously determines the sparsity pattern and quantization parameters in a single end-to-end optimization. Consequently, CoDeQ does not require any auxiliary procedures, making the method architecture-agnostic and straightforward to implement. On ImageNet with ResNet-18, CoDeQ reduces bit operations to ~5% while maintaining close to full precision accuracy in both fixed and mixed-precision regimes.
The HCI GenAI CO2ST Calculator: A Tool for Calculating the Carbon Footprint of Generative AI Use in Human-Computer Interaction Research
Apr 01, 2025
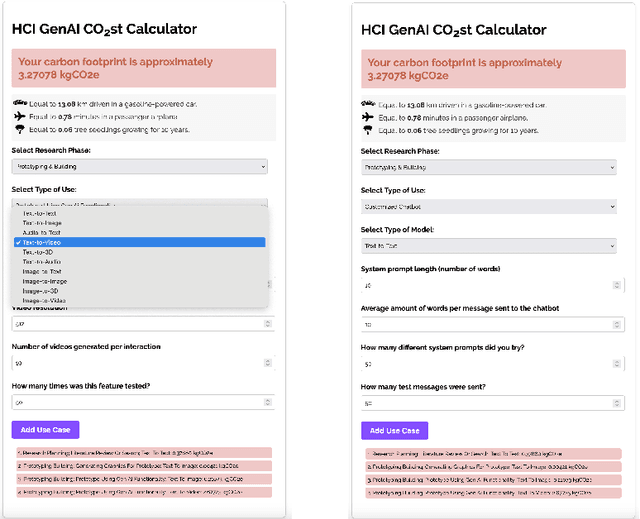
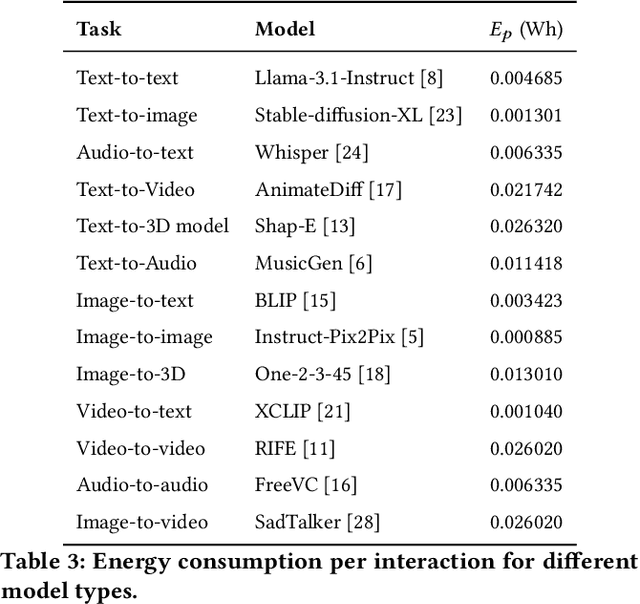
Increased usage of generative AI (GenAI) in Human-Computer Interaction (HCI) research induces a climate impact from carbon emissions due to energy consumption of the hardware used to develop and run GenAI models and systems. The exact energy usage and and subsequent carbon emissions are difficult to estimate in HCI research because HCI researchers most often use cloud-based services where the hardware and its energy consumption are hidden from plain view. The HCI GenAI CO2ST Calculator is a tool designed specifically for the HCI research pipeline, to help researchers estimate the energy consumption and carbon footprint of using generative AI in their research, either a priori (allowing for mitigation strategies or experimental redesign) or post hoc (allowing for transparent documentation of carbon footprint in written reports of the research).
Climate And Resource Awareness is Imperative to Achieving Sustainable AI (and Preventing a Global AI Arms Race)
Feb 27, 2025



