 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARMA: Collocation-Aware Resource Manager with GPU Memory Estimator
Aug 26, 2025



Studies conducted on enterprise-scale infrastructure have shown that GPUs -- the core computational resource for deep learning (DL) training -- are often significantly underutilized. DL task collocation on GPUs is an opportunity to address this challenge. However, it may result in (1) out-of-memory crashes for the subsequently arriving task and (2) slowdowns for all tasks sharing the GPU due to resource interference. The former challenge poses a threat to robustness, while the latter affects the quality of service and energy efficiency. We propose CARMA, a server-scale task-level collocation-aware resource management system that handles both collocation challenges. CARMA encompasses GPUMemNet, a novel ML-based GPU memory estimator framework for DL training tasks, to minimize out-of-memory errors and introduces collocation policies that cap GPU utilization to minimize interference. Furthermore, CARMA introduces a recovery method to ensure robust restart of tasks that crash. Our evaluation on traces modeled after real-world DL training task traces shows that CARMA increases the GPU utilization over time by 39.3\%, decreases the end-to-end execution time by $\sim$26.7\%, and reduces the GPU energy use by $\sim$14.2\%.
Climate And Resource Awareness is Imperative to Achieving Sustainable AI (and Preventing a Global AI Arms Race)
Feb 27, 2025



Sustainability encompasses three key facets: economic, environmental, and social. However, the nascent discourse that is emerging on sustainable artificial intelligence (AI) has predominantly focused on the environmental sustainability of AI, often neglecting the economic and social aspects. Achieving truly sustainable AI necessitates addressing the tension between its climate awareness and its social sustainability, which hinges on equitable access to AI development resources. The concept of resource awareness advocates for broader access to the infrastructure required to develop AI, fostering equity in AI innovation. Yet, this push for improving accessibility often overlooks the environmental costs of expanding such resource usage. In this position paper, we argue that reconciling climate and resource awareness is essential to realizing the full potential of sustainable AI. We use the framework of base-superstructure to analyze how the material conditions are influencing the current AI discourse. We also introduce the Climate and Resource Aware Machine Learning (CARAML) framework to address this conflict and propose actionable recommendations spanning individual, community, industry, government, and global levels to achieve sustainable AI.
TensorSocket: Shared Data Loading for Deep Learning Training
Sep 27, 2024

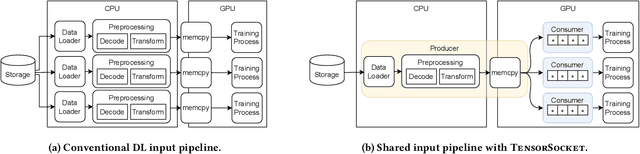
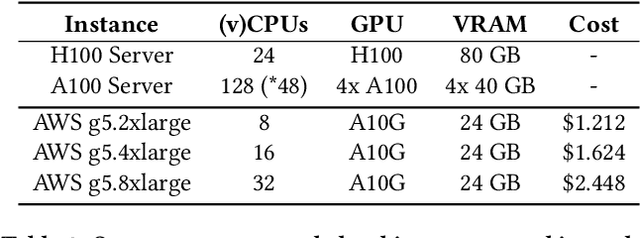
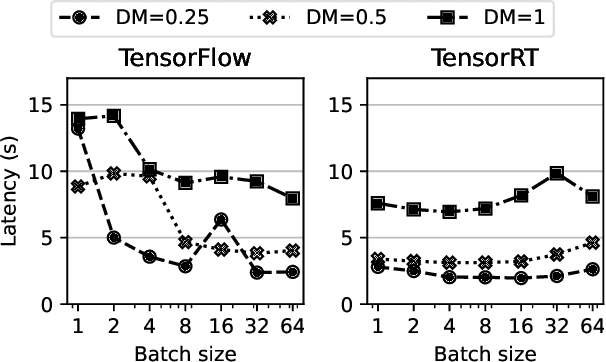
Training deep learning models is a repetitive and resource-intensive process. Data scientists often train several models before landing on set of parameters (e.g., hyper-parameter tuning), model architecture (e.g., neural architecture search), among other things that yields the highest accuracy. The computational efficiency of these training tasks depends highly on how well we can supply the training process with training data. The repetitive nature of these tasks results in the same data processing pipelines running over and over exacerbating the need for and costs of computational resources. In this paper, we present Tensorsocket to reduce the computational needs of deep learning training by enabling simultaneous training processes to share the same data loader. Tensorsocket mitigates CPU-side bottlenecks in cases where the collocated training workloads have high throughput on GPU, but are held back by lower data-loading throughput on CPU. Tensorsocket achieves this by reducing redundant computations across collocated training processes and leveraging modern GPU-GPU interconnects. We demonstrate the hardware- and pipeline-agnostic nature of Tensorsocket and evaluate it using a variety of training scenarios. Our evaluation shows that Tensorsocket enables scenarios that are infeasible without data sharing, increases training throughput by up to $100\%$, and when utilizing cloud instances, Tensorsocket achieves cost savings of $50\%$ by reducing the hardware resource needs on the CPU side. Furthermore, Tensorsocket outperforms the state-of-the-art solutions for shared data loading such as CoorDL and Joader. It is easier to use, maintain, and deploy, and either achieves higher or matches the throughput of other solutions while requiring less CPU resources.
We are Going to the Space -- Part 1: Which device to deploy in a satellite?
Jan 12, 2023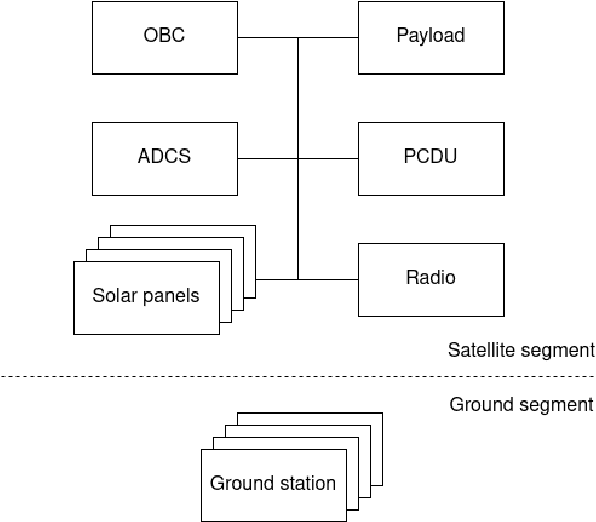


The shrinkage in sizes of components that make up satellites led to wider and low cost availability of satellites. As a result, there has been an advent of smaller organizations having the ability to deploy satellites with a variety of data-intensive applications to run on them. One popular application is image analysis to detect, for example, land, ice, clouds, etc. However, the resource-constrained nature of the devices deployed in satellites creates additional challenges for this resource-intensive application. In this paper, we investigate the performance of a variety of edge devices for deep-learning-based image processing in space. Our goal is to determine the devices that satisfy the latency and power constraints of satellites while achieving reasonably accurate results. Our results demonstrate that hardware accelerators (TPUs, GPUs) are necessary to reach the latency requirements. On the other hand, state-of-the-art edge devices with GPUs could have a high power draw, making them unsuitable for deployment on a satellite.
Deep Learning Training on Multi-Instance GPUs
Sep 13, 2022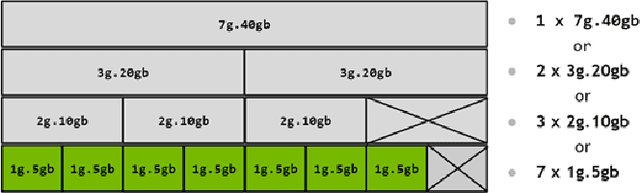
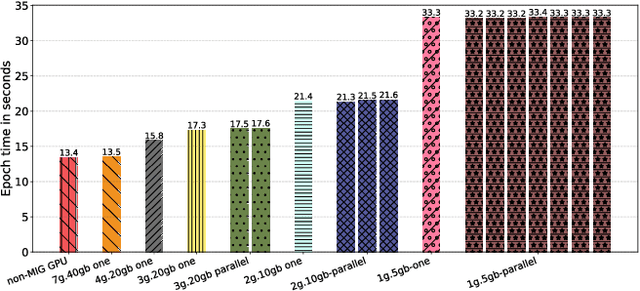
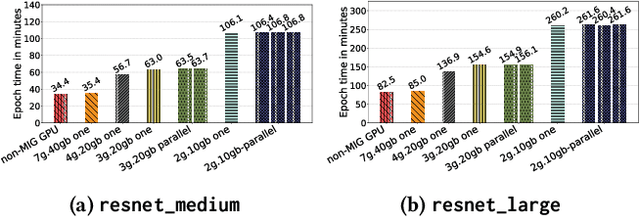
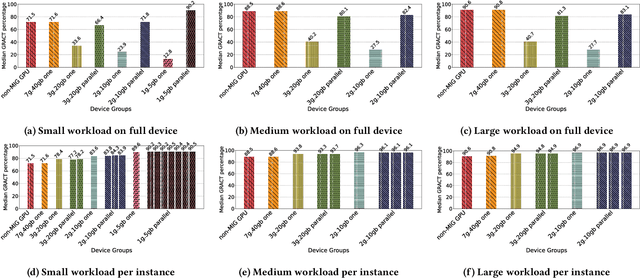
Deep learning training is an expensive process that extensively uses GPUs, but not all model training saturates the modern powerful GPUs. Multi-Instance GPU (MIG) is a new technology introduced by NVIDIA that can partition a GPU to better fit workloads that don't require all the memory and compute resources of a full GPU. In this paper, we examine the performance of a MIG-enabled A100 GPU under deep learning workloads of three sizes focusing on image recognition training with ResNet models. We investigate the behavior of these workloads when running in isolation on a variety of MIG instances allowed by the GPU in addition to running them in parallel on homogeneous instances co-located on the same GPU. Our results demonstrate that employing MIG can significantly improve the utilization of the GPU when the workload is too small to utilize the whole GPU in isolation. By training multiple small models in parallel, more work can be performed by the GPU per unit of time, despite the increase in time-per-epoch, leading to $\sim$3 times the throughput. In contrast, for medium and large-sized workloads, which already utilize the whole GPU well on their own, MIG only provides marginal performance improvements. Nevertheless, we observe that training models in parallel using separate MIG partitions does not exhibit interference underlining the value of having a functionality like MIG on modern GPUs.