Sustainability encompasses three key facets: economic, environmental, and social. However, the nascent discourse that is emerging on sustainable artificial intelligence (AI) has predominantly focused on the environmental sustainability of AI, often neglecting the economic and social aspects. Achieving truly sustainable AI necessitates addressing the tension between its climate awareness and its social sustainability, which hinges on equitable access to AI development resources. The concept of resource awareness advocates for broader access to the infrastructure required to develop AI, fostering equity in AI innovation. Yet, this push for improving accessibility often overlooks the environmental costs of expanding such resource usage. In this position paper, we argue that reconciling climate and resource awareness is essential to realizing the full potential of sustainable AI. We use the framework of base-superstructure to analyze how the material conditions are influencing the current AI discourse. We also introduce the Climate and Resource Aware Machine Learning (CARAML) framework to address this conflict and propose actionable recommendations spanning individual, community, industry, government, and global levels to achieve sustainable AI.
deCIFer: Crystal Structure Prediction from Powder Diffraction Data using Autoregressive Language Models
Feb 04, 2025Novel materials drive progress across applications from energy storage to electronics. Automated characterization of material structures with machine learning methods offers a promising strategy for accelerating this key step in material design. In this work, we introduce an autoregressive language model that performs crystal structure prediction (CSP) from powder diffraction data. The presented model, deCIFer, generates crystal structures in the widely used Crystallographic Information File (CIF) format and can be conditioned on powder X-ray diffraction (PXRD) data. Unlike earlier works that primarily rely on high-level descriptors like composition, deCIFer performs CSP from diffraction data. We train deCIFer on nearly 2.3M unique crystal structures and validate on diverse sets of PXRD patterns for characterizing challenging inorganic crystal systems. Qualitative and quantitative assessments using the residual weighted profile and Wasserstein distance show that deCIFer produces structures that more accurately match the target diffraction data when conditioned, compared to the unconditioned case. Notably, deCIFer can achieve a 94% match rate on unseen data. deCIFer bridges experimental diffraction data with computational CSP, lending itself as a powerful tool for crystal structure characterization and accelerating materials discovery.
When Can Memorization Improve Fairness?
Dec 12, 2024We study to which extent additive fairness metrics (statistical parity, equal opportunity and equalized odds) can be influenced in a multi-class classification problem by memorizing a subset of the population. We give explicit expressions for the bias resulting from memorization in terms of the label and group membership distribution of the memorized dataset and the classifier bias on the unmemorized dataset. We also characterize the memorized datasets that eliminate the bias for all three metrics considered. Finally we provide upper and lower bounds on the total probability mass in the memorized dataset that is necessary for the complete elimination of these biases.
BMRS: Bayesian Model Reduction for Structured Pruning
Jun 03, 2024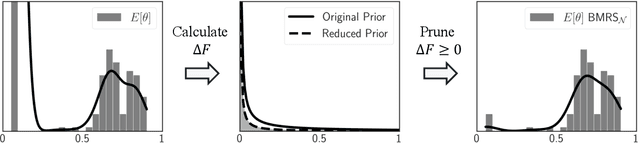



Modern neural networks are often massively overparameterized leading to high compute costs during training and at inference. One effective method to improve both the compute and energy efficiency of neural networks while maintaining good performance is structured pruning, where full network structures (e.g. neurons or convolutional filters) that have limited impact on the model output are removed. In this work, we propose Bayesian Model Reduction for Structured pruning (BMRS), a fully end-to-end Bayesian method of structured pruning. BMRS is based on two recent methods: Bayesian structured pruning with multiplicative noise, and Bayesian model reduction (BMR), a method which allows efficient comparison of Bayesian models under a change in prior. We present two realizations of BMRS derived from different priors which yield different structured pruning characteristics: 1) BMRS_N with the truncated log-normal prior, which offers reliable compression rates and accuracy without the need for tuning any thresholds and 2) BMRS_U with the truncated log-uniform prior that can achieve more aggressive compression based on the boundaries of truncation. Overall, we find that BMRS offers a theoretically grounded approach to structured pruning of neural networks yielding both high compression rates and accuracy. Experiments on multiple datasets and neural networks of varying complexity showed that the two BMRS methods offer a competitive performance-efficiency trade-off compared to other pruning methods.
Equity through Access: A Case for Small-scale Deep Learning
Mar 19, 2024



The recent advances in deep learning (DL) have been accelerated by access to large-scale data and compute. These large-scale resources have been used to train progressively larger models which are resource intensive in terms of compute, data, energy, and carbon emissions. These costs are becoming a new type of entry barrier to researchers and practitioners with limited access to resources at such scale, particularly in the Global South. In this work, we take a comprehensive look at the landscape of existing DL models for vision tasks and demonstrate their usefulness in settings where resources are limited. To account for the resource consumption of DL models, we introduce a novel measure to estimate the performance per resource unit, which we call the PePR score. Using a diverse family of 131 unique DL architectures (spanning 1M to 130M trainable parameters) and three medical image datasets, we capture trends about the performance-resource trade-offs. In applications like medical image analysis, we argue that small-scale, specialized models are better than striving for large-scale models. Furthermore, we show that using pretrained models can significantly reduce the computational resources and data required. We hope this work will encourage the community to focus on improving AI equity by developing methods and models with smaller resource footprints.