Micro-architectural Analysis of a Learned Index
Sep 17, 2021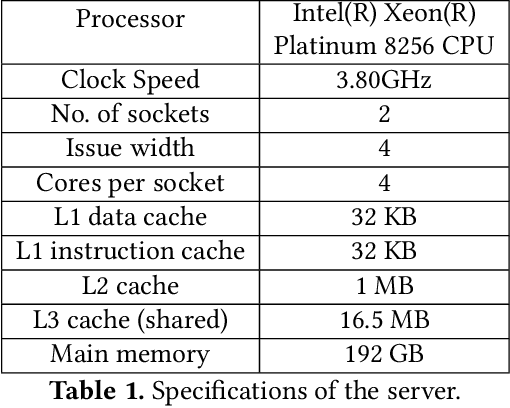
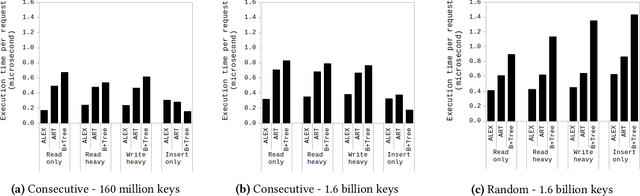
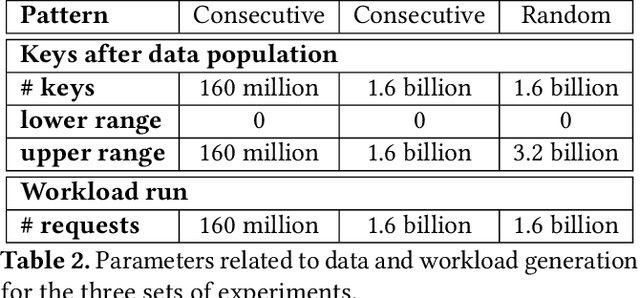
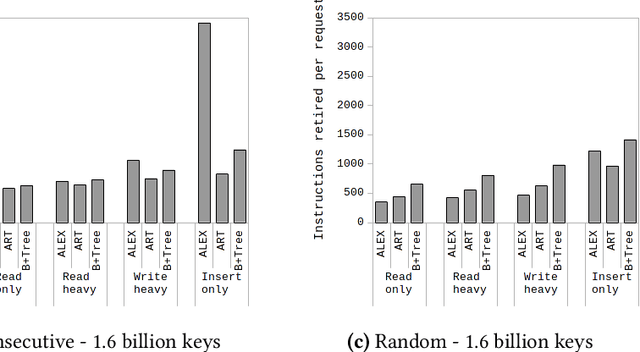
Since the publication of The Case for Learned Index Structures in 2018, there has been a rise in research that focuses on learned indexes for different domains and with different functionalities. While the effectiveness of learned indexes as an alternative to traditional index structures such as B+Trees have already been demonstrated by several studies, previous work tend to focus on higher-level performance metrics such as throughput and index size. In this paper, our goal is to dig deeper and investigate how learned indexes behave at a micro-architectural level compared to traditional indexes. More specifically, we focus on previously proposed learned index structure ALEX, which is a tree-based in-memory index structure that consists of a hierarchy of machine learned models. Unlike the original proposal for learned indexes, ALEX is designed from the ground up to allow updates and inserts. Therefore, it enables more dynamic workloads using learned indexes. In this work, we perform a micro-architectural analysis of ALEX and compare its behavior to the tree-based index structures that are not based on learned models, i.e., ART and B+Tree. Our results show that ALEX is bound by memory stalls, mainly stalls due to data misses from the last-level cache. Compared to ART and B+Tree, ALEX exhibits fewer stalls and a lower cycles-per-instruction value across different workloads. On the other hand, the amount of instructions required to handle out-of-bound inserts in ALEX can increase the instructions needed per request significantly (10X) for write-heavy workloads. However, the micro-architectural behavior shows that this increase in the instruction footprint exhibit high instruction-level parallelism, and, therefore, does not negatively impact the overall execution time